有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
该数据集是Bittensor Subnet 13去中心化网络的一部分,包含从X(原Twitter)预处理的数据。数据由网络矿工持续更新,提供实时推文流,适用于各种分析和机器学习任务。
该数据集的多功能性允许研究人员和数据科学家探索社交媒体动态的各个方面,并开发创新应用。用户可以利用这些数据进行以下任务:
主要语言:数据集主要是英语,但由于去中心化的创建方式,可能是多语言的。
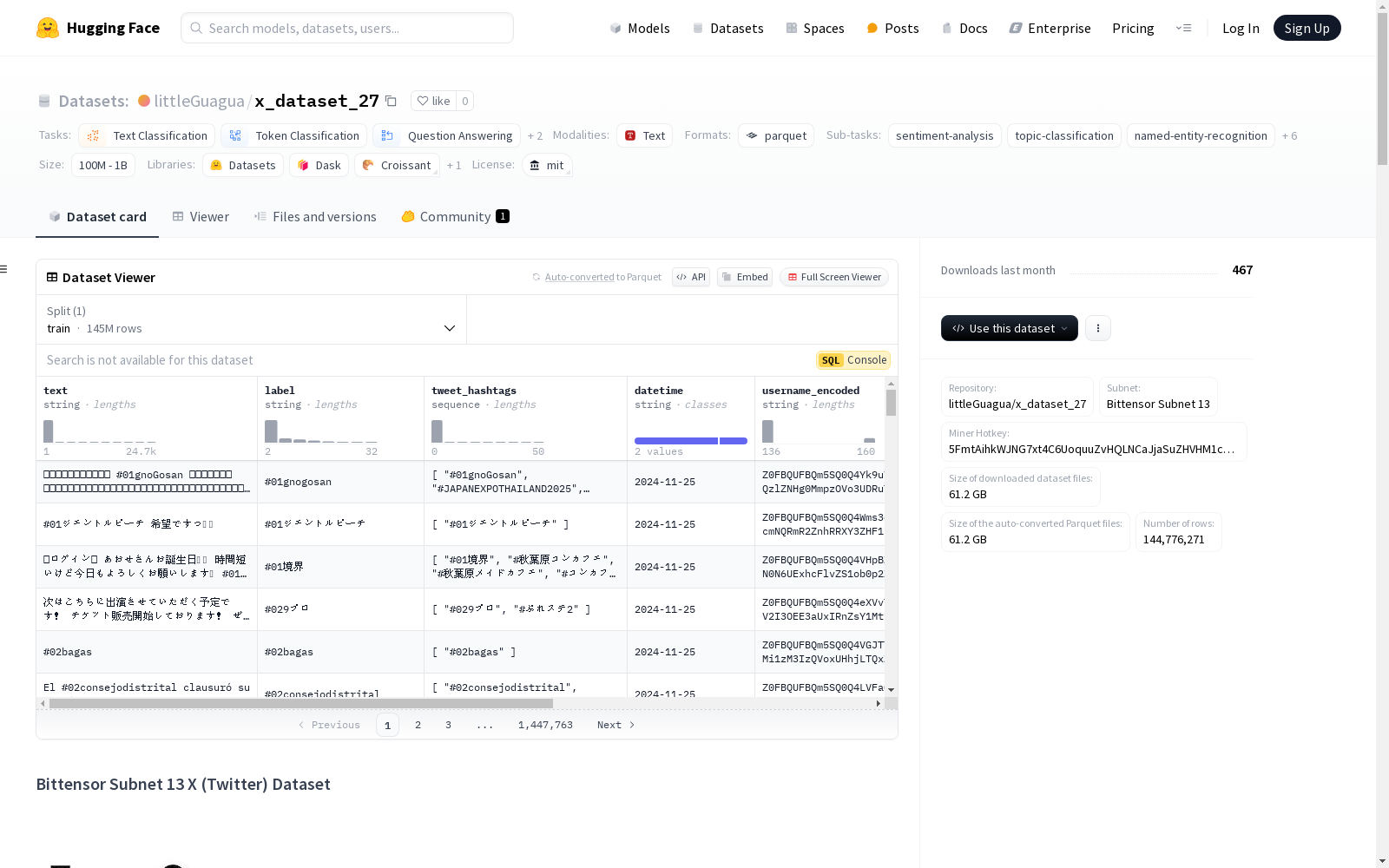
每个实例代表一条推文,包含以下字段:
text (string): 推文的主要内容。label (string): 推文的情感或主题类别。tweet_hashtags (list): 推文中使用的标签列表。如果没有标签,则为空。datetime (string): 推文发布日期。username_encoded (string): 用户名的编码版本,以保护用户隐私。url_encoded (string): 推文中包含的URL的编码版本。如果没有URL,则为空。该数据集持续更新,没有固定的分割。用户应根据其需求和数据的时间戳创建自己的分割。
数据从X(Twitter)上的公开推文中收集,遵守平台的条款服务和API使用指南。
所有用户名和URL都经过编码以保护用户隐私。数据集不包含个人或敏感信息。
用户应注意X(Twitter)数据中固有的潜在偏见,包括人口统计和内容偏见。该数据集反映了X上表达的内容和观点,不应被视为一般人口的代表性样本。
该数据集在MIT许可下发布。使用此数据集还需遵守X的使用条款。
如果您在研究中使用此数据集,请按以下方式引用:
@misc{littleGuagua2024datauniversex_dataset_27, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={littleGuagua}, year={2024}, url={https://huggingface.co/datasets/littleGuagua/x_dataset_27}, }
如需报告问题或贡献数据集,请联系矿工或使用Bittensor Subnet 13的治理机制。
| 排名 | 主题 | 总数 | 百分比 |
|---|---|---|---|
| 1 | NULL | 66281559 | 55.97% |
| 2 | #tiktok | 417031 | 0.35% |
| 3 | #riyadh | 395629 | 0.33% |
| 4 | #ad | 286511 | 0.24% |
| 5 | #gmmtv2025 | 229453 | 0.19% |
| 6 | #騎士aリプ返24時間 | 166417 | 0.14% |
| 7 | #pr | 147806 | 0.12% |
| 8 | #yahooニュース | 143004 | 0.12% |
| 9 | #แจกจริง | 138659 | 0.12% |
| 10 | #xrp | 137133 | 0.12% |
| 日期 | 新增实例 | 总实例 |
|---|---|---|
| 2024-11-25T09:20:08Z | 641805 | 641805 |
