visual-layer/oxford-iiit-pet-vl-enriched
收藏Hugging Face2024-09-18 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/visual-layer/oxford-iiit-pet-vl-enriched
下载链接
链接失效反馈官方服务:
资源简介:
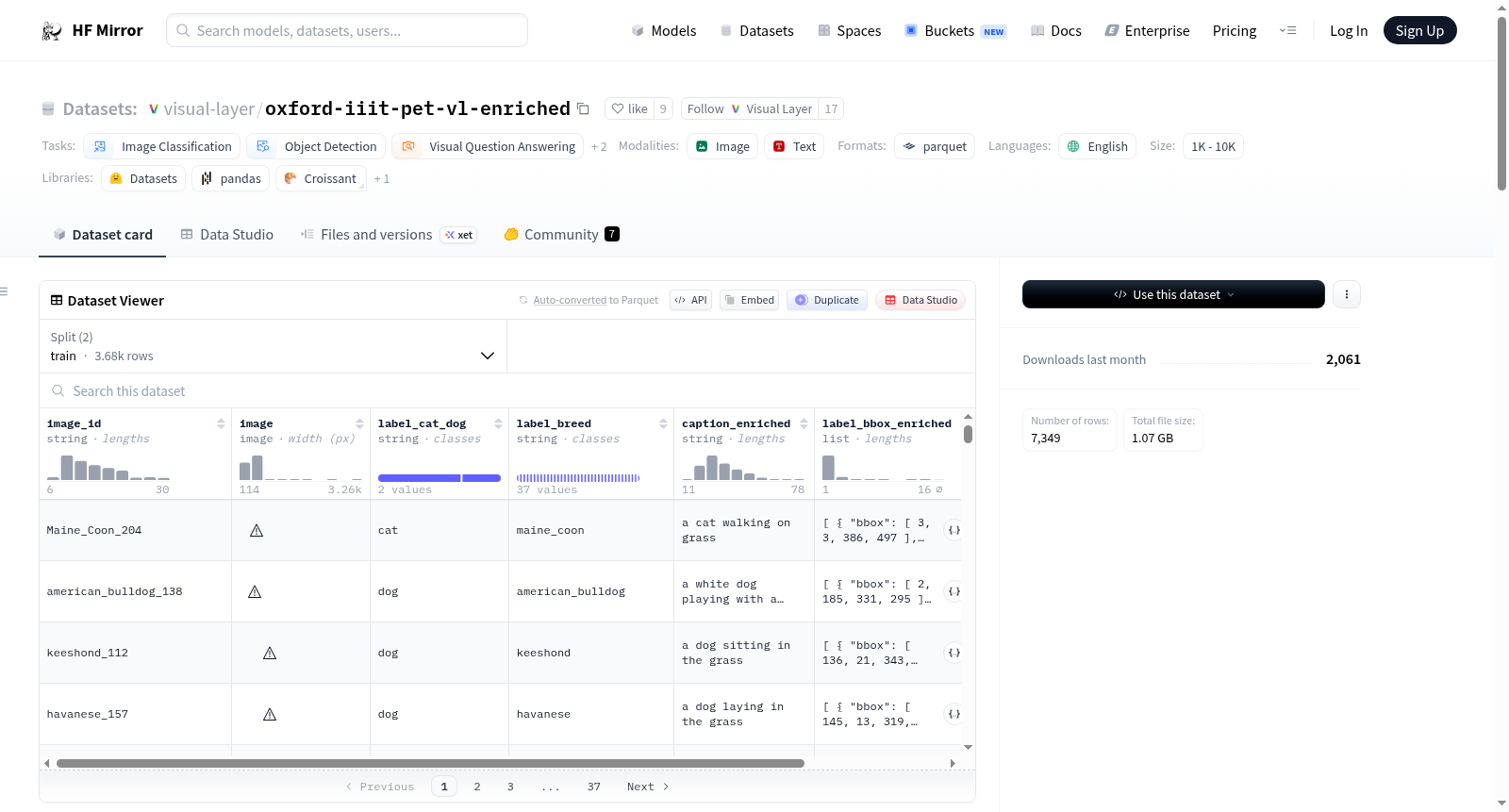
Oxford-IIIT-Pets-VL-Enriched数据集是Oxford IIIT Pets数据集的增强版本,包含了图像描述、边界框和标签问题等信息。数据集包含6列数据,分别是image_id(图像的唯一标识符)、image(图像数据)、label_cat_dog(图像标签,表示是猫还是狗)、label_breed(猫或狗的品种标签,包含37个品种)、label_bbox_enriched(增强的边界框标签,包含边界框坐标、置信度和标签)和caption_enriched(增强的图像描述)。此外,数据集还包含了图像质量问题的信息,如重复、错误标签、暗、模糊、亮和异常图像。该数据集可以用于图像分类、目标检测、图像检索和视觉问答等任务。
An enriched version of the Oxford IIIT Pets Dataset with image caption, bounding boxes, and label issues! With this additional information, the Oxford IIIT Pet dataset can be extended to various tasks such as image retrieval or visual question answering. The dataset consists of 6 columns: `image_id`, `image`, `label_cat_dog`, `label_breed`, `label_bbox_enriched`, `caption_enriched`, and `issues`. The dataset is split into train and test sets, containing 3680 and 3669 samples respectively.
