memanto-locomo-results
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/moorcheh/memanto-locomo-results
下载链接
链接失效反馈官方服务:
资源简介:
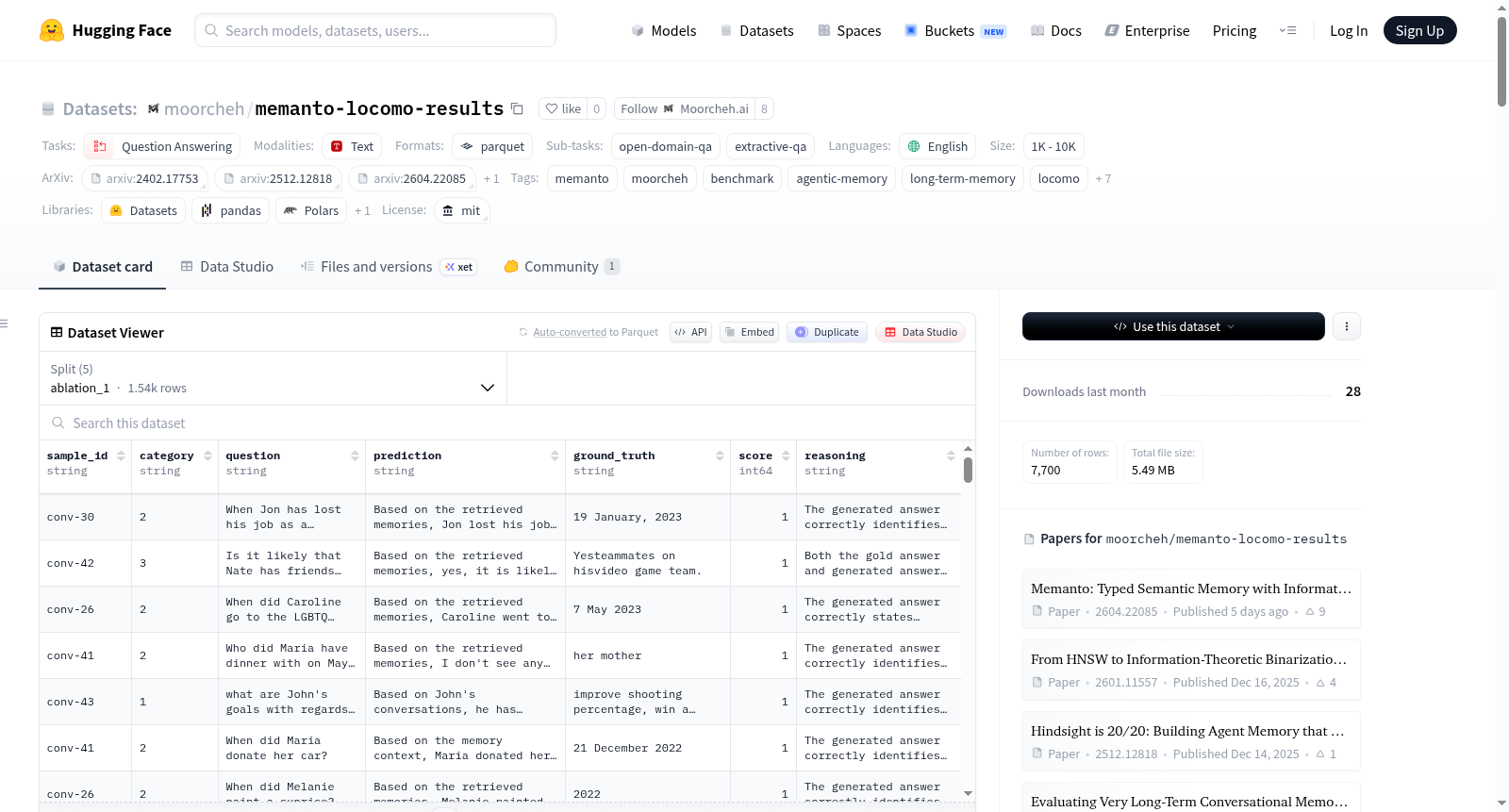
Memanto LoCoMo Benchmark Results 数据集包含了 Memanto 在 LoCoMo(长时会话记忆基准测试)上的完整每问题评估结果,涵盖了渐进式消融研究的五个阶段。该数据集伴随研究论文《Memanto: Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents》发布。数据集用于评估 Memanto 在长时会话记忆任务中的表现,包括单跳、多跳、开放域和时间推理四个推理类别。每个数据行代表一个评估问题,包含样本ID、问题类别、问题文本、预测答案、真实答案、正确性分数(0或1)以及评分理由(部分阶段提供)。数据集分为五个消融阶段,分别对应不同的配置和性能表现,其中第五阶段达到了87.1%的整体准确率。数据集适用于问答任务,特别是开放域问答和抽取式问答,可用于研究长期记忆、信息检索和对话系统。
创建时间:
2026-04-25
原始信息汇总
Memanto — LoCoMo 基准测试结果数据集概述
数据集基本信息
- 数据集名称: Memanto LoCoMo Benchmark Results
- 语言: 英语
- 许可证: MIT
- 数据集大小: 1,000 — 10,000 条记录
- 任务类别: 问答(开放域问答、抽取式问答)
- 数据来源: 原始生成(机器生成)
- 相关论文: arXiv:2604.22085
数据集内容
本数据集包含 Memanto 模型在 LoCoMo(长程对话记忆基准测试)上的逐问题完整评估结果,涵盖五个渐进式消融研究阶段。每个阶段对应一个独立的数据分割(split)。
LoCoMo 基准测试的四类推理问题
| 类别 | 描述 |
|---|---|
| Single-Hop(单跳) | 可从单一记忆事实回答的问题 |
| Multi-Hop(多跳) | 需要综合多个事实才能回答的问题 |
| Open Domain(开放域) | 基于对话历史的开放式问题 |
| Temporal(时间) | 需要时间推理和顺序判断的问题 |
每段对话平均包含 35 个会话、300 轮对话、约 9,000 个词元。
数据字段结构
每条记录包含以下字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
sample_id |
string | 唯一问题标识符 |
category |
string | LoCoMo 推理类别(1=单跳,2=多跳,3=开放域,4=时间) |
question |
string | 评估问题 |
prediction |
string | Memanto 生成的答案 |
ground_truth |
string | 基准测试提供的参考答案 |
