InCrowd-VI
收藏InCrowd-VI 数据集概述
数据集简介
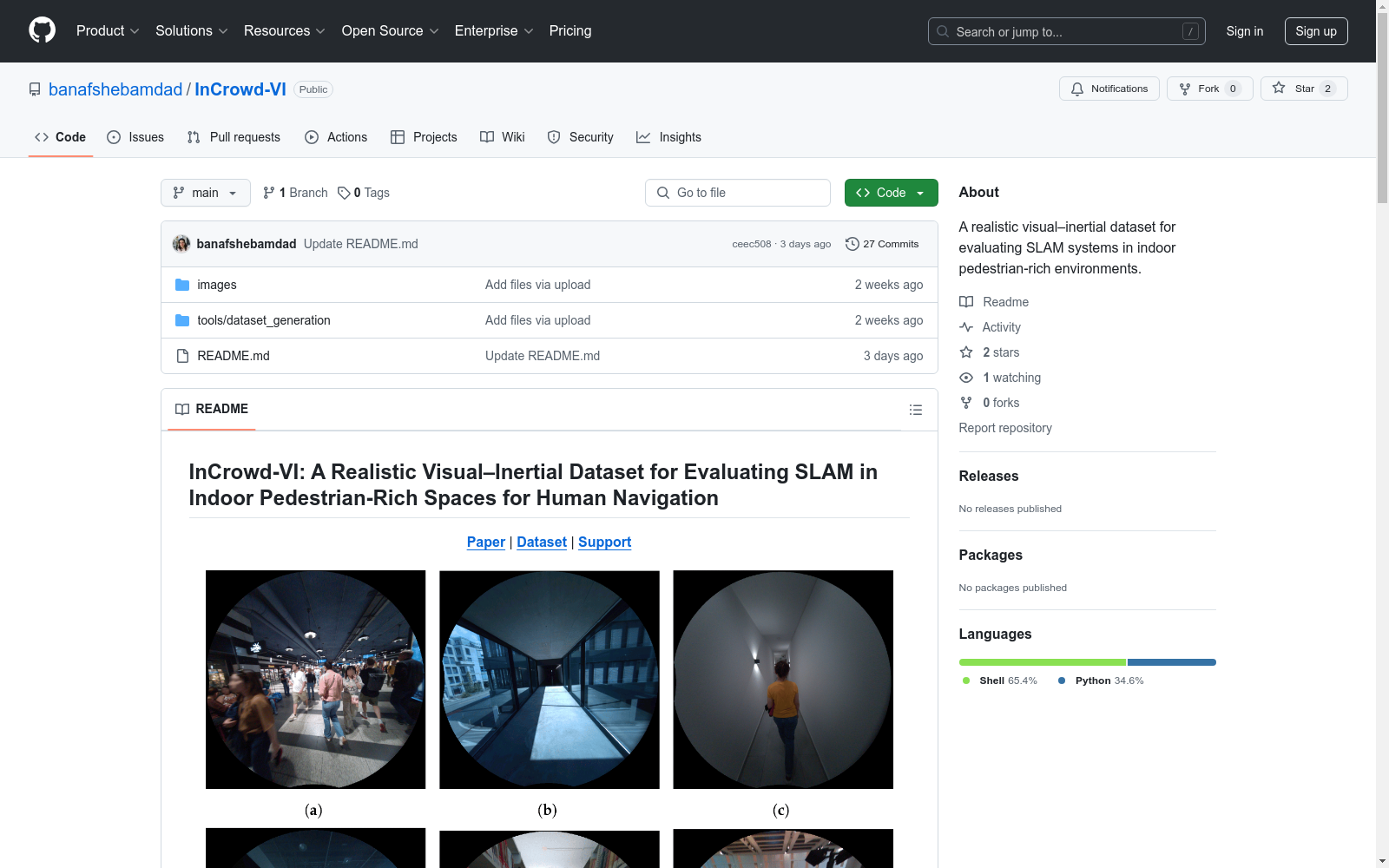
InCrowd-VI 是一个用于评估室内行人密集环境中SLAM系统的视觉-惯性数据集。该数据集包含58个序列,覆盖5公里的轨迹和1.5小时的记录,旨在推动视觉障碍人士的导航技术发展。
数据集特点
- 场景多样性:数据集展示了多种挑战性场景,包括高行人密度、不同光照条件、纹理贫乏的表面、反射表面、狭窄通道和楼梯等。
- 数据格式:由于图像文件较大,数据集提供了每个序列的
.vrs文件,用户可以使用提供的工具在本地提取所需图像。
文件结构与文档
- 序列文件结构:详细信息可在Sequence file structure页面查看。
- 校准数据:包含相机和IMU的校准参数,详见Calibration data。
- 序列概述:各序列的密度类别和主要挑战概述,详见InCrowd-VI sequences。
使用指南
系统要求
- 操作系统:Ubuntu 22.04 LTS
- Python版本:3.10
- 系统依赖: bash sudo apt install python3.10-venv
数据提取
-
设置虚拟环境: bash python3 -m venv $HOME/projectaria_tools_python_env source $HOME/projectaria_tools_python_env/bin/activate
-
安装projectaria_tools: bash python3 -m pip install --upgrade pip python3 -m pip install projectaria-tools[all]
-
下载数据集:数据集序列可从InCrowd-VI Dataset下载。
-
提取数据:使用提供的脚本从
.vrs文件中提取数据,脚本位于tools/dataset_generation目录。
数据提取脚本
bb_generate_dataset_in_loop.sh:处理多个.vrs文件。bb_generate_sequence_ns.sh:从.vrs文件中提取并校正图像。bb_image_undistortion.py:处理.vrs文件以提取和校正RGB和立体图像。
引用
如果使用该数据集或参考论文,请引用以下文献: bibtex @article{bamdad2024incrowd, title={InCrowd-VI: A Realistic Visual--Inertial Dataset for Evaluating Simultaneous Localization and Mapping in Indoor Pedestrian-Rich Spaces for Human Navigation}, author={Bamdad, Marziyeh and Hutter, Hans-Peter and Darvishy, Alireza}, journal={Sensors}, volume={24}, number={24}, pages={8164}, year={2024}, publisher={MDPI} }
致谢
特别感谢苏黎世大学机器人与感知小组提供用于本研究的Meta Aria眼镜。
支持
如有任何问题或遇到问题,请在issue页面创建问题,我们将尽快处理。