celsowm/srp-gpt2-ptbr-corpus
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/celsowm/srp-gpt2-ptbr-corpus
下载链接
链接失效反馈官方服务:
资源简介:
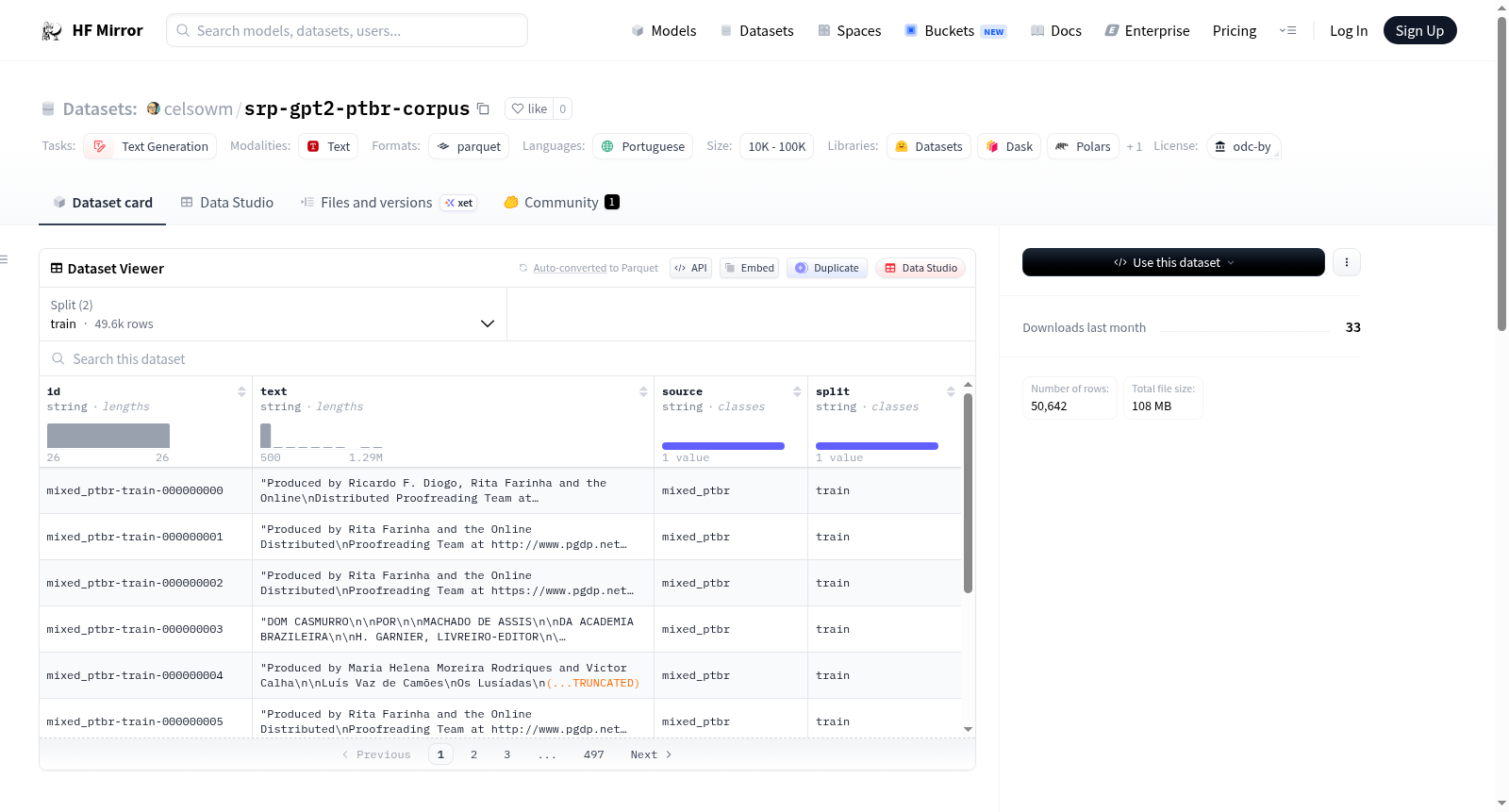
SRP GPT-2 PT-BR Corpus是一个用于葡萄牙语(pt-BR)自回归语言模型训练的公开语料库。该数据集由Project Gutenberg和FineWeb2的公开文本组成,包含49,610个训练文档和1,032个验证文档。数据集中的每一行包含一个稳定的文档标识符(id)、UTF-8编码的文本内容(text)、语料库来源标签(source)以及数据分割标签(split)。使用该数据集时需遵守原始来源的许可条款,特别是FineWeb2的ODC-By 1.0许可证要求归属。
SRP GPT-2 PT-BR Corpus is a public corpus in Parquet format for autoregressive training of language models in Portuguese (pt-BR). This dataset is a composition of public/reproducible texts, with attribution to original sources: Project Gutenberg (accessed via Gutendex API) and FineWeb2 from Hugging Face (filtered for Portuguese/pt-BR). It contains 49,610 training documents and 1,032 validation documents. Each row includes a stable document identifier (id), UTF-8 encoded text content (text), corpus source label (source), and data split label (split). Usage of this dataset requires compliance with the original sources licensing terms, particularly the ODC-By 1.0 license for FineWeb2 which requires attribution.
