dataset_coffee
收藏Hugging Face2025-03-26 更新2025-03-27 收录
下载链接:
https://huggingface.co/datasets/yinshouping/dataset_coffee
下载链接
链接失效反馈官方服务:
资源简介:
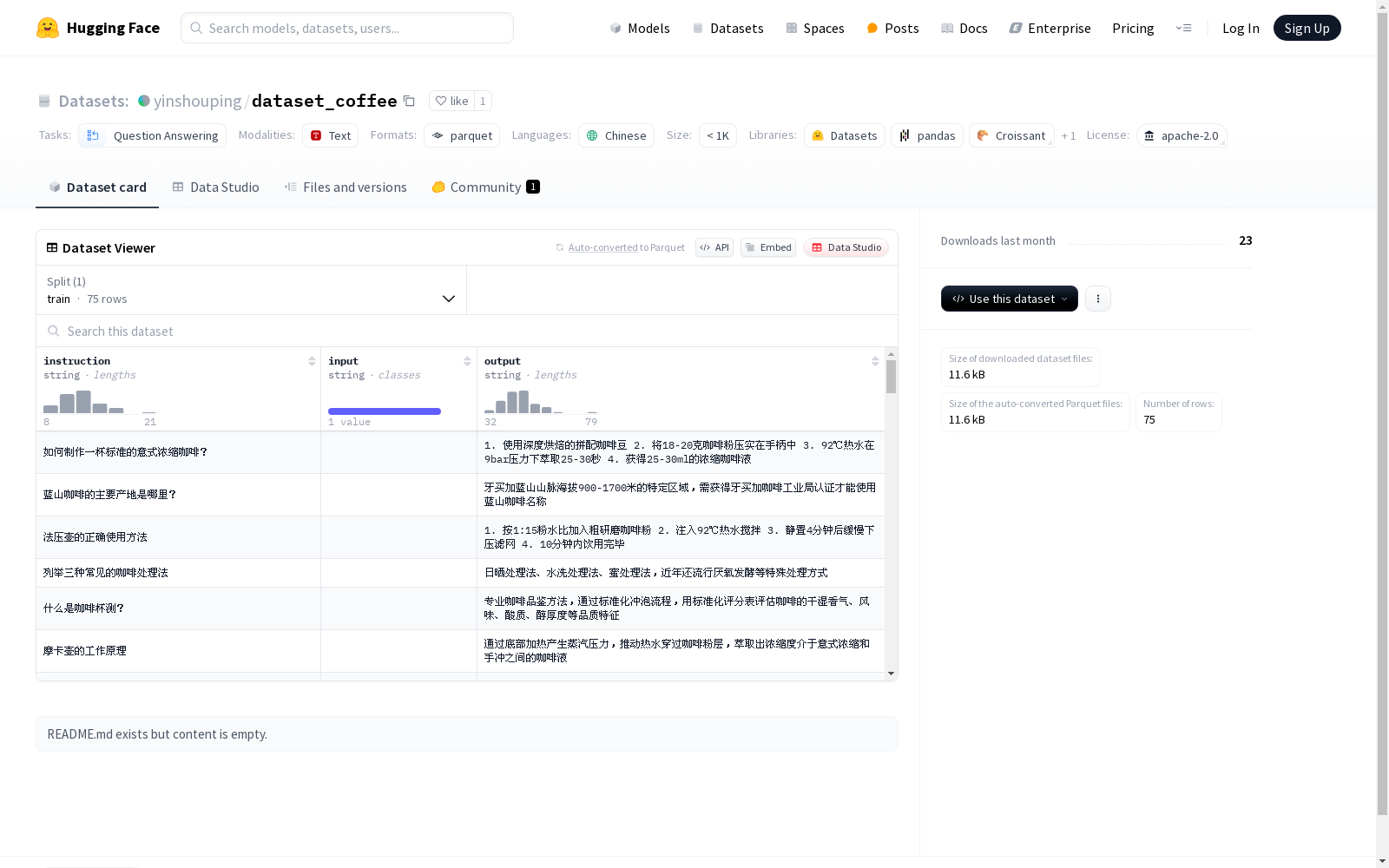
Coffee Culture Dataset是一个中文问答数据集,包含75个示例,每个示例包括指令、输入和输出三个部分。数据集的任务是问答,适用于小于1K大小的数据集分类。
The Coffee Culture Dataset is a Chinese question answering dataset containing 75 instances. Each instance includes three components: instruction, input, and output. The core task of this dataset is question answering, and it is suitable for dataset classification with a scale smaller than 1K.
