tahsinsoyak/gsm8k-en-finetune
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/tahsinsoyak/gsm8k-en-finetune
下载链接
链接失效反馈官方服务:
资源简介:
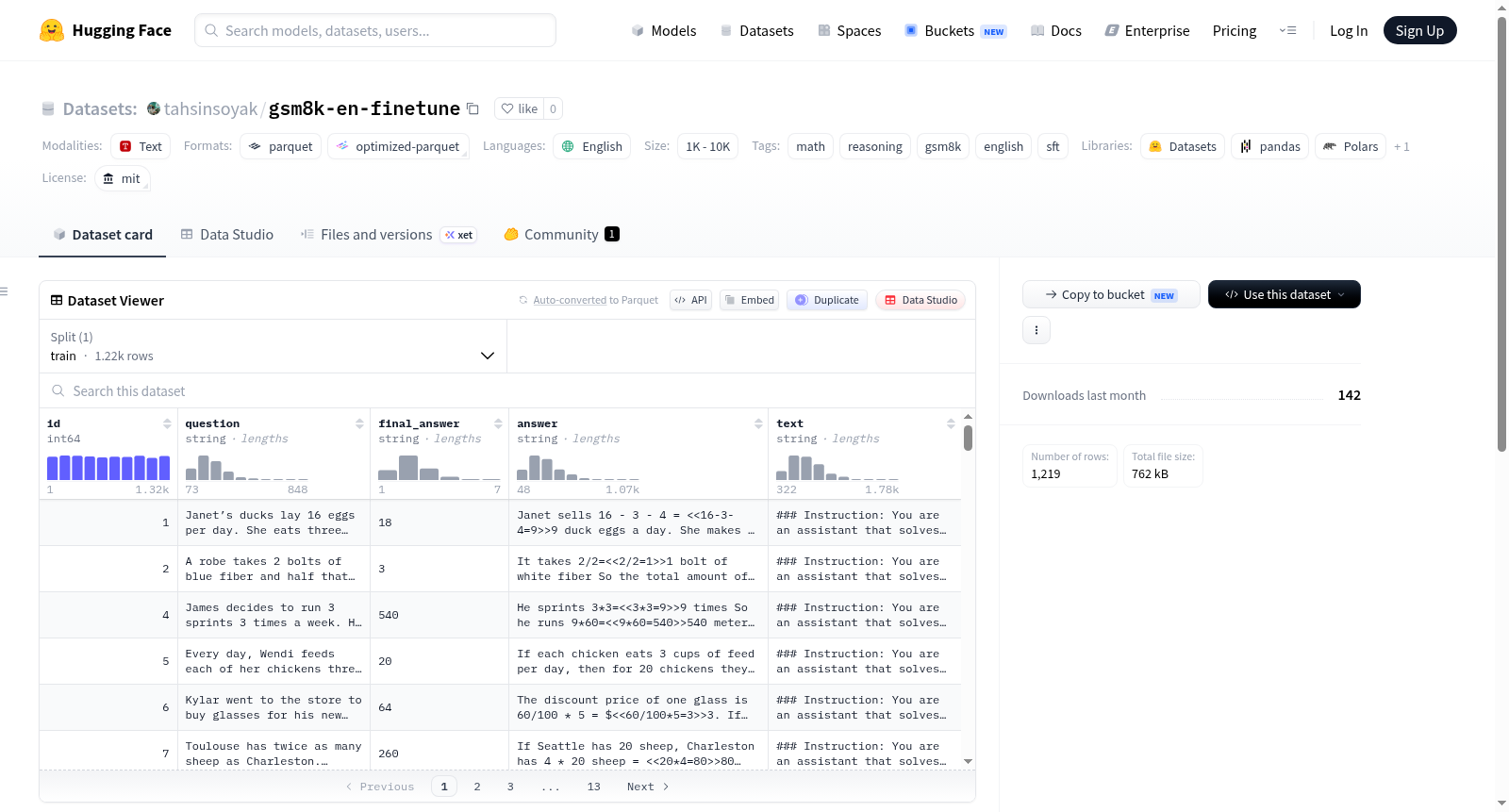
GSM8K-EN Finetune (SFT)是一个用于监督微调的英文数据集,来源于openai/gsm8k的test分割。为了与gsm8k-tr-finetune数据集完全匹配,保留了100个项目,以防止与tahsinsoyak/gsm8k-tr-benchmark或任何相同的英文基准数据集发生泄漏。数据集包含1219行数据,没有配置。数据模式包括id(原始索引)、question(问题)、answer(完整的逐步推理过程,以`#### <number>`结尾)、final_answer(仅数字最终答案)和text(为TRL SFTTrainer预构建的字符串)。
GSM8K-EN Finetune (SFT) is an English supervised fine-tuning split derived from the `test` split of `openai/gsm8k`. 100 items have been held out to match the `gsm8k-tr-finetune` dataset exactly, preventing leakage with the `tahsinsoyak/gsm8k-tr-benchmark` or any identical English benchmark. The dataset contains a single `train` split with 1219 rows and no configs. The schema includes id (original index in openai/gsm8k test split), question, answer (full step-by-step rationale ending with `#### <number>`), final_answer (numeric final answer only), and text (precomposed SFT string for TRL SFTTrainer).
