issai/RAGBench_Kazakh
收藏Hugging Face2026-04-30 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/issai/RAGBench_Kazakh
下载链接
链接失效反馈官方服务:
资源简介:
RAGBench_Kazakh是原始RAGBench基准的哈萨克语机器翻译版本,旨在评估检索增强生成(RAG)系统,重点关注模型如何使用检索到的上下文生成接地气的答案。数据集包含来自多个RAGBench子集的测试集,覆盖生物医学研究、通用知识、法律文档、客户支持和金融等领域。每个样本包括一个问题、一组检索到的文档和一个参考答案,所有内容均为哈萨克语翻译,同时保留了原始结构以便进行跨语言比较。数据集共包含11,431个样本,覆盖12个子集,如COVID-19研究相关的生物医学问答、合同文档的法律问答、客户支持和幻觉相关的问答等。
RAGBench_Kazakh is a machine-translated Kazakh version of the original RAGBench benchmark, designed to evaluate retrieval-augmented generation (RAG) systems, focusing on how well models use retrieved context to produce grounded answers. The dataset is built from the test splits of multiple RAGBench subsets covering domains such as biomedical research, general knowledge, legal documents, customer support, and finance. Each example includes a question, retrieved documents, and a reference answer translated into Kazakh, while preserving the original structure for cross-lingual comparison. The dataset contains 11,431 examples in total, covering 12 subsets such as biomedical QA focused on COVID-19 research, legal QA over contract documents, customer-support and hallucination-focused QA, etc.
提供机构:
issai
搜集汇总
数据集介绍
构建方式
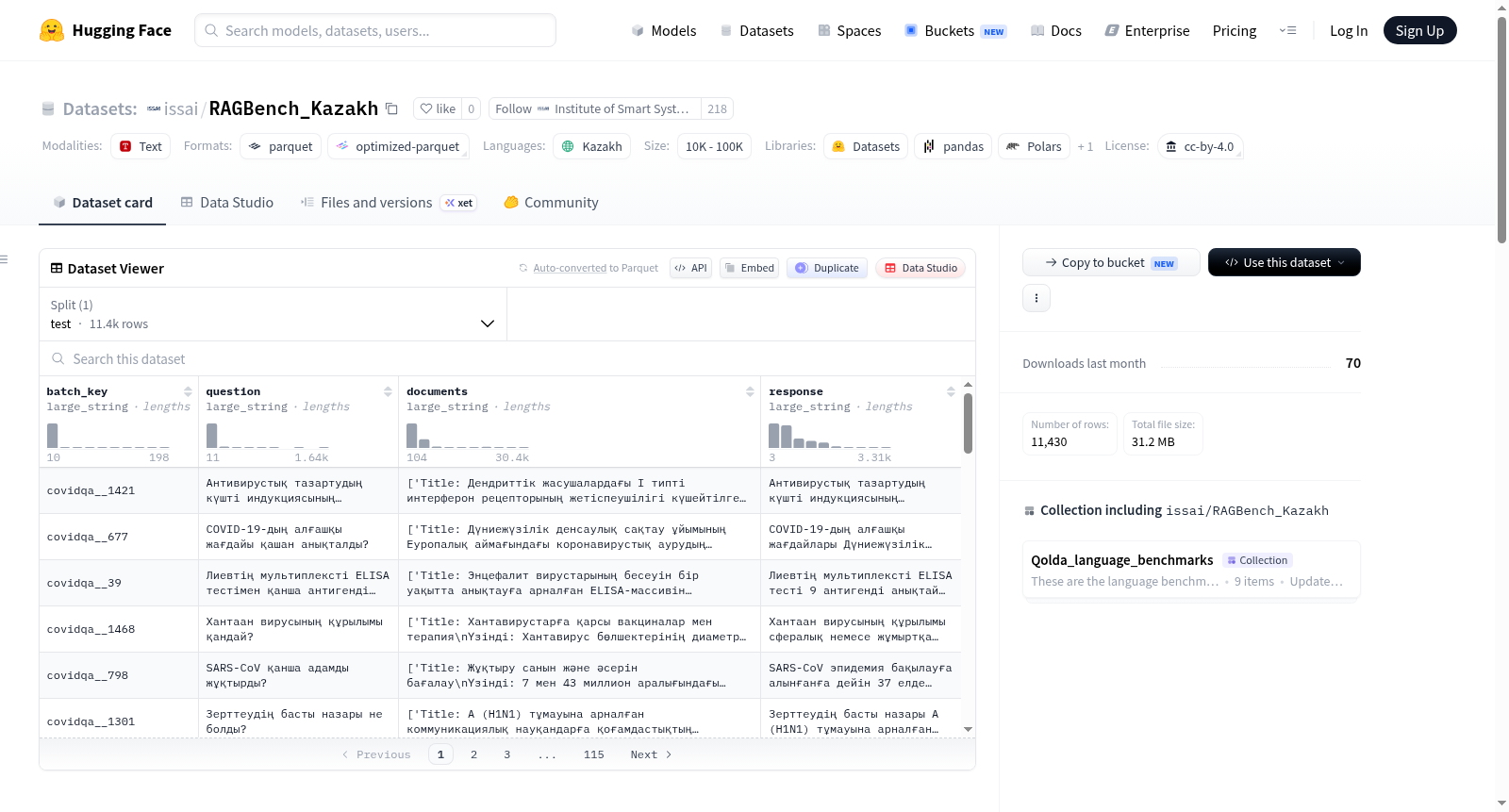
RAGBench_Kazakh 数据集是基于原始 RAGBench 基准通过机器翻译技术构建的哈萨克语版本。原始 RAGBench 涵盖了生物医学研究、通用知识、法律文档、客户支持与金融等多个领域的子集,而本数据集仅选取各子集的测试集(test split)部分,将其中的问题、检索文档和参考答案全部翻译为哈萨克语。所有子集的测试样本被合并为一个统一的数据集,共包含 11,431 个样本,每个样本保留了原始子集标识符(batch_key),以支持跨语言对比与细粒度评估。
特点