score |
int | 二元正确性评分(1=正确,0=错误),由 Claude Sonnet 4 评判 |
reasoning |
string | 评分理由(仅 ablation_1 和 ablation_2 包含) |
五阶段消融研究配置与性能
| 分割 | 阶段 | 配置 | LoCoMo 准确率 |
|---|---|---|---|
ablation_1 |
阶段 1 — 朴素基线 | k=10, 阈值=0.15, Claude Sonnet 4 | 76.2% |
ablation_2 |
阶段 2 — 召回扩展 | k=40, 阈值=0.10, Claude Sonnet 4 | 82.8% |
ablation_3 |
阶段 3 — 提示优化 | k=40, 阈值=0.10, 优化提示 | 82.9% |
ablation_4 |
阶段 4 — 最大召回 | k=100, 阈值=0.05, 动态预算 | 86.3% |
ablation_5 |
阶段 5 — 推理模型升级 | k=100, 阈值=0.05, Gemini 3 | 87.1% |
关键发现:阶段 2(召回扩展,k=10→40)实现了最大的单次性能提升(+6.6 个百分点),证实召回率——而非架构复杂度——是主要性能驱动因素。
最终按类别准确率(阶段 5)
| 类别 | 准确率 |
|---|---|
| 单跳 | 78.7% |
| 多跳 | 70.8% |
| 开放域 | 92.4% |
| 时间 | 85.4% |
| 总体 | 87.1% |
与其他系统的比较
| 系统 | LoCoMo 准确率 | 架构 | 查询策略 |
|---|---|---|---|
| Memanto(本方法) | 87.1% | 仅向量 | 单次查询 |
| Hindsight | 89.6% | 混合(反思+向量) | 并行多查询 |
| Zep | 75.1% | 混合(图+向量) | 并行单查询 |
| 完整上下文 | 72.9% | 完整上下文 | 不适用 |
| Mem0 | 66.9% | 仅向量 | 并行单查询 |
| LangMem | 58.1% | 仅向量 RAG | 单次查询 |
Memanto 在所有仅向量系统中达到最高准确率,超过 Mem0 +20.2 个百分点。
评估设置
- 基准测试: LoCoMo 标准分割,共 1,540 个问题
- LLM 评判模型: Claude Sonnet 4(所有阶段)
- 推理模型: Claude Sonnet 4(阶段 1–4),Gemini 3(阶段 5)
- Memanto 版本: 2.1.4
- 检索后端: Moorcheh ITS 引擎(单次查询,无多查询或递归策略)
加载方式(Python 示例)
python from datasets import load_dataset
加载特定消融阶段
ds = load_dataset("moorcheh/memanto-locomo-results", split="ablation_5") df = ds.to_pandas() print(df.head())
