CCB/cis5300-word-embeddings
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/CCB/cis5300-word-embeddings
下载链接
链接失效反馈官方服务:
资源简介:
该数据集支持学习词嵌入(捕捉词义的密集向量表示)。它包含一个标准的相似性基准(SimLex-999)、一个词义消歧任务(Word Sense Clustering)以及用于训练自定义词嵌入的莎士比亚语料库。SimLex-999是一个专门测量语义相似性的黄金标准基准,不同于WordSim-353(它将相似性与相关性混为一谈)。Word Sense Clustering包含多义词及其意义,用于评估词嵌入是否能区分词的不同意义。数据集还包含莎士比亚剧本的文本文件和预计算的共现向量,用于训练和评估词嵌入模型。该数据集用于宾夕法尼亚大学自然语言处理课程(CIS 5300)的作业,学生需训练词嵌入模型、探索词类比和向量运算、评估词嵌入在SimLex-999上的表现、聚类多义词意义以及研究词嵌入中的偏见。
This dataset supports learning about word embeddings — dense vector representations that capture word meaning. It includes a standard similarity benchmark (SimLex-999), a word sense disambiguation task (Word Sense Clustering), and a Shakespeare corpus for training custom embeddings. SimLex-999 is a gold-standard benchmark for evaluating word embeddings, specifically measuring semantic similarity (unlike WordSim-353 which conflates similarity with relatedness). Word Sense Clustering contains polysemous words and their senses, for evaluating whether embeddings can distinguish word senses. The dataset also includes Shakespeare plays and pre-computed co-occurrence vectors for training and evaluating word embeddings. The dataset is used for Homework 4 in CIS 5300: Natural Language Processing at the University of Pennsylvania, where students train Word2Vec embeddings, explore word analogies and vector arithmetic, evaluate embeddings on SimLex-999, cluster polysemous word senses, and investigate bias in word embeddings.
提供机构:
CCB
搜集汇总
数据集介绍
构建方式
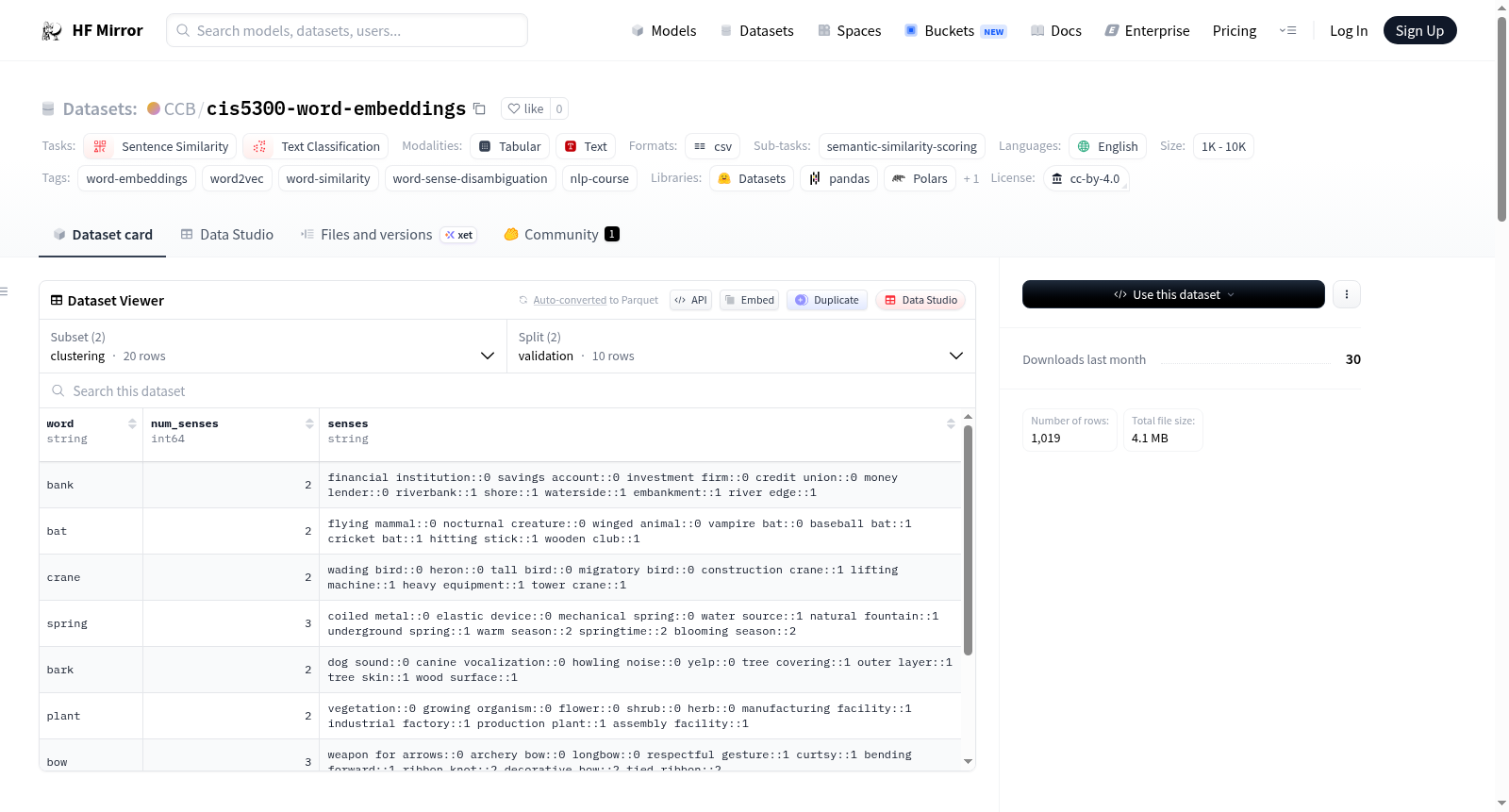
该数据集专为宾夕法尼亚大学CIS 5300自然语言处理课程设计,旨在辅助学生深入理解词嵌入(word embeddings)这一核心概念。数据集整合了多个组件:首先收录了SimLex-999标准基准,该基准由Hill等人于2015年构建,包含999对英语词汇,每对词汇均附带人工评定的语义相似度分数、词性标注及具体性评级等丰富属性;其次,数据集提供了一组多义词及其不同义项的聚类数据,用于评估词嵌入区分词义的能力;此外,数据集还纳入了12部莎士比亚戏剧的完整文本,作为训练自定义Word2Vec嵌入的语料,并附有预先计算的500维共现向量,用于词义消歧任务。
特点
