InstaGen
收藏arXiv2024-04-08 更新2024-06-21 收录
下载链接:
https://fcjian.github.io/InstaGen
下载链接
链接失效反馈官方服务:
资源简介:
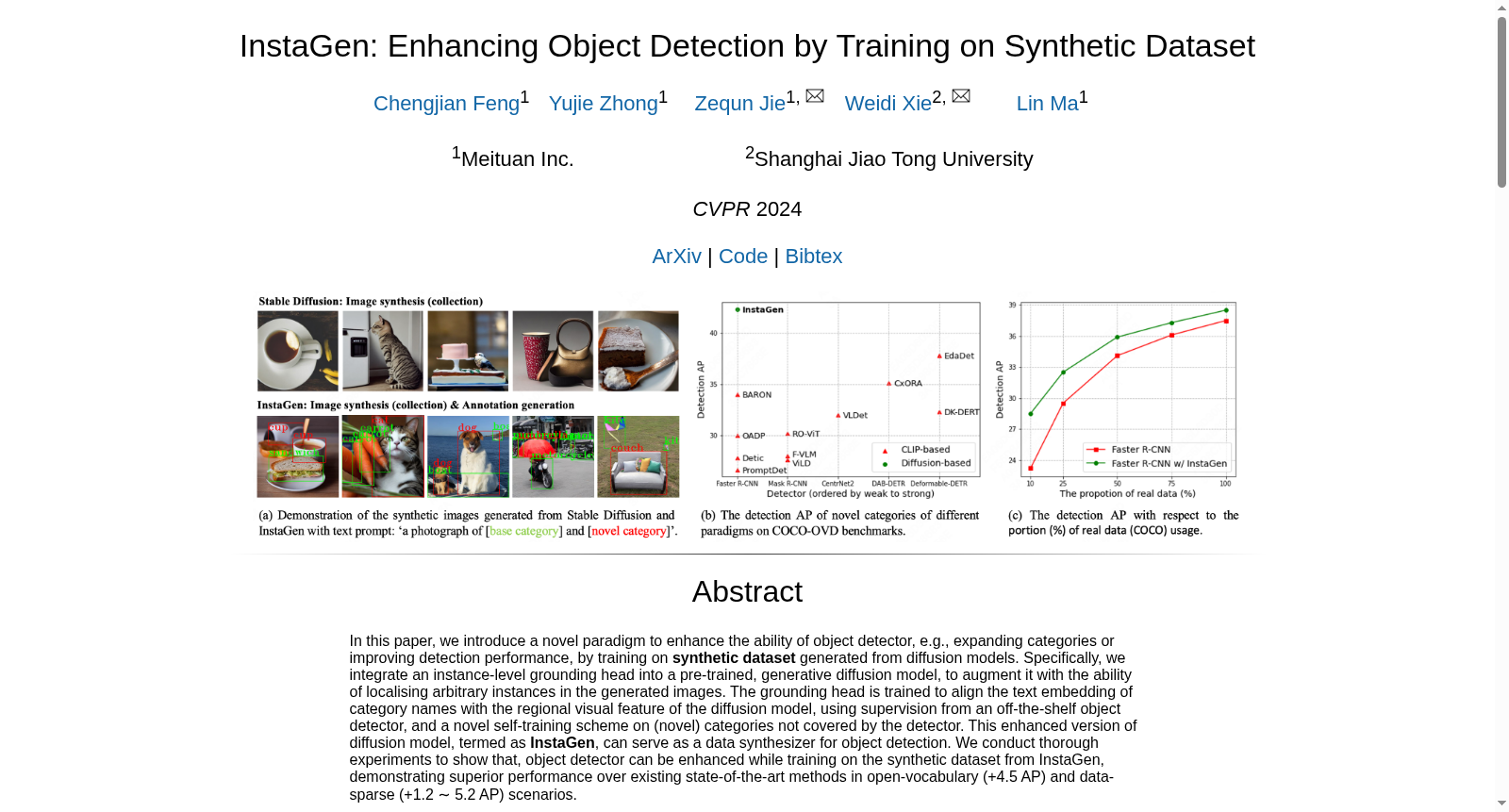
InstaGen是由美团公司开发的一个用于增强目标检测的合成数据集。该数据集通过集成预训练的生成扩散模型,能够大规模生成具有实例边界框的逼真图像。InstaGen不仅在开放词汇检测中显示出对新类别的显著改进,而且在数据稀缺情况下也能提升检测性能。数据集的创建过程涉及对现有检测数据集的微调,以及引入实例接地模块来生成合成图像中的对象边界框。InstaGen的应用领域包括扩展可检测类别和提高整体检测性能,特别是在开放词汇和数据稀缺场景中。
InstaGen is a synthetic dataset developed by Meituan for enhancing object detection. By integrating pretrained generative diffusion models, it can generate large-scale photorealistic images with instance bounding boxes. InstaGen not only demonstrates significant improvements on novel categories in open-vocabulary detection, but also boosts detection performance in data-scarce scenarios. The creation of InstaGen involves fine-tuning existing detection datasets and introducing an instance grounding module to generate object bounding boxes in synthetic images. Its application scenarios include expanding detectable categories and improving overall detection performance, especially in open-vocabulary and data-scarce scenarios.