该数据集的核心特点在于其多领域覆盖与跨语言一致性。它整合了 12 个不同子集,包括 COVID 问答(covidqa)、法律合同问答(cuad)、金融数值推理(finqa)等,覆盖生物医学、法律、金融、技术支持等多样化场景。每个样本包含哈萨克语的问题、检索文档和参考答案,文档以序列化字符串列表形式存储,保留了原始检索结构。此外,数据集仅包含测试集样本,且通过 batch_key 字段支持按子集分组,便于进行领域特定的 RAG 系统评估。
使用方法
RAGBench_Kazakh 的使用方法灵活多样,主要面向检索增强生成(RAG)系统的评估。用户可直接加载默认配置下的 test 分割,利用 question、documents 和 response 字段构建评估任务。通过 batch_key 的前缀(如 covidqa__)可筛选特定子集进行领域针对性测试。数据集以 Parquet 格式存储,兼容 Hugging Face Datasets 库,支持快速加载与批处理。推荐在评估时采用标准的 RAG 评价指标,如答案准确率、检索相关性等,并结合多领域结果进行综合性能分析。
背景与挑战
背景概述
RAGBench_Kazakh 是一个面向哈萨克语的检索增强生成(RAG)系统评估基准,由 Galileo AI 团队基于原始 RAGBench 数据集通过机器翻译构建而成。该数据集的创建旨在弥补低资源语言在 RAG 评估领域的空白,核心研究问题在于衡量模型在哈萨克语环境下利用检索上下文生成 grounded 答案的能力。其涵盖了生物医学研究、通用知识、法律文档、客户支持与金融等领域的12个子集,总计11,431个样本,为跨语言 RAG 性能对比提供了标准化测试平台。自发布以来,RAGBench_Kazakh 对低资源语言的自然语言处理研究产生了重要影响,推动了多语言 RAG 系统评估的发展。
当前挑战
RAGBench_Kazakh 面临的核心挑战包括:1) 所解决的领域问题——在低资源语言如哈萨克语中,现有 RAG 基准多聚焦于英语等高资源语言,缺乏针对该语言的系统评测数据,导致建模无法准确评估模型在非主流语言上的检索与生成质量;2) 构建过程中,机器翻译可能引入语义失真或文化不适应性,例如医学术语或法律概念的翻译偏差,且原始英语中的多跳推理或数值推理任务在翻译后可能丢失逻辑结构,从而影响评估的可靠性。此外,不同子集间的领域差异(如金融与法律)要求翻译模型具备高度泛化能力,进一步增加了数据质量控制的难度。
常用场景
经典使用场景
RAGBench_Kazakh作为检索增强生成(RAG)系统的评测基准,其经典使用场景在于评估模型在哈萨克语环境下对检索文档的利用能力与生成接地答案的质量。研究者通常基于该数据集中的多领域问题、检索文档及参考答案,衡量RAG系统在答题正确性、上下文相关性及抗幻觉能力上的表现。通过对比模型输出与人工标注答案,可系统性地分析检索-生成流水线的薄弱环节,为优化跨语言信息检索与文本生成提供标准化测试平台。
衍生相关工作
基于RAGBench_Kazakh衍生的经典工作包括:针对低资源语言的检索器增强训练方案,通过对比该数据集与原始英文基准的差距改进词嵌入对齐技术;以及提出针对哈萨克语的文档重排序策略,减少多跳推理中的上下文冗余。此外,部分研究利用其涵盖的12个子集设计跨领域元学习架构,推动生成模型在未见任务上的零样本适应能力。
数据集最近研究
最新研究方向
RAGBench_Kazakh作为机器翻译的哈萨克语版本基准数据集,填补了中亚语言在检索增强生成(RAG)评估中的空白。该数据集覆盖生物医学、法律、金融等12个领域,与多跳推理、幻觉检测等前沿研究方向紧密相关。鉴于哈萨克语在数字资源中的稀缺性,该数据集的发布推动了低资源语言RAG系统的发展,通过跨语言对比分析,为多语言信息检索和生成任务提供了标准化评估框架。其模型能力评估对于提升中亚地区智能客服、法律咨询等应用场景的可靠性具有重要意义。
以上内容由遇见数据集搜集并总结生成


