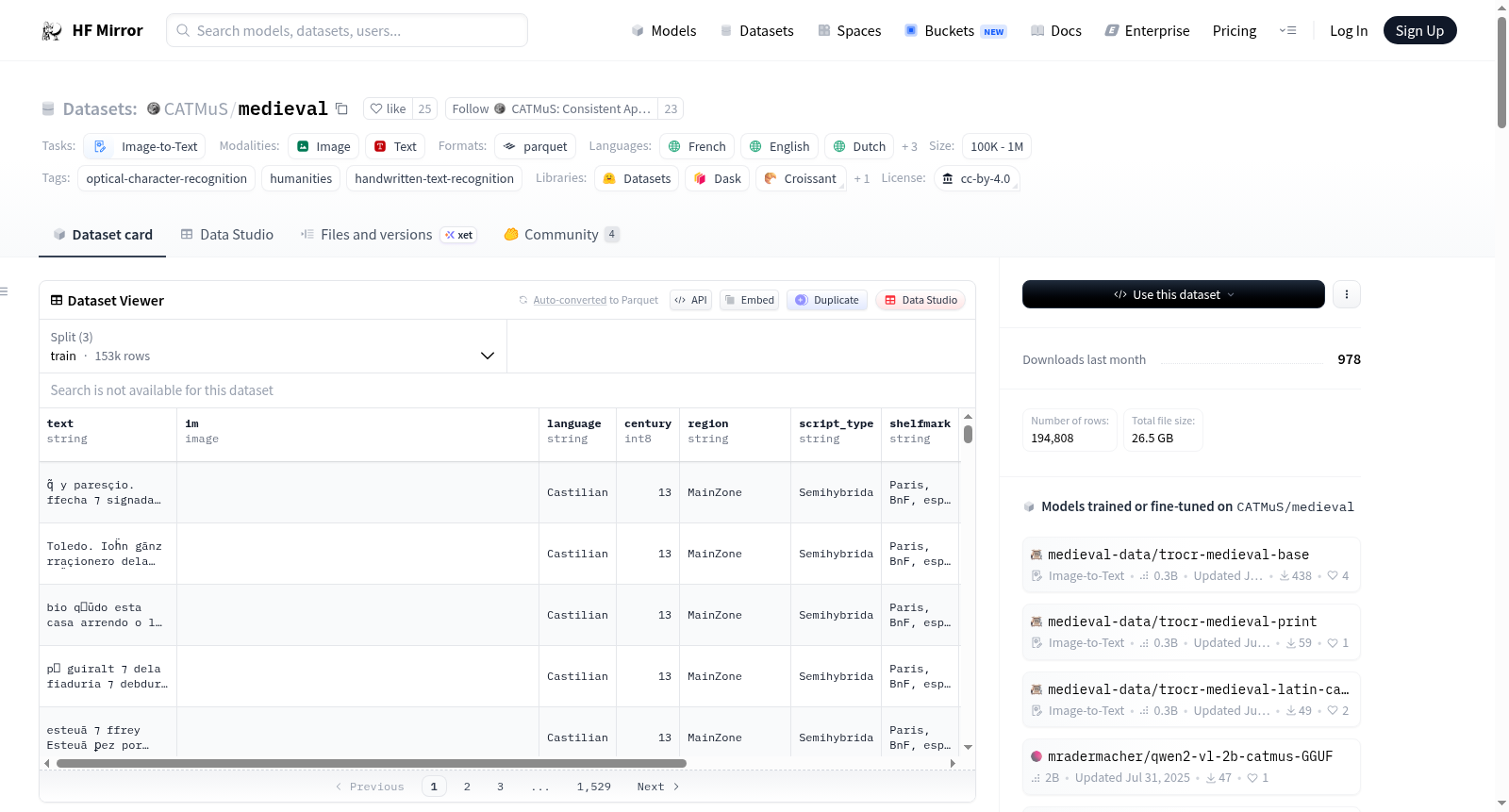
CATMuS/medieval
收藏数据集概述
数据集名称: CATMuS Medieval
许可证: CC-BY-4.0
任务类别:
- 图像到文本
语言:
- 法语
- 英语
- 荷兰语
- 意大利语
- 西班牙语
- 加泰罗尼亚语
数据集大小: 100K<n<1M
标签:
- 光学字符识别
- 人文学科
- 手写文本识别
数据集详情
开发目的:
- 提供一个统一的注释框架,用于中世纪手稿的注释实践。
- 为自动文本识别模型提供多维度的基准测试环境,包括生产世纪、语言、类型、脚本等丰富的元数据。
- 支持其他任务的基准测试,如脚本分类或日期分类。
- 探索与计算机视觉和数字古文字学相关的基于行的任务,如生成方法。
数据集构成:
- 超过200份手稿和古抄本
- 涵盖10种不同语言
- 包含超过160,000行文本和500万字符
- 时间跨度从8世纪到16世纪
数据集特点:
- 旨在解决中世纪手稿转录标准多样性带来的挑战,提供一个全面的基准,用于评估历史来源的HTR模型。
数据集使用
直接用途:
- 手写文本识别
- 日期分类
- 脚本分类
超出范围的用途:
- 文本到图像
数据集结构
- 数据通过
load_dataset("CATMuS/medieval")加载 - 数据可以根据每个手稿在训练、验证和测试集之间进行90/5/5的分割
- 图像位于
im列,文本位于text列
数据集来源和注释
数据集创建者: Thibault Clérice
资金支持: BnF Datalab, Biblissima +, DIM PAMIR
注释者:
- Ariane Pinche
- Thibault Clérice
- Alix Chagué
- Jean-Baptiste Camps
- Malamatenia Vlachou-Efstathiou
- Matthias Gille Levenson
- Olivier Brisville-Fertin
- Franz Fischer
- Michael Gervers
- Agnès Boutreux
- Avery Manton
- Simon Gabay
- Patricia OConnor
- Wouter Haverals
- Mike Kestemont
- Caroline Vandyck
- Benjamin Kiessling
数据集偏差、风险和限制
- 数据偏向于古法语、中荷兰语和西班牙语,特别是14世纪。
- 只有拉丁语在所有世纪都有代表性,其他接近拉丁语覆盖范围的语言是古法语。
- 只有一个文档是古英语。
引用信息