提供机构:
美团公司
创建时间:
2024-02-09
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,高质量标注数据的稀缺性制约了目标检测模型的泛化能力。InstaGen数据集通过创新的合成范式构建,其核心在于将预训练的稳定扩散模型转化为数据合成器。首先,利用现有检测数据集中的图像裁剪与类别名称构建图文对,对扩散模型进行微调,使其能够生成包含多对象及复杂背景的逼真图像。随后,设计一个实例级接地模块,该模块通过监督学习与自训练策略,将类别文本嵌入与扩散模型的区域视觉特征对齐,从而为合成图像中的任意类别对象自动生成边界框标注。这一流程实现了无需人工标注的大规模合成数据生成。
特点
InstaGen数据集展现出若干显著特性,使其在合成数据领域独树一帜。其生成图像具有高度的真实性与场景复杂性,能够模拟真实世界中的多对象交互、遮挡及多样化背景,有效弥合了合成数据与真实数据之间的域差距。更重要的是,数据集具备开放词汇能力,其接地模块经过自训练后,能够为训练时未见的新颖类别对象生成准确的边界框,突破了传统检测数据集在类别覆盖上的限制。此外,该合成数据机制具有良好的可扩展性,能够按需生成海量数据,为数据稀缺场景下的模型训练提供了丰富资源。
使用方法
InstaGen数据集主要用于增强目标检测模型的性能。研究者可将该合成数据与真实检测数据集结合,共同训练标准的目标检测器,如Faster R-CNN。在开放词汇检测场景下,利用InstaGen生成的新类别合成数据,能够显著提升模型对未知类别的识别与定位能力。在数据稀疏场景中,即使仅有少量真实标注图像,引入合成数据也能有效增加训练数据的多样性,提升模型的鲁棒性与泛化性能。此外,该数据集还可用于跨数据集迁移任务,通过生成目标数据集类别的合成样本,辅助模型适应新的视觉领域。
背景与挑战
背景概述
在计算机视觉领域,目标检测作为一项基础任务,致力于精准定位与识别图像中的物体。传统方法依赖于大规模标注数据集,如MS-COCO与Object365,然而数据采集与标注过程耗时费力,限制了模型的泛化能力与可扩展性。2024年,美团与上海交通大学的研究团队提出了InstaGen数据集,旨在通过扩散模型生成合成数据,以增强目标检测器的性能。该数据集的核心创新在于将实例级定位头集成至预训练的生成扩散模型中,使其能够同步生成逼真图像及对应的边界框标注,从而为开放词汇与数据稀缺场景下的检测任务提供高效解决方案。
当前挑战
InstaGen数据集致力于应对开放词汇目标检测的挑战,即扩展模型识别未知类别物体的能力。传统方法依赖CLIP等视觉语言模型,但在新颖类别上表现有限;而InstaGen通过合成数据训练,显著提升了检测器对未见类别的泛化性能。在构建过程中,研究团队面临两大挑战:一是如何使扩散模型生成具有复杂背景、多物体及遮挡关系的图像,以模拟真实场景,避免模型因合成数据过于简单而丧失鲁棒性;二是设计有效的实例定位模块,在缺乏真实标注的情况下,准确对齐文本描述与视觉区域,并生成高质量的边界框标注,这需要通过监督学习与自训练策略相结合,以克服基础类别与新颖类别之间的语义鸿沟。
常用场景
经典使用场景
在计算机视觉领域,对象检测模型的训练长期依赖于大规模人工标注数据集,然而数据收集与标注过程往往耗费巨大资源。InstaGen作为一种创新的数据集合成框架,其经典应用场景在于通过扩散模型生成高质量合成图像及实例级边界框,为对象检测任务提供可扩展的训练数据源。该框架特别适用于数据稀缺或需要扩展检测类别的场景,能够生成包含复杂背景、多对象交互及遮挡情况的逼真图像,有效模拟真实世界检测环境,从而提升检测模型的泛化能力与鲁棒性。
衍生相关工作
InstaGen的提出催生了多项基于合成数据的视觉研究进展。在方法层面,其紧密耦合的实例接地头设计启发了后续工作对扩散模型内部表征的深入利用,推动了生成式模型与判别式任务的深度融合。在应用层面,该框架为开放词汇全景分割、零样本实例分割等任务提供了数据合成范式,例如相关工作将其扩展至掩码生成领域。同时,其自训练机制与伪标签生成策略被广泛借鉴于半监督学习框架中,提升了模型在未见类别上的泛化能力。这些衍生工作共同推动了生成式人工智能在视觉感知任务中的实用化进程。
数据集最近研究
最新研究方向
在计算机视觉领域,对象检测技术正经历从依赖大规模人工标注数据向利用合成数据增强模型能力的范式转变。InstaGen作为一项创新性研究,通过整合预训练的扩散模型与实例级定位头,构建了一个能够生成带边界框标注的合成数据集系统。该数据集的前沿研究方向聚焦于开放词汇对象检测与数据稀疏场景下的性能提升,其核心在于利用生成式模型的自监督能力,突破传统检测模型对固定类别和大量标注数据的依赖。通过微调稳定扩散模型以生成多对象复杂场景图像,并结合基于自训练的实例定位模块,InstaGen在开放词汇检测任务中实现了对CLIP基方法的显著超越,尤其在处理未见类别时展现出强大的泛化能力。这一进展不仅推动了合成数据在视觉任务中的应用边界,也为解决现实世界中数据稀缺与类别不平衡问题提供了新的技术路径,对自动驾驶、机器人感知等依赖高鲁棒性检测系统的领域具有深远影响。
相关研究论文
- 1InstaGen: Enhancing Object Detection by Training on Synthetic Dataset美团公司 · 2024年
以上内容由遇见数据集搜集并总结生成