提供机构:
visual-layer
原始信息汇总
Oxford-IIIT-Pets-VL-Enriched 数据集概述
数据集描述
- 语言: 英语 (en)
- 任务类别: 图像分类、目标检测
- 配置: 默认配置
- 数据文件:
- 训练集:
data/train-* - 测试集:
data/test-*
- 训练集:
- 数据文件:
数据集信息
-
特征:
image_id: 图像的唯一标识符,类型为字符串。image: 图像数据,类型为PIL图像。label_cat_dog: 图像标签,表示是猫还是狗,类型为字符串。label_breed: 图像标签,表示猫或狗的品种,包含37种猫和狗的品种,类型为字符串。caption_enriched: 图像的丰富描述,类型为字符串。label_bbox_enriched: 图像的丰富标签,包含边界框坐标、置信度和标签,类型为列表。bbox: 边界框坐标,类型为整数序列。label: 边界框标签,类型为字符串。
issues: 图像的质量问题,类型为列表。confidence: 置信度,类型为浮点数。description: 描述,类型为空。issue_type: 问题类型,类型为字符串。
-
数据集分割:
- 训练集:
- 字节数: 148786604.0
- 样本数: 3680
- 测试集:
- 字节数: 133006684.375
- 样本数: 3669
- 训练集:
-
数据集大小:
- 下载大小: 281256366 字节
- 数据集总大小: 281793288.375 字节
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,数据集的丰富性直接影响模型性能的边界。Oxford-IIIT-Pets-VL-Enriched 数据集以经典的牛津IIIT宠物数据集为基础,通过先进的深度学习技术进行了系统性增强。其构建过程首先保留了原始数据集的图像样本及猫狗类别、品种标签,随后利用定制的YOLOv8模型为每张图像生成了包含坐标与标签的边界框标注,同时借助BLIP2图像描述模型为图像配以文本描述。此外,数据集还引入了自动化质量检测机制,识别出重复、模糊、过暗等潜在问题样本,从而在原始数据之上构建了一个多模态、高信息密度的增强版本。
特点
该数据集的核心特点在于其多维度的标注信息与内置的质量控制。它不仅提供了基础的图像分类标签,如猫狗类别及37个具体品种,更整合了物体检测所需的边界框坐标及其置信度,以及由先进模型生成的图像描述文本,实现了视觉与语言模态的有机联结。尤为突出的是,数据集内嵌了系统自动检测的各类质量问题标识,如重复图像、标签错误、图像模糊等,为研究者提供了数据清洗与筛选的直接依据,显著提升了数据集的可靠性与实用性,使其能够灵活支撑图像分类、目标检测、视觉问答及跨模态检索等多种下游任务。
使用方法
为便于学术研究与工程开发,该数据集已集成于Hugging Face生态系统。用户可通过`datasets`库直接加载,使用简洁的代码`load_dataset("visual-layer/oxford-iiit-pet-vl-enriched")`即可访问训练集与测试集。加载后的数据以结构化字段呈现,包括图像、各类标签、描述文本及问题标识,研究者可根据任务需求灵活提取相应字段。例如,进行目标检测时可调用`label_bbox_enriched`字段,而开展图文跨模态研究则可结合`image`与`caption_enriched`。数据集还提供了在Visual Layer平台上的交互式可视化入口,支持用户直观浏览数据分布与标注详情,无需注册即可使用,极大便利了数据的探索与分析过程。
背景与挑战
背景概述
在计算机视觉领域,细粒度图像分类与多模态学习的研究持续深化,对高质量标注数据的需求日益迫切。牛津大学视觉几何组与印度理工学院于2012年联合发布的Oxford-IIIT Pets数据集,作为宠物图像识别的经典基准,涵盖了37个猫狗品种,为物种与品种分类提供了重要支撑。Visual Layer团队在此基础上,通过集成YOLOv8模型生成的边界框、BLIP2模型生成的文本描述以及数据质量检测结果,构建了增强版本Oxford-IIIT-Pets-VL-Enriched。这一扩充不仅延续了原数据集在细粒度识别中的影响力,更将其适用范围拓展至目标检测、视觉问答及跨模态理解等前沿任务,推动了多模态人工智能模型的发展。
当前挑战
该数据集旨在解决细粒度视觉分类与跨模态对齐中的关键挑战,包括如何在有限样本下准确区分外观相似的宠物品种,以及如何实现图像区域与文本描述之间的语义关联。在构建过程中,团队面临多重技术难题:利用预训练模型自动生成边界框与描述时,需确保标注的精确性与上下文相关性;同时,识别并处理图像中的重复、模糊、标注错误等质量问题,要求开发鲁棒的检测算法以维护数据集的整体洁净度与可靠性。这些挑战共同指向了自动化数据增强与质量控制在实际应用中的复杂性与必要性。
常用场景
经典使用场景
在计算机视觉领域,宠物图像识别与分类任务常面临数据标注不完善的挑战。Oxford-IIIT-Pets-VL-Enriched数据集凭借其丰富的标注信息,成为多模态视觉任务研究的经典基准。该数据集不仅提供原始图像与品种标签,更通过增强的边界框与自然语言描述,支持图像分类、目标检测及视觉问答等综合性实验,为模型在细粒度识别与跨模态理解方面的性能评估提供了标准化平台。
解决学术问题
该数据集有效应对了细粒度视觉分类中标注稀疏性与模态割裂的学术难题。通过集成边界框坐标与文本描述,它促进了目标定位与语义关联的联合学习,为多任务学习框架提供了验证基础。同时,其内置的数据质量问题标注助力于噪声鲁棒性研究,推动了数据清洗与模型泛化能力的理论探索,在提升视觉系统可解释性方面具有显著意义。
衍生相关工作
围绕该数据集的增强特性,已衍生出多项经典研究工作。例如,基于其边界框与文本描述的多模态对齐模型,推动了视觉-语言预训练技术的演进;利用标签问题进行的噪声学习研究,催生了数据质量评估的新方法;同时,该数据集常作为基准,用于验证跨模态检索与生成式视觉描述模型的性能,持续激发着细粒度视觉理解领域的创新。
以上内容由遇见数据集搜集并总结生成


