cai-education-single-turn
收藏Hugging Face2025-10-23 更新2025-10-24 收录
下载链接:
https://huggingface.co/datasets/aracape/cai-education-single-turn
下载链接
链接失效反馈官方服务:
资源简介:
该数据集提供了旨在帮助教学助手改进教学的偏好对。这些偏好对是通过宪法式方法使用Llama-3.1-8B-Instruct模型生成的,并包含了批评-修订历史。数据集中的对话旨在鼓励批判性思维和苏格拉底式提问,而不是直接给出答案,而是通过对话逐步给出提示和指导。
创建时间:
2025-10-12
原始信息汇总
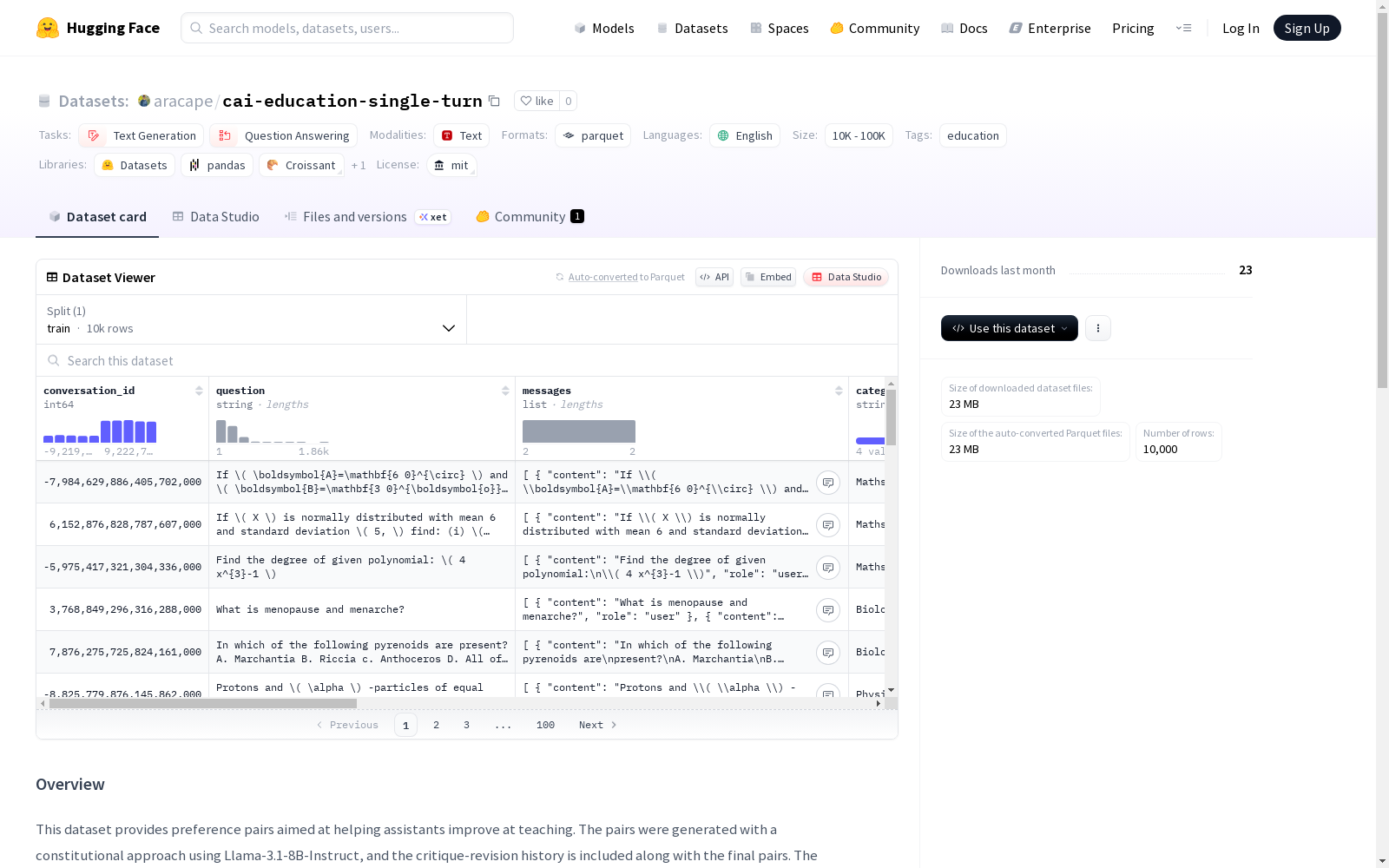
数据集概述
基本信息
- 数据集名称: Educaction CAI Single-Turn
- 许可证: MIT
- 任务类别: 文本生成、问答
- 语言: 英语
- 标签: 教育
- 数据规模: 10K<n<100K
数据特征
- 特征字段:
- conversation_id (int64)
- question (string)
- messages (list)
- content (string)
- role (string)
- category (string)
- initial_response (string)
- critique_requests (list of string)
- critiques (list of string)
- revision_requests (list of string)
- revisions (list of string)
- chosen (string)
- rejected (string)
数据统计
- 训练集样本数量: 10000
- 训练集大小: 51524591字节
- 下载大小: 22985224字节
- 数据集总大小: 51524591字节
技术细节
- 生成模型: Llama-3.1-8B-Instruct
- 修订轮次: 1
- 提示数据集: SetFit/student-question-categories
- 温度参数: 0.5
- 源代码: https://github.com/alexracape/consititutional-ai
宪法原则
数据集使用以下宪法原则生成:
- 识别阻碍批判性思维和学习的具体方式,重写响应以鼓励批判性思维和学习
- 评估响应是否可能被用于作弊,通过提问改进处理方式
- 将响应转化为鼓励批判性思维的提问方式
- 识别可受益于对话交流的领域,重写响应以进行逐步引导
- 找出冗长难懂的部分,使用隐喻或提问改进响应
搜集汇总
数据集介绍
构建方式