提供机构:
tahsinsoyak
搜集汇总
数据集介绍
构建方式
GSM8K-EN Finetune数据集源自OpenAI发布的GSM8K测试集,经过精心筛选与重构,形成了一个专用于监督式微调(SFT)的英文数学推理语料库。构建过程中,从原始测试集中特意留置了100个样本,以确保与对应的土耳其语版本(gsm8k-tr-finetune)在数量上完全一致,并避免与任何英文基准测试集(如tahsinsoyak/gsm8k-tr-benchmark)发生数据泄露。最终数据集仅包含单一训练划分,共计1219条样本,未设置额外配置层级。
特点
该数据集的核心特点在于其精心设计的结构化字段,每条样本包含原始索引编号、逐步推理链条与最终数字答案,并预先生成了适用于TRL SFTTrainer的文本格式。答案字段提供了完整的逐步推理过程,以'####'标记结尾的数字为最终结果,极大地便利了模型对数学推理范式的学习。数据集规模虽小,但针对性强,专为提升语言模型在算术推理任务上的性能而构建,同时保持了与土耳其语版本的严格对齐。
使用方法
该数据集可直接用于Hugging Face生态下的监督式微调流程,尤其适配TRL库中的SFTTrainer。用户只需加载tahsinsoyak/gsm8k-en-finetune数据集,利用'text'字段作为输入目标对即可开展训练。若需更精细的控制,可借助'question'与'answer'字段构建自定义格式,或使用'final_answer'字段进行精简的答案预测任务。数据集已预先处理完毕,无需额外清洗或格式转换,显著降低了微调部署的门槛。
背景与挑战
背景概述
在自然语言处理与数学推理交叉领域中,大型语言模型在复杂数学问题求解上的能力评估与微调训练日益受到关注。GSM8K数据集作为数学推理领域的标杆之一,广泛用于衡量模型的数学语言理解与多步推理能力。GSM8K-EN Finetune数据集于近年由研究人员从OpenAI原始GSM8K测试集中衍生而来,专注于英文数学推理任务的监督微调。该数据集严格保留了1219条训练样本,并刻意扣留100条样本以避免与现有基准产生数据泄露,从而保障评估的公正性。其设计旨在为研究人员提供纯净、可控的微调数据,推动数学推理模型在零样本或少样本场景下的泛化能力提升,同时为多语言对齐研究(如与土耳其语GSM8K Finetune的对应)奠定基础。
当前挑战
该数据集所解决的核心领域挑战在于数学推理任务的监督微调中,模型常因训练数据与测试集分布不一致而导致性能瓶颈。具体而言,GSM8K-EN Finetune面临两大挑战:其一,数学问题本身要求模型具备多步推理与符号运算能力,在仅有千余条样本的情况下,如何有效引导模型学习通用推理策略而非记忆特定模式;其二,构建过程中需严格控制数据泄露风险,原始GSM8K测试集被分割为微调部分与保留基准,这一设计虽保障了评估独立性,却增加了数据稀疏性带来的过拟合风险。此外,对推理步骤(answer)与最终答案(final_answer)的分离标注要求模型同时输出中间推导与结果,进一步提升了训练难度。
常用场景
经典使用场景
在数学推理与自然语言处理的交叉领域,GSM8K-EN-Finetune数据集以其精炼的规模和结构化的标注格式,成为监督微调(SFT)场景中的标杆资源。该数据集源自OpenAI的GSM8K测试集,经过精心筛选和划分,保留了1219条高质量样本,每条数据均包含完整的多步推理链与最终数值答案。其经典用途在于训练大型语言模型(LLM)逐步解析数学应用题的能力,通过预组合的SFT文本格式,研究者可直接将其输入至TRL的SFTTrainer等工具,高效完成模型的指令微调与推理能力增强,尤其适合探究链式思维(Chain-of-Thought)的诱导机理。
实际应用
在实际部署中,GSM8K-EN-Finetune驱动的模型可广泛应用于教育科技领域的智能辅导系统。例如,它能够为学习者提供步骤化的数学解题指导,自动诊断错误推理节点并给出纠错建议,使个性化数学学习成为可能。在金融风控和决策支持场景中,经过该数据集微调的模型可对数值类规则进行逻辑解析,辅助完成如费用计算、税务推算等复杂的多步数值任务。此外,在人机交互界面中,它还能增强对话式AI的数学问答应答能力,使其在面对用户提出的应用题时,输出不仅准确且包含清晰推演过程的回答,提升用户信任度与交互体验。
衍生相关工作
该数据集的诞生直接衍生出诸如跨语言数学推理泛化、小样本场景下的推理蒸馏等前沿工作。研究者以其作为英文端对齐基准,结合其土耳其语版本gsm8k-tr-finetune,催生了探究语言无关推理表征的对比学习研究。同时,由于该数据集仅含1219条样本,它激发了在有限监督条件下提升推理效率的方法论创新,如基于结构化思维树(Tree-of-Thought)的微调策略、以及利用预训练知识进行推理链压缩的轻量化模型设计。此外,其标准化的SFT格式为后续的指令微调社区贡献了可复现的实验基线,推动了数学领域微调框架的规范化和透明化进程。
以上内容由遇见数据集搜集并总结生成