该数据集的显著特点在于其教学导向与多任务覆盖的精心设计。SimLex-999基准专注于纯粹的语义相似度测量,与WordSim-353等将相似性与关联性混为一谈的基准不同,能更精确地评估词嵌入的语义捕获能力。多义词聚类数据包含每个词汇的义项数量及带标签的义项释义,为无监督词义消歧提供了标准测试。莎士比亚戏剧语料库则具备历史语言风格,为训练领域特化词嵌入提供了理想素材。所有数据均遵循CC-BY-4.0许可协议,易于获取与复现。
使用方法
用户可通过HuggingFace Datasets库便捷加载两种配置:使用`load_dataset("CCB/cis5300-word-embeddings", "simlex999")`获取相似度基准,其test集包含999个样本,可直接用于评估词嵌入与人类判断的相关性;使用`load_dataset("CCB/cis5300-word-embeddings", "clustering")`获取多义词聚类数据,含10个验证与10个测试样本,可用于义项聚类任务。辅助文件需通过`hf_hub_download`函数下载,例如下载《哈姆雷特》文本供训练使用。典型工作流程包括利用gensim库在莎士比亚文本上训练Word2Vec模型,进行向量运算,并评估其在SimLex-999上的表现,最终借助共现向量聚类分析多义词义项。
背景与挑战
背景概述
词语嵌入作为自然语言处理领域的基石技术,通过将词汇映射至低维稠密向量空间,为语义计算提供了高效表示范式。该数据集诞生于宾夕法尼亚大学CIS 5300课程的教学实践中,由课程团队整合构建,核心围绕词汇嵌入的评估与理解展开。研究问题聚焦于如何通过标准化基准检验嵌入向量对语义相似性的刻画能力,以及如何利用向量空间区分多义词的不同义项。数据集整合了SimLex-999这一广受认可的语义相似性基准(Hill等,2015),并引入了词义聚类任务与莎士比亚语料库,为教学研究提供了端到端的实验平台。其在自然语言处理教学领域具有独特影响力,尤其推动了学员对词向量性质、类比推理及偏见检测的实践认知。
当前挑战
该数据集所解决的核心领域问题在于突破词汇语义建模中的两个瓶颈:其一,传统相似度基准如WordSim-353混淆了语义相似性与关联性,SimLex-999通过严格区分“相似”(如轿车与汽车)与“关联”(如轿车与轮胎)提供了更纯净的评估尺度;其二,多义词的义项区分始终是词向量学习的痛点,数据集通过聚类验证任务检验向量能否显式分离不同语境下的语义。构建过程中面临的挑战包括:SimLex-999评分需依赖大规模人类标注以确保信度,词义聚类数据需精心设计义项释义以避免歧义,且莎士比亚古英语语料与现代词向量训练范式存在语言历时性差异,需在预处理中平衡历史文本特性与现代算法兼容性。
常用场景
经典使用场景
该数据集最经典的用途在于评估和比较词嵌入(word embeddings)的质量。研究人员常借助SimLex-999基准,通过计算词对之间的余弦相似度与人工标注的语义相似度之间的斯皮尔曼相关系数,来量化所生成词向量的语义捕获能力。此外,数据集中包含的莎士比亚语料库可用于训练Word2Vec模型,进而探索词向量在类比推理(如“国王-男性+女性=女王”)中的表现,这构成了词嵌入评测中最具代表性的实践路径。
实际应用
在实际应用中,该数据集的评测框架被广泛嵌入自然语言处理系统的开发流程中。例如,信息检索系统利用词嵌入的相似度排序功能优化查询扩展,而搜索引擎则借助语义相似度计算改进结果相关性。在对话系统和文本分析工具中,基于SimLex-999标准筛选出的高质量词向量可用于提升语义匹配、同义词推荐等功能的准确率。此外,词义聚类部分所提供的多义词标注数据,为电商平台的商品标签歧义消除、法律文本的关键词辨析等场景提供了可落地的训练与验证资源。
衍生相关工作
该数据集催生了一系列具影响力的衍生研究。在词嵌入评估领域,SimLex-999的发布直接激励了后续如WordSim-353的修订版、SimVerb-3500等更细粒度基准的构建。围绕多义词消歧任务,研究人员基于其词义聚类配置提出了多种上下文感知嵌入方法,例如ELMo和BERT等模型的涌现即部分受惠于对静态词嵌入局限性(通过该数据集揭示)的突破。此外,该数据集在文本分类、句子相似度等下游任务中常被用作对比基线,推动了对词向量维度、训练语料规模及去偏方案的系统性探索。
以上内容由遇见数据集搜集并总结生成


