DeepFaceGen
收藏arXiv2024-06-13 更新2024-06-21 收录
下载链接:
https://anonymous.4open.science/r/DeepFaceGen-47D1
下载链接
链接失效反馈官方服务:
资源简介:
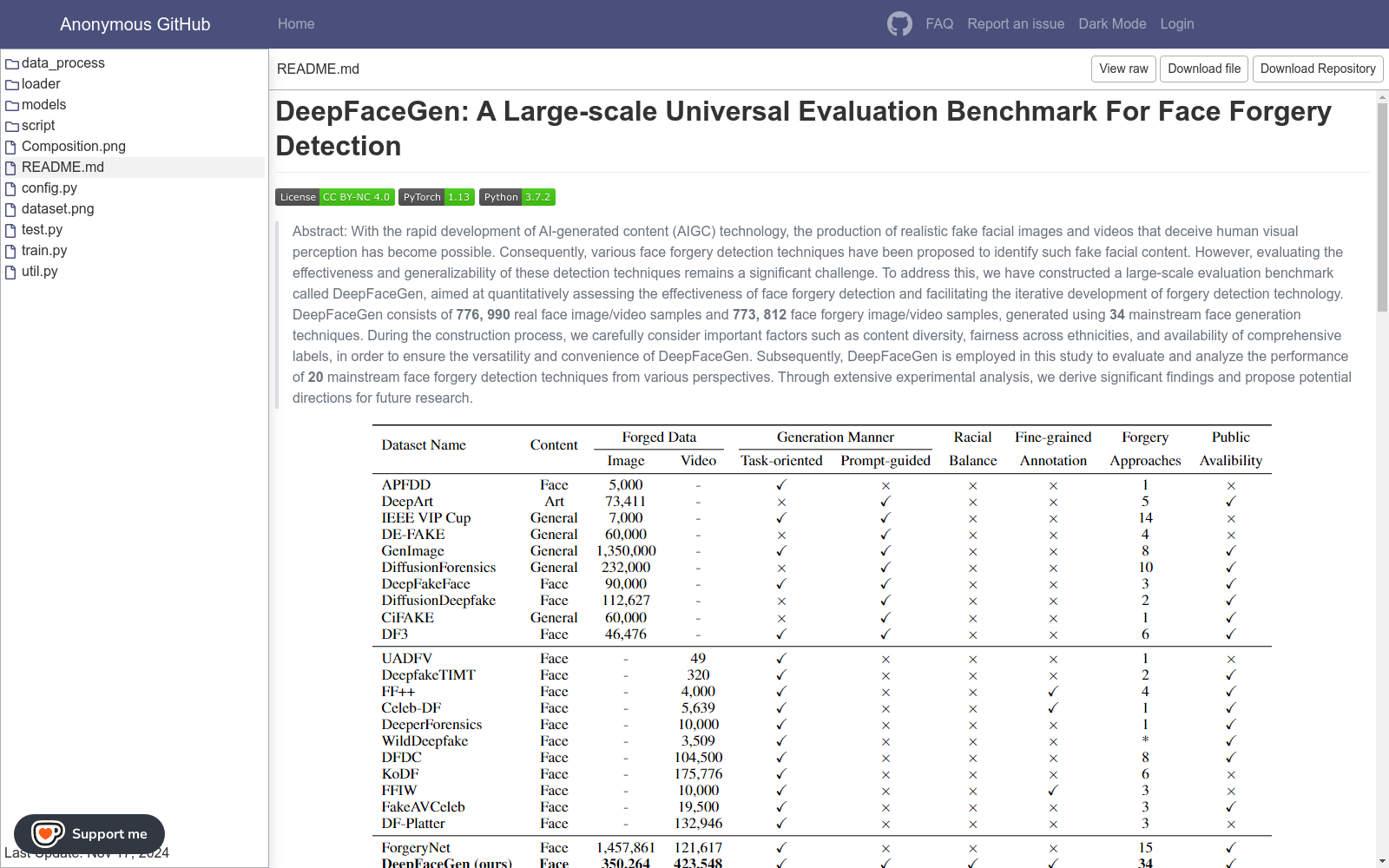
DeepFaceGen是由浙江大学构建的大型人脸伪造检测评估基准,旨在量化评估人脸伪造检测技术的有效性,并促进伪造检测技术的迭代发展。该数据集包含776,990个真实人脸图像/视频样本和773,812个人脸伪造图像/视频样本,这些伪造样本使用了34种主流人脸生成技术生成。在构建过程中,DeepFaceGen考虑了内容多样性、种族公平性和全面标签的可获取性,以确保其多功能性和便利性。该数据集主要应用于人脸伪造检测领域,旨在解决由AI生成内容技术快速发展带来的真实性验证难题,增强多媒体信息的信任度,并降低社会安全风险。
DeepFaceGen is a large-scale benchmark for face forgery detection and evaluation developed by Zhejiang University, which is designed to quantitatively evaluate the effectiveness of face forgery detection technologies and facilitate the iterative advancement of such techniques. This dataset contains 776,990 real face image/video samples and 773,812 forged face image/video samples, which were generated via 34 mainstream face generation technologies. During its construction, DeepFaceGen took into account content diversity, racial fairness, and the accessibility of comprehensive annotations to ensure its versatility and convenience. This dataset is primarily applied in the field of face forgery detection, aiming to address the authenticity verification challenges brought about by the rapid development of AI-generated content technologies, enhance the credibility of multimedia information, and mitigate social security risks.