| 2024-11-25T09:20:39Z | 1444868 | 2086673 |
| 2024-11-28T21:35:30Z | 28867157 | 30953830 |
| 2024-12-02T09:49:50Z | 29355165 | 60308995 |
| 2024-12-05T22:07:36Z | 29187771 | 89496766 |
| 2024-12-09T10:24:58Z | 29562362 | 119059128 |
Beijing Traffic
The Beijing Traffic Dataset collects traffic speeds at 5-minute granularity for 3126 roadway segments in Beijing between 2022/05/12 and 2022/07/25.
Papers with Code 收录
HazyDet
HazyDet是由解放军工程大学等机构创建的一个大规模数据集,专门用于雾霾场景下的无人机视角物体检测。该数据集包含383,000个真实世界实例,收集自自然雾霾环境和正常场景中人工添加的雾霾效果,以模拟恶劣天气条件。数据集的创建过程结合了深度估计和大气散射模型,确保了数据的真实性和多样性。HazyDet主要应用于无人机在恶劣天气条件下的物体检测,旨在提高无人机在复杂环境中的感知能力。
arXiv 收录
OpenSonarDatasets
OpenSonarDatasets是一个致力于整合开放源代码声纳数据集的仓库,旨在为水下研究和开发提供便利。该仓库鼓励研究人员扩展当前的数据集集合,以增加开放源代码声纳数据集的可见性,并提供一个更容易查找和比较数据集的方式。
github 收录
VisDrone2019
VisDrone2019数据集由AISKYEYE团队在天津大学机器学习和数据挖掘实验室收集,包含288个视频片段共261,908帧和10,209张静态图像。数据集覆盖了中国14个不同城市的城市和乡村环境,包括行人、车辆、自行车等多种目标,以及稀疏和拥挤场景。数据集使用不同型号的无人机在各种天气和光照条件下收集,手动标注了超过260万个目标边界框,并提供了场景可见性、对象类别和遮挡等重要属性。
github 收录
AgiBot World
为了进一步推动通用具身智能领域研究进展,让高质量机器人数据触手可及,作为上海模塑申城语料普惠计划中的一份子,智元机器人携手上海人工智能实验室、国家地方共建人形机器人创新中心以及上海库帕思,重磅发布全球首个基于全域真实场景、全能硬件平台、全程质量把控的百万真机数据集开源项目 AgiBot World。这一里程碑式的开源项目,旨在构建国际领先的开源技术底座,标志着具身智能领域 「ImageNet 时刻」已到来。AgiBot World 是全球首个基于全域真实场景、全能硬件平台、全程质量把控的大规模机器人数据集。相比于 Google 开源的 Open X-Embodiment 数据集,AgiBot World 的长程数据规模高出 10 倍,场景范围覆盖面扩大 100 倍,数据质量从实验室级上升到工业级标准。AgiBot World 数据集收录了八十余种日常生活中的多样化技能,从抓取、放置、推、拉等基础操作,到搅拌、折叠、熨烫等精细长程、双臂协同复杂交互,几乎涵盖了日常生活所需的绝大多数动作需求。
github 收录