比较所有消融阶段的准确率
for stage in range(1, 6): ds = load_dataset("moorcheh/memanto-locomo-results", split=f"ablation_{stage}") df = ds.to_pandas() acc = df["score"].mean() * 100 print(f"ablation_{stage}: {acc:.1f}%")
附加资源
仓库中包含一个 Excel 工作簿(memanto_locomo_ablation_results.xlsx),内含所有五个消融结果的分页数据,格式化的表头便于离线查看。
搜集汇总
数据集介绍
构建方式
该数据集收录了Memanto在LoCoMo长时对话记忆基准上的逐问题评估结果,涵盖五阶段渐进消融实验的完整配置。每个阶段对应一个独立的数据分片,以ablation_1至ablation_5命名,分别代表从朴素基线到最优推理模型的递进方案。数据集中每条记录包含样本标识、推理类别、问题原文、模型预测答案、标准参考答案、二元正确性分数以及评判推理过程(部分分片提供),所有预测均由Claude Sonnet 4作为裁判进行自动评判。数据以标准HuggingFace格式组织,各分片文件统一存储于data目录下,便于加载和复现。
特点
本数据集最突出的特点是其结构化消融设计,完整呈现了Memanto仅凭纯向量架构即可在LoCoMo上达到87.1%准确率的演进路径。数据集严格遵循四类推理任务划分,包括单跳、多跳、开放域和时序推理,能够细致评估记忆系统在不同认知维度上的表现。特别地,数据揭示了召回扩展(k从10提升至40)带来了6.6个百分点的最大增益,直接证明了检索召回率而非架构复杂度是决定长时记忆性能的主导因素。所有评估结果均基于可复现的标准化流程产出,并附有完整的元数据标注。
使用方法
用户可通过HuggingFace Datasets库便捷地加载任意消融阶段的数据分片,例如使用load_dataset('moorcheh/memanto-locomo-results', split='ablation_5')即可获取最优配置下的完整评估结果。加载后的数据可直接转换为Pandas DataFrame进行统计分析,通过计算score字段的均值即可快速复现各阶段的准确率。为了系统性比较不同配置的表现,可以循环遍历ablation_1至ablation_5五个分片,汇总得出完整消融曲线。此外,数据集还提供了包含所有分片的Excel工作簿,便于离线查阅和汇报展示。
背景与挑战
背景概述
面向长期对话的智能体记忆机制是当前人工智能研究的前沿议题,其核心挑战在于如何在多轮、跨会话的交互中高效维持与检索结构化信息。Memanto-LoCoMo结果数据集由Moorcheh AI与EdgeAI Innovations团队于2026年发布,主要研究人员包括Seyed Moein Abtahi、Rasa Rahnema等,旨在评估其提出的Memanto记忆系统在LoCoMo基准上的性能。该研究聚焦于利用信息论检索与类型化语义记忆架构,在无需知识图谱或多查询流水线的情况下实现高效的长程对话理解。该数据集系统性地记录了一次渐进式消融实验的全部结果,覆盖了从朴素基线到最优配置的五个阶段,为向量化智能体记忆领域的性能比较与架构分析提供了关键参照,对推动高效、低延迟的长期对话智能体发展具有重要影响力。