提供机构:
浙江大学
创建时间:
2024-06-13
搜集汇总
数据集介绍
构建方式
DeepFaceGen的构建过程体现了对内容多样性、种族公平性和标签全面性的细致考量。该数据集包含了776,990个真实人脸图像/视频样本和773,812个人脸伪造图像/视频样本,这些伪造样本使用了34种主流的人脸生成技术。在构建过程中,研究团队精心考虑了生成方式、生成框架、内容多样性、种族公平性和标签丰富性等关键因素,以确保数据集的全面性和便捷性。
特点
DeepFaceGen的特点在于其大规模、多样性和全面性。该数据集不仅涵盖了广泛的真实和伪造人脸样本,还包含了34种不同的人脸生成技术,确保了数据集在检测人脸伪造技术方面的广泛适用性。此外,数据集在种族公平性和标签丰富性方面的考量,进一步提升了其在实际应用中的价值。
使用方法
DeepFaceGen的使用方法多样,适用于多种人脸伪造检测技术的评估和分析。研究者可以利用该数据集对现有的人脸伪造检测技术进行全面的性能评估,从伪造方式、生成框架和泛化能力等多个角度进行分析。此外,数据集的开放性和详细的使用文档,使得研究者能够方便地进行实验和验证,推动人脸伪造检测技术的发展。
背景与挑战
背景概述
随着人工智能生成内容(AIGC)技术的迅速发展,生成逼真的伪造面部图像和视频已成为可能,这些内容能够欺骗人类的视觉感知。因此,各种面部伪造检测技术应运而生,以识别这些伪造内容。然而,评估这些检测技术的有效性和泛化能力仍然是一个重大挑战。为了解决这一问题,我们构建了一个大规模的评估基准,名为DeepFaceGen,旨在定量评估面部伪造检测的有效性,并促进伪造检测技术的迭代发展。DeepFaceGen包含776,990个真实面部图像/视频样本和773,812个面部伪造图像/视频样本,这些样本使用了34种主流的面部生成技术生成。在构建过程中,我们仔细考虑了内容多样性、种族公平性和全面标签可用性等重要因素,以确保DeepFaceGen的多功能性和便利性。随后,DeepFaceGen被用于本研究中,从多个角度评估和分析13种主流面部伪造检测技术的性能。通过广泛的实验分析,我们得出了重要的发现,并提出了未来研究的可能方向。
当前挑战
DeepFaceGen数据集在构建和应用过程中面临多项挑战。首先,生成逼真的伪造面部图像和视频的技术不断进步,使得检测这些伪造内容的难度增加。其次,数据集的构建需要考虑内容多样性、种族公平性和标签的全面性,这增加了数据集的复杂性和构建难度。此外,评估面部伪造检测技术的有效性和泛化能力需要大量的实验和分析,这不仅耗时且资源密集。最后,随着伪造技术的不断发展,数据集需要不断更新以保持其相关性和有效性,这要求持续的研究和资源投入。
常用场景
经典使用场景
DeepFaceGen 数据集在人脸伪造检测领域中被广泛应用于评估和分析现有检测技术的有效性和通用性。通过包含大量真实和伪造的人脸图像及视频样本,该数据集为研究人员提供了一个全面的基准,用于测试和改进人脸伪造检测算法。其经典使用场景包括对不同生成技术、生成框架和伪造方式的检测性能进行量化评估,以及探索检测技术在不同种族和内容多样性下的表现。
解决学术问题
DeepFaceGen 数据集解决了人脸伪造检测领域中的一个关键学术问题,即如何在一个多样化和公平的基准上评估检测技术的有效性和通用性。通过提供由34种主流人脸生成技术生成的773,812个伪造样本和776,990个真实样本,该数据集使得研究人员能够系统地分析和比较不同检测方法的性能,从而推动该领域的技术迭代和发展。
衍生相关工作
基于 DeepFaceGen 数据集,研究人员已经开展了一系列相关工作,包括开发新的检测算法、改进现有的检测模型以及探索多模态(如图像和视频)的检测方法。例如,一些研究通过分析该数据集中的特征分布,提出了基于频率域的检测技术,显著提高了对高压缩图像中伪造痕迹的识别能力。此外,还有工作利用该数据集进行跨种族和跨年龄的检测性能评估,以确保检测技术的公平性和广泛适用性。
以上内容由遇见数据集搜集并总结生成