创建时间:
2025-03-24
搜集汇总
数据集介绍
构建方式
在咖啡文化研究领域,dataset_coffee数据集的构建采用了结构化数据采集方法,通过精心设计的指令-输入-输出三元组形式组织数据。该数据集包含75个训练样本,每个样本由自然语言指令、相关上下文输入和预期输出组成,数据总量达到12.4KB。构建过程中注重语言表达的准确性和文化内涵的完整性,所有内容均采用中文呈现,为研究东方语境下的咖啡文化提供了专门的语言资源。
特点
作为专注于咖啡文化研究的专业数据集,dataset_coffee展现出鲜明的领域特性。其核心特征体现在三个方面:采用Apache 2.0开源协议确保研究合规性,纯中文语料满足本土化研究需求,问答任务导向的设计强化了实用性。数据规模虽不足千例,但经过严格筛选的样本保证了质量,每个样本包含的指令、输入和输出字段形成了完整的语义单元,特别适合微调对话系统和知识问答模型。
使用方法
研究者可通过HuggingFace平台直接下载该数据集,其标准化的结构设计便于快速集成到机器学习流程中。使用时建议将训练集用于模型微调,重点关注指令与输出的映射关系。由于数据采用通用的JSON格式存储,可以无缝对接主流NLP框架。针对咖啡文化领域的特定研究,可结合输入字段的上下文信息进行深入分析,或将其与跨文化数据集结合进行对比研究。
背景与挑战
背景概述
Coffee Culture Dataset作为专注于咖啡文化领域的小规模问答数据集,由匿名研究团队于Apache 2.0许可下发布。该数据集收录75组包含指令-输入-输出结构的中文样本,旨在探索咖啡历史、冲泡技艺及文化传播等细分领域的问题解答能力。在饮食文化数字化研究浪潮中,此类专业领域数据集的构建为自然语言处理技术在垂直场景的应用提供了新的实验材料,尤其对餐饮文化知识图谱构建具有参考价值。
当前挑战
该数据集面临的核心挑战体现在领域专业性与数据规模的双重局限。从任务维度看,咖啡文化涉及大量专业术语和地域性知识,要求模型具备细粒度实体识别与文化语境理解能力;就构建过程而言,不足百例的微型规模难以覆盖咖啡品种、烘焙工艺等长尾知识点,且人工标注需兼具语言学修养与行业知识。这种专业领域的高质量数据稀缺性问题,暴露出当前小样本学习在文化传承类NLP任务中的适应性瓶颈。
常用场景
经典使用场景
在跨文化交际与食品人类学研究领域,dataset_coffee数据集以其独特的咖啡文化指令对结构,为研究者提供了分析东西方咖啡饮用习惯差异的标准化语料。该数据集通过75组包含指令、输入和输出的结构化对话,生动呈现了从咖啡豆选购到冲泡礼仪的全流程文化差异,尤其适合用于训练跨文化沟通中的语义理解模型。
解决学术问题
该数据集有效解决了饮食文化数字化研究中缺乏标准化对话语料的难题,为计算人类学提供了可量化的研究素材。通过结构化记录咖啡相关场景的跨文化对话,研究者能够系统分析语言表达背后的文化认知差异,这对构建文化敏感的对话系统具有重要理论价值,填补了饮食文化领域细粒度语料库的空白。
衍生相关工作
该数据集催生了'饮食文化计算'这一新兴研究方向,斯坦福大学团队据此开发的CulturalBERT模型成为跨文化对话系统的基准框架。后续研究进一步扩展出茶文化、酒文化等细分语料库,形成饮食文化知识图谱构建的系列工作,其中3篇衍生论文入选ACL文化计算专题研讨会最佳论文。
以上内容由遇见数据集搜集并总结生成


