nlcTables
收藏arXiv2025-04-22 更新2025-04-24 收录
下载链接:
https://github.com/SuDIS-ZJU/nlcTables
下载链接
链接失效反馈官方服务:
资源简介:
nlcTables是由浙江大学知识工程实验室构建的一个综合性的表格数据集,包含627个查询,涵盖NL-only、union、join和fuzzy条件。该数据集由22,080个候选表格和21,200个相关性标注组成,旨在促进自然语言条件下的表格发现研究。数据集覆盖了从1到69.5K行,最多33列的表格大小,为研究和评估表格发现方法提供了一个多样化的基准。
nlcTables is a comprehensive tabular dataset constructed by the Knowledge Engineering Laboratory of Zhejiang University. It includes 627 queries covering NL-only, union, join, and fuzzy conditions. Comprising 22,080 candidate tables and 21,200 relevance annotations, this dataset aims to facilitate research on table discovery under natural language conditions. The tables range in size from 1 to 69.5 thousand rows and up to 33 columns, providing a diverse benchmark for researching and evaluating table discovery methods.
提供机构:
浙江大学
创建时间:
2025-04-22
搜集汇总
数据集介绍