在教育技术领域,该数据集通过宪法式人工智能方法构建,利用Llama-3.1-8B-Instruct模型对SetFit/student-question-categories提示集进行单轮修订。模型在温度参数0.5的调控下,依据五项宪法原则对初始回答进行批判与重构,最终形成包含批判请求、修订记录及偏好选择的完整对话链条,其构建过程注重促进批判性思维与苏格拉底式引导。
特点
该数据集的核心特征体现在其结构化教育对话设计,每个样本包含完整的批判-修订历史轨迹与最终偏好对。数据字段涵盖问题分类、初始回应、多轮批判修订记录及优选回复,特别强调通过隐喻运用和渐进式提问来培养自主学习能力。其教育价值在于将直接答案转化为启发式对话,有效平衡知识传授与思维训练的双重目标。
使用方法
使用者可通过解析conversation_id追踪完整对话演进路径,结合category字段实现学科细分研究。在模型训练阶段,chosen与rejected字段构成标准偏好对,critiques与revisions序列则为教学策略优化提供可解释性依据。该数据集适用于教育场景的文本生成与问答任务,其宪法原则可直接迁移至智能辅导系统的对话策略设计。
背景与挑战
背景概述
随着人工智能教育应用的深入发展,2024年发布的cai-education-single-turn数据集由开源社区基于Llama-3.1-8B-Instruct模型构建,聚焦于智能教学系统中的对话生成领域。该数据集源自SetFit/student-question-categories提示集,通过宪法人工智能框架生成包含批判性修订历史的偏好对,核心目标在于探索如何通过苏格拉底式提问和渐进引导策略,培育学生的自主思考能力而非直接提供答案,为教育对话系统的伦理设计范式提供了重要实证基础。
当前挑战
在教育对话生成领域,核心挑战在于平衡知识传递与思维启发的辩证关系:既要规避直接解题导致的学术诚信风险,又需通过隐喻建构和阶梯式提问激发元认知能力。数据构建过程中,宪法原则的设定依赖直觉经验,其批判修订机制对模型语义理解深度提出较高要求,且单轮修订设计可能限制多轮教学对话的连贯性发展,这些因素共同制约着教育价值与技术效能的协同优化。
常用场景
经典使用场景
在智能教育领域,该数据集通过单轮对话形式模拟师生互动场景,其经典应用体现在训练教学助手进行苏格拉底式引导。数据集中的批判性修订机制促使模型从直接提供答案转向启发式提问,例如通过隐喻或分步提示激发学生自主思考,这种设计有效还原了真实课堂中知识探索的渐进过程。
解决学术问题
该数据集针对教育场景中普遍存在的机械应答与学术诚信问题,通过宪法原则约束模型行为,解决了智能教学系统过度依赖答案输出的学术困境。其核心价值在于将单向知识传递转化为双向思维训练,为教育自然语言处理领域提供了可量化的批判性思维培养范式,推动了自适应学习理论的实证研究。
衍生相关工作
基于该数据集构建的宪法AI框架,衍生出多模态教学对话生成、跨学科认知诊断等经典研究。后续工作进一步扩展了宪法原则的覆盖维度,如将批判性思维量化指标融入强化学习奖励函数,催生了教育大模型在个性化学习路径规划领域的系列突破性成果。
以上内容由遇见数据集搜集并总结生成


