slaying
收藏Hugging Face2026-05-06 更新2026-05-07 收录
下载链接:
https://huggingface.co/datasets/slaying-neurips-submission/slaying
下载链接
链接失效反馈官方服务:
资源简介:
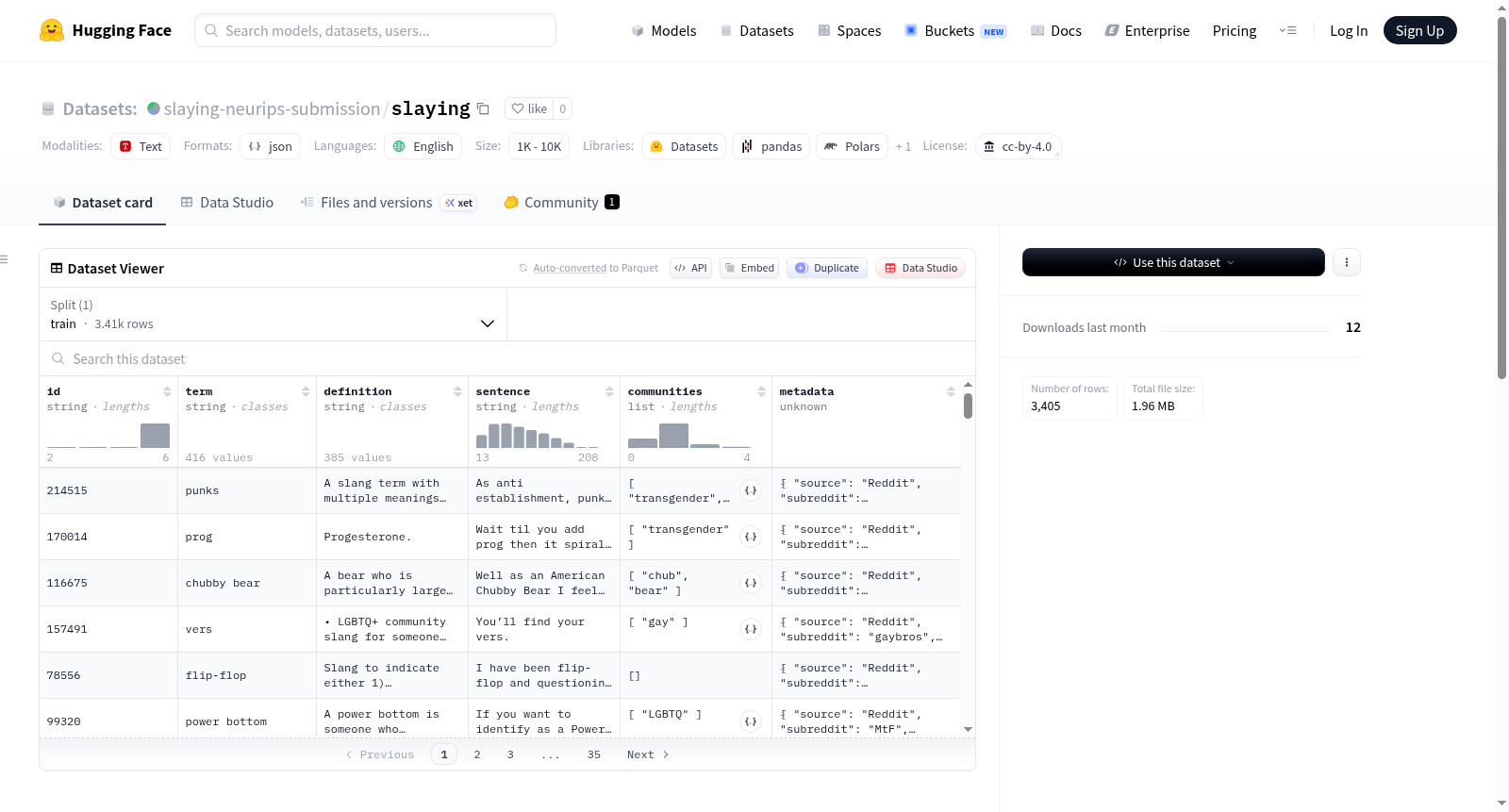
SLAyiNG是一个多样且经过社区验证的酷儿俚语数据集,旨在为学术研究提供丰富的酷儿俚语资源。数据集包含以下字段:`id`(唯一标识符)、`term`(酷儿俚语术语,来源包括GSSO、lgbtDB、Wiktionary和Chew Inclusive Terminology Glossary)、`definition`(术语定义,部分术语包含多个定义,以项目符号分隔)、`sentence`(使用该术语的例句)、`communities`(与术语相关的酷儿社区,通过GSSO和Wiktionary映射)以及`metadata`(来源元数据,如OpenSubtitles的标题和IMDb ID、Reddit的子版块和日期、播客的标题等)。数据集规模介于1,000到10,000条之间,适用于自然语言处理、社会语言学等研究领域。数据集的使用受限于非商业学术研究用途,并禁止用于强化对LGBTQ+社区的刻板印象或传播歧视性言论。
SLAyiNG is a diverse and community-validated dataset of queer slang, designed to provide a rich resource for academic research. The dataset includes the following fields: `id` (unique identifier), `term` (queer slang terms sourced from GSSO, lgbtDB, Wiktionary, and Chew Inclusive Terminology Glossary), `definition` (term definitions, with some terms containing multiple definitions separated by bullet points), `sentence` (example sentences using the term), `communities` (queer communities associated with the term, mapped via GSSO and Wiktionary), and `metadata` (source metadata such as OpenSubtitles titles and IMDb IDs, Reddit subreddits and dates, podcast titles, etc.). The dataset size ranges between 1,000 and 10,000 entries and is suitable for research areas like natural language processing and sociolinguistics. Usage is restricted to non-commercial academic purposes and prohibits reinforcing stereotypes or disseminating discriminatory speech against the LGBTQ+ community.
