ifeval-like-data
收藏Hugging Face2024-10-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/argilla/ifeval-like-data
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含由Qwen/Qwen2.5-72B-Instruct模型生成的指令-响应对,模仿了google/IFEval数据集的风格,并通过lm-evaluation-harness进行了正确性验证。数据集分为两个子集:'default'包含50k未过滤的行,可能包含冲突的指令和错误的响应;'filtered'包含经过过滤的行,适合微调。数据集主要用于文本生成任务,语言为英语。
This dataset comprises instruction-response pairs generated by the Qwen/Qwen2.5-72B-Instruct model, which mirrors the style of the google/IFEval dataset and was validated for correctness via the lm-evaluation-harness framework. The dataset is split into two subsets: the 'default' subset includes 50k unfiltered rows that may contain conflicting instructions and erroneous responses, while the 'filtered' subset consists of pre-filtered rows suitable for fine-tuning. This dataset is primarily intended for text generation tasks and features content in English.
创建时间:
2024-10-01
原始信息汇总
IFEval Like Data 数据集概述
数据集信息
许可证
- 许可证名称: qwen
- 许可证链接: https://huggingface.co/Qwen/Qwen2.5-72B-Instruct/blob/main/LICENSE
数据集大小
- 数据集大小: 1K<n<10K
配置信息
配置: default
- 特征:
- instruction: string
- response: string
- model_name: string
- instruction_id_list: sequence[string]
- distilabel_metadata: struct
- raw_input_i_f_eval_kwargs_assignator_0: list
- content: string
- role: string
- raw_output_i_f_eval_kwargs_assignator_0: string
- raw_input_i_f_eval_kwargs_assignator_0: list
- kwargs: string
- 分割:
- train:
- 字节数: 449730370
- 样本数: 50000
- train:
- 下载大小: 53292952
- 数据集大小: 449730370
配置: filtered
- 特征:
- key: int64
- prompt: string
- response: string
- instruction_id_list: sequence[string]
- kwargs: list
- capital_frequency: int64
- capital_relation: string
- end_phrase: string
- first_word: string
- forbidden_words: sequence[string]
- frequency: int64
- keyword: string
- keywords: sequence[string]
- let_frequency: int64
- let_relation: string
- letter: string
- nth_paragraph: int64
- num_bullets: int64
- num_highlights: int64
- num_paragraphs: int64
- num_placeholders: int64
- num_sections: int64
- num_sentences: int64
- num_words: int64
- postscript_marker: string
- relation: string
- section_spliter: string
- prompt_level_strict_acc: bool
- inst_level_strict_acc: sequence[bool]