提供机构:
celsowm
搜集汇总
数据集介绍
构建方式
该数据集面向葡萄牙语(巴西)自回归语言模型的训练需求,通过整合公开可用的高质量语料资源构建而成。其核心来源包括Project Gutenberg的文学作品(经由Gutendex API获取)以及Hugging Face发布的FineWeb2数据集中筛选出的葡萄牙语/巴西葡萄牙语子集。所有文本均以Parquet格式存储,并划分为训练集(49,610篇文档)与验证集(1,032篇文档),确保数据高效加载与规模适配。
特点
数据集以文本自回归生成为核心任务,提供统一的结构化字段,包括文档唯一标识符(id)、UTF-8编码的纯文本内容(text)、来源标签(source)以及数据集划分标识(split)。其文本来源具有明确的法律合规性——FineWeb2遵循ODC-By 1.0许可,Gutenberg作品多属美国公共领域,且所有内容均可公开引用或再发布。这一设计在保障模型训练多样性的同时,兼顾了版权溯源与合规要求。
使用方法
用户可通过Hugging Face的datasets库直接加载该数据集,无需额外下载。示例代码为:`from datasets import load_dataset; ds = load_dataset("celsowm/srp-gpt2-ptbr-corpus")`,随后可按需访问训练或验证子集中的文本字段,例如`ds["train"][0]["text"][:200]`提取前200字符。建议结合transformers库中的GPT-2等自回归模型进行微调,生成符合葡萄牙语语法的自然语言文本。
背景与挑战
背景概述
该数据集名为SRP GPT-2 PT-BR Corpus,由研究人员celsowm创建于2024年,旨在为葡萄牙语(尤其是巴西葡萄牙语)的自回归语言模型训练提供高质量的公开语料。数据集的构建源于自然语言处理领域对非英语语言资源的迫切需求,尤其是葡萄牙语在预训练模型中的语料匮乏问题。该数据集整合了Project Gutenberg(通过Gutendex API获取)和Hugging Face的FineWeb2(过滤后的葡萄牙语子集)两大来源,共计49,610个训练文档和1,032个验证文档,以Parquet格式存储,并遵循ODC-By许可证。其核心研究问题是降低葡萄牙语模型训练的数据门槛,推动低资源语言的自然语言处理研究。该数据集对巴西及葡语国家的研究社区具有重要影响力,为GPT-2等模型的微调和预训练提供了标准化基准。
当前挑战
该数据集面临的核心领域挑战在于葡萄牙语作为低资源语言的语言模型训练,其语料多样性不足、质量参差不齐,且缺乏大规模、公开可用的标注数据,导致模型泛化能力受限。构建过程中,数据集需要处理来自不同来源的文本兼容性问题,例如Project Gutenberg中的古英语及公有领域作品可能与现代葡语用法存在差异,而FineWeb2的网络爬取数据则面临噪声、版权合规性及语言过滤精度等挑战。此外,跨源数据的一致性与去重、训练-验证集划分的合理性,以及ODC-By许可证下对原始来源的持续归因要求,均增加了数据管理的复杂性。这些挑战共同制约了数据集在高级语言任务上的表现,并需要后续通过更丰富的语料扩展和精细的筛选策略加以优化。
常用场景
经典使用场景
在自然语言处理领域,srp-gpt2-ptbr-corpus数据集是专门为葡萄牙语(尤其是巴西葡萄牙语)自回归语言模型训练而精心构建的公共语料库。该数据集融合了Project Gutenberg的经典文学作品与FineWeb2的海量网络文本,通过高质量的文本清洗与组织,为研究者提供了一个可直接用于预训练或微调GPT-2等自回归模型的标准基准。其经典的用法是作为语言模型从头训练或继续训练的数据源,研究者通常基于该数据集来评估模型在葡萄牙语上的语言生成能力、语法准确性以及语义连贯性。此外,该数据集也广泛用于计算语言学的对比实验,例如与其他葡萄牙语语料库进行跨域或跨时代的语言特征分析。
实际应用
在实际应用中,srp-gpt2-ptbr-corpus数据集为巴西及其他葡萄牙语地区的智能化文本生成服务提供了坚实的底层支撑。基于该数据集训练的GPT-2模型可以直接部署于智能客服系统中的自动回复生成、新闻摘要的自动编写、以及教育领域中葡语作文的辅助创作等场景。例如,在面向巴西市场的聊天机器人开发中,基于此语料库微调的模型能够更自然地理解当地俚语与文化习惯,提升用户交互体验。此外,该数据集还可用于语音助手的多轮对话系统构建,帮助模型生成符合葡萄牙语语法与语用习惯的流畅回馈。媒体与出版机构也可借助由此数据集训练的模型进行海量文本的快速初稿撰写,大幅提升内容生产效率。
衍生相关工作
该数据集的发布催生了一系列围绕葡萄牙语语言建模的衍生研究工作。经典的后续研究包括基于srp-gpt2-ptbr-corpus微调的领域特定语言模型,例如面向法律、医学或文学批评的专用GPT-2变体。研究者还利用该数据集进行模型压缩与知识蒸馏实验,探索在资源受限设备上部署葡萄牙语语言模型的可能性。同时,该数据集也被用作文本风格迁移、可控文本生成等任务的基准数据,促进了葡萄牙语自然语言生成技术的多样化发展。此外,由于数据集融合了文学与网络两种风格迥异的语料,不少工作将其作为跨域语言适应性研究的实验平台,深入分析了模型在不同文本类型间的迁移表现与鲁棒性。
以上内容由遇见数据集搜集并总结生成