当前挑战
该数据集所应对的领域核心挑战在于,现有长程对话记忆系统往往依赖复杂的混合架构(如知识图谱加向量检索或多查询策略),导致延迟高、成本大且难以扩展。Memanto的设计目标是仅凭纯向量架构实现高精度记忆检索,因此其面临的关键问题包括:如何在单次查询约束下应对多跳推理、时间顺序推理等复杂任务,以及如何在召回率与精度间取得平衡。构建过程中,研究团队遇到了召回瓶颈(阶段一召回设置下准确率仅76.2%)、提示工程对生成结果的影响,以及不同推理模型(从Claude到Gemini)带来的性能波动等挑战。通过五阶段消融实验,结果显示召回扩展(k=10升至40)带来了最大增益(+6.6个百分点),揭示了检索召回率而非架构复杂度是主导性能的核心因素。
常用场景
经典使用场景
在长时对话记忆的评测领域中,memanto-locomo-results数据集作为Memanto系统在LoCoMo基准上的逐题评估结果集合,为研究者提供了一套严谨的渐进式消融实验结果。该数据集涵盖了从朴素基线到最终性能达87.1%准确率的五个消融阶段,每个阶段包含1540道来自多会话对话的推理问题,横跨单跳、多跳、开放域和时间序四大推理类别。这一设计使其成为评估智能体长期记忆系统性能的经典工具,尤其适用于验证语义记忆检索架构中召回率、阈值与推理模型等关键组件的边际贡献。研究者常运用该数据集进行向量检索系统的对比分析,通过逐题得分与推理日志深入剖析不同策略的优劣,从而推动记忆驱动型对话智能体的发展。
实际应用
在实际应用层面,该数据集衍生的方法已展露出在对话式AI代理部署中的巨大潜力。Memanto系统凭借其亚90毫秒的确定性语义检索与零摄入延迟特性,非常适用于需要实时响应的客户服务机器人、长期陪伴型虚拟助手以及多会话任务规划等场景。例如,在电商客服系统中,代理可借助类型化记忆模式精准追踪用户偏好、承诺与历史决策,避免重复提问;在医疗随访场景中,系统能跨数月对话维持对患者症状、治疗方案和约定事项的一致性记忆。数据集所展示的消融结果,为开发者在资源预算与性能目标之间权衡时提供了可量化的参考路径,推动了大语言模型从一次性交互向持续性协作的进化。
衍生相关工作
该数据集及其背后的Memanto架构已催生了一系列重要的衍生研究工作。围绕信息论检索引擎,Moorcheh团队后续深化了从HNSW到信息论二值化的可扩展向量搜索理论,形成了ITS引擎的独立理论体系。在评测方法论层面,LoCoMo基准本身因其对长期记忆的严苛考验而成为继Hindsight等系统后的标准对比平台,后续涌现的多种混合架构(如结合反射机制与向量检索的系统)均参考了该数据集的消融范式来定位自身优势。此外,基于数据集中的推理日志,研究者进一步探索了LLM裁判的偏差校准方法,推动了对话记忆评测中自动评估标准的完善。这些工作共同构建了一个以实证数据为驱动的智能体记忆研究生态。
以上内容由遇见数据集搜集并总结生成