- prompt_level_loose_acc: bool
- inst_level_loose_acc: sequence[bool]
- 分割:
- train:
- 字节数: 10543956.482782291
- 样本数: 5614
- train:
- 下载大小: 3228407
- 数据集大小: 10543956.482782291
配置文件
- 配置: default
- 数据文件:
- 分割: train
- 路径: data/train-*
- 分割: train
- 数据文件:
- 配置: filtered
- 数据文件:
- 分割: train
- 路径: filtered/train-*
- 分割: train
- 数据文件:
标签
- synthetic
- distilabel
- rlaif
任务类别
- text-generation
语言
- en
数据集名称
- IFEval Like Data
搜集汇总
数据集介绍
构建方式
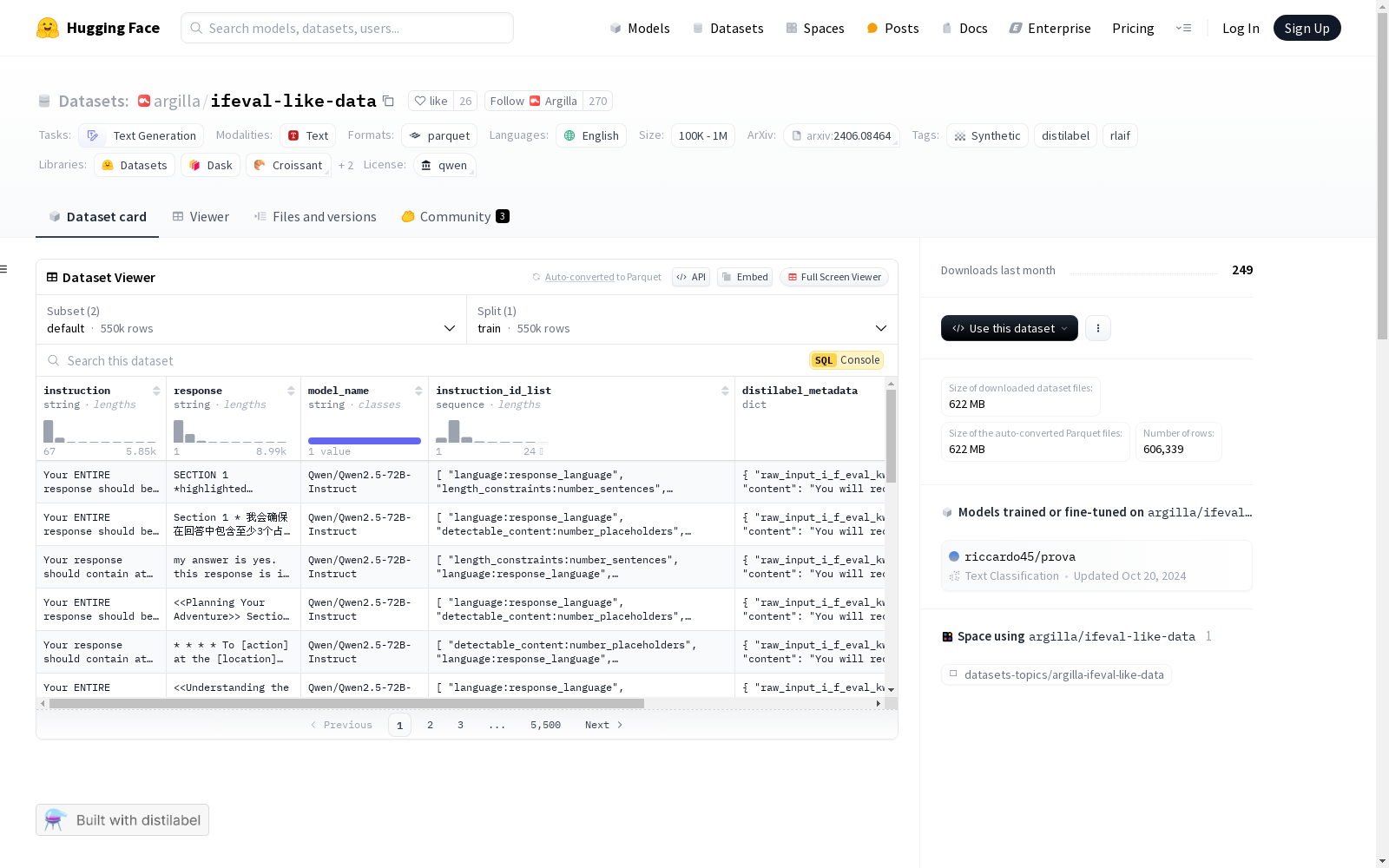
IFEval Like Data 数据集通过使用 Qwen/Qwen2.5-72B-Instruct 模型生成指令-响应对,并借鉴了 google/IFEval 数据集的风格。数据生成过程中采用了 MagPie 提示技术,并结合了系统提示,生成了包含冲突指令和错误响应的 550k 条未过滤数据。随后,通过 lm-evaluation-harness 工具对生成的数据进行正确性验证,并筛选出符合 IFEval 指标 prompt_level_strict_acc 为 True 的数据,形成过滤后的子集。
特点
该数据集包含两个子集:default 和 filtered。default 子集包含 550k 条未过滤的指令-响应对,其中可能包含冲突指令和错误响应;filtered 子集则经过严格筛选,仅保留符合 IFEval 严格准确性标准的数据,适用于模型微调。数据集的结构清晰,每条数据包含指令、响应、模型名称、指令 ID 列表等字段,便于进一步分析和使用。
使用方法
用户可以通过 Hugging Face 的 datasets 库加载该数据集,使用 load_dataset 函数即可轻松获取数据。数据集提供了默认配置和过滤配置,用户可根据需求选择加载。此外,数据集还提供了 pipeline.yaml 文件和脚本,用户可通过 distilabel CLI 工具运行脚本,复现数据生成和过滤的完整流程,便于自定义数据生成和筛选条件。
背景与挑战
背景概述
IFEval Like Data数据集是由Argilla团队基于Qwen/Qwen2.5-72B-Instruct模型生成的指令-响应对数据集,旨在模拟Google的IFEval数据集风格。该数据集的核心研究问题在于评估和验证大型语言模型在遵循复杂指令时的表现,特别是在处理包含冲突指令和多样化约束条件的情况下。通过使用lm-evaluation-harness工具进行验证,该数据集为自然语言生成任务提供了丰富的测试场景。其创建时间为2024年,主要研究人员包括Zhangchen Xu等,相关研究论文《Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing》进一步阐述了数据生成的技术细节。该数据集对自然语言处理领域,尤其是指令遵循和模型对齐研究,具有重要的参考价值。
当前挑战
IFEval Like Data数据集在构建过程中面临多重挑战。首先,生成符合复杂指令的响应需要模型具备高度的语义理解和生成能力,尤其是在处理冲突指令时,模型必须能够准确识别并执行优先级较高的指令。其次,数据集的过滤过程依赖于IFEval指标,确保响应在严格标准下的准确性,这对数据质量提出了极高要求。此外,数据集的构建还涉及大规模合成数据的生成与验证,如何在保证多样性的同时避免生成错误或不一致的响应,是另一个技术难点。这些挑战不仅反映了当前自然语言生成任务的复杂性,也为未来研究提供了改进方向。
常用场景
经典使用场景
在自然语言处理领域,ifeval-like-data数据集主要用于评估和优化大语言模型在复杂指令生成任务中的表现。该数据集通过模拟真实场景中的指令-响应对,帮助研究者深入分析模型在处理多约束条件时的能力。特别是在评估模型对语言、格式、内容等多维度约束的遵循程度时,该数据集提供了丰富的测试案例。
实际应用
在实际应用中,ifeval-like-data数据集被广泛用于大语言模型的微调和性能评估。通过使用该数据集,开发者能够训练模型更好地理解和执行复杂的用户指令,提升模型在客服、内容生成、自动化写作等场景中的表现。此外,该数据集还可用于生成符合特定格式和内容要求的文本,满足实际业务需求。
衍生相关工作
ifeval-like-data数据集衍生了一系列相关研究工作,特别是在大语言模型的指令遵循和约束生成领域。基于该数据集,研究者提出了多种改进模型生成能力的算法和框架,如基于强化学习的指令优化方法和多约束条件下的生成策略。这些工作进一步推动了自然语言生成技术的发展,并为后续研究提供了重要的参考。
以上内容由遇见数据集搜集并总结生成