BibTeX: tex @unpublished{clerice:hal-04453952, TITLE = {{CATMuS Medieval: A multilingual large-scale cross-century dataset in Latin script for handwritten text recognition and beyond}}, AUTHOR = {Cl{e}rice, Thibault and Pinche, Ariane and Vlachou-Efstathiou, Malamatenia and Chagu{e}, Alix and Camps, Jean-Baptiste and Gille-Levenson, Matthias and Brisville-Fertin, Olivier and Fischer, Franz and Gervers, Michaels and Boutreux, Agn{`e}s and Manton, Avery and Gabay, Simon and OConnor, Patricia and Haverals, Wouter and Kestemont, Mike and Vandyck, Caroline and Kiessling, Benjamin}, URL = {https://inria.hal.science/hal-04453952}, NOTE = {working paper or preprint}, YEAR = {2024}, MONTH = Feb, KEYWORDS = {Historical sources ; medieval manuscripts ; Latin scripts ; benchmarking dataset ; multilingual ; handwritten text recognition}, PDF = {https://inria.hal.science/hal-04453952/file/ICDAR24___CATMUS_Medieval-1.pdf}, HAL_ID = {hal-04453952}, HAL_VERSION = {v1}, }
APA:
Thibault Clérice, Ariane Pinche, Malamatenia Vlachou-Efstathiou, Alix Chagué, Jean-Baptiste Camps, et al.. CATMuS Medieval: A multilingual large-scale cross-century dataset in Latin script for handwritten text recognition and beyond. 2024. ⟨hal-04453952⟩