创建时间:
2026-05-04
原始信息汇总
SLAyiNG 数据集概述
基本信息
- 数据集名称:SLAyiNG
- 语言:英语
- 许可协议:Creative Commons Attribution 4.0 International(CC BY 4.0)
- 数据集规模:1,000 至 10,000 条样本
- 数据集描述:一个多样化且经社群验证的酷儿俚语数据集
数据结构
每条记录包含以下字段:
id:唯一标识符term:酷儿俚语词汇,来源包括 GSSO、lgbtDB、Wiktionary 和 Chew Inclusive Terminology Glossarydefinition:词汇定义,部分多义项以项目符号分隔sentence:依据定义使用该词汇的例句communities:与该词汇相关的酷儿社群(通过 GSSO 和 Wiktionary 映射)metadata:来源元数据- 来自 OpenSubtitles:包含标题和 IMDb ID
- 来自 Reddit:包含原始子版块和日期
- 来自播客:包含标题
许可与使用限制
- 词汇来源许可:
- GSSO:Apache License 2.0
- lgbtDB:CC0
- Chew Glossary:CC BY-NC-SA 4.0
- Wiktionary:CC-BY-SA
- 句子来源许可:
- OpenSubtitles Corpus:ODC-BY
- 播客和 Reddit 的简短摘录:保留各自创作者和平台的版权
- 衍生元数据与注释:在法律许可范围内,以 CC BY 4.0 发布
- 使用目的:仅限非商业学术研究用途
使用准则
- 本数据集禁止用于强化或延续针对 LGBTQ+ 社群的刻板印象
- 数据中的术语或句子不得用于宣扬跨性别恐惧、同性恋恐惧、种族主义、厌女或其他偏见言论
搜集汇总
数据集介绍
构建方式
SLAyiNG数据集通过整合来自GSSO、lgbtDB、Wiktionary及Chew包容性术语表等多个权威词源,系统性地收录了多元性别与性倾向相关的俚语词汇。每个条目均包含术语、定义、例句、关联社群及元数据,其中定义以分点形式呈现多义项,例句则从OpenSubtitles语料库、Reddit讨论与播客转录文本中精炼提取,确保语义与语境的真实对应。元数据标注了来源标题、IMDb编号、子版块及日期等信息,构建过程严格遵循各来源的许可协议,并最终在CC BY 4.0许可下发布,专供非商业学术研究使用。
特点
该数据集的核心特色在于其多样性与社区验证机制。术语来源跨越学术分类、社区词库及开放百科,覆盖了广泛且鲜有记载的酷儿俚语,而例句的多源采集则呈现了自然语言在真实社交场景中的动态使用。尤为突出的是,数据集通过关联术语对应的具体社群,映射了语言演变与群体身份之间的深刻联结,同时依托社区参与确保语义的准确性与文化敏感性,避免了主流语言资源中对边缘表达的遗漏或曲解。
使用方法
研究人员可直接利用SLAyiNG进行酷儿语言学的定量与定性分析,例如探究俚语在跨平台语料中的分布模式、语义演变轨迹或社群特异性表达。数据集以结构化的JSON或CSV格式提供,支持通过术语、社群或元数据字段进行过滤与检索,便于聚焦特定子集。使用时需注意遵循CC BY 4.0许可条款,并严禁将其用于强化对LGBTQ+群体的刻板印象或歧视性目的,确保学术研究的伦理合规性。
背景与挑战
背景概述
在语言学和计算社会科学交叉领域,对边缘化社群语言变体的系统性研究长期面临数据匮乏的困境。SLAyiNG数据集于2023年由多学科研究者共同创建,整合了GSSO、lgbtDB、Wiktionary及Chew Inclusive Terminology Glossary等权威词源,旨在构建首个经社群验证的酷儿俚语语料库。该数据集覆盖约数千条精心标注的术语,每条包含定义、上下文例句、关联社群及元数据(如影视字幕来源的IMDb编号、Reddit子版块及播客标题)。作为语言资源与人工智能伦理研究的重要基石,SLAyiNG填补了自然语言处理中酷儿语言表征的系统性空白,为消除算法偏见、促进包容性技术发展提供了关键训练与评测基准。
当前挑战
SLAyiNG面临的核心挑战在于双维度困境:首先,领域内长期存在非规范用语与主流语言模型的语义鸿沟,既有NLP系统对酷儿俚语的识别准确率极低,且易因训练数据偏差强化对LGBTQ+社群的刻板印象;其次,数据构建过程中需平衡伦理合规与语料多样性,如从Reddit、播客等渠道获取例句时需严格遵循原始创作者及平台的知识产权协议,同时避免术语定义受主流文化殖民——每个条目均需经社群成员验证以确保语义的在地性与流动性。此外,跨来源的术语歧义消解(如同一词汇在不同语境下承载截然不同的身份认同含义)对标注一致性构成严峻考验。
常用场景
经典使用场景
在自然语言处理与社会语言学交叉研究的前沿阵地,SLAyiNG数据集为探索多元性别与性取向群体(LGBTQ+)的俚语现象提供了标准化的语料资源。该数据集被广泛应用于语义理解、情感分析及社会身份识别任务中,研究者借助其包含的术语、定义、上下文例句及社群标签,能够精准捕捉特定语词在酷儿文化语境中的动态语义演变与语用特征。同时,通过映射多源词汇表(如GSSO、lgbtDB)及媒体来源(如OpenSubtitles、Reddit),该数据集还支持跨对话环境的语言差异比较,成为分析网络社群语言创新与身份表达机制的关键工具。
实际应用
该数据集在现实场景中主要服务于三大智能系统建设:面向社交平台的仇恨言论过滤与包容性内容推荐需借助其标注偏差;数字人文学项目中的文本考古分析可依赖其术语演变序列追踪语言流变痕迹;而面向LGBTQ+社群的语言教育与文化传承工具,则利用标准句例生成场景化教学材料。此外,医疗问诊系统的术语规范化亦可通过该数据集完成语用适应调整,确保性少数群体在健康咨询中获得无歧视交互体验。这些应用共同体现了数据驱动方法在促进边缘群体文化可见性与交流效率方面的实用价值。
衍生相关工作
围绕SLAyiNG数据集已衍生出一系列具有影响力的研究工作:基于其社区标签与术语映射关系,学者构建了首个动态冷却语义网络(QueerNet),实现了俚语演变传播路径的可视化分析;受其多源例句标注启发,研究者开发了语境感知的跨平台语用对齐模型,用以追踪同一术语在社交媒体与文学文本中的语义分化;此外,该数据集为《自然语言处理中的性别包容性评估框架》提供了核心验证基准,并推动“具有文化敏感性的语言预训练策略”专项课题立项。这些衍生工作共同将数据资源转化为理论创新与算法突破的催化剂。
以上内容由遇见数据集搜集并总结生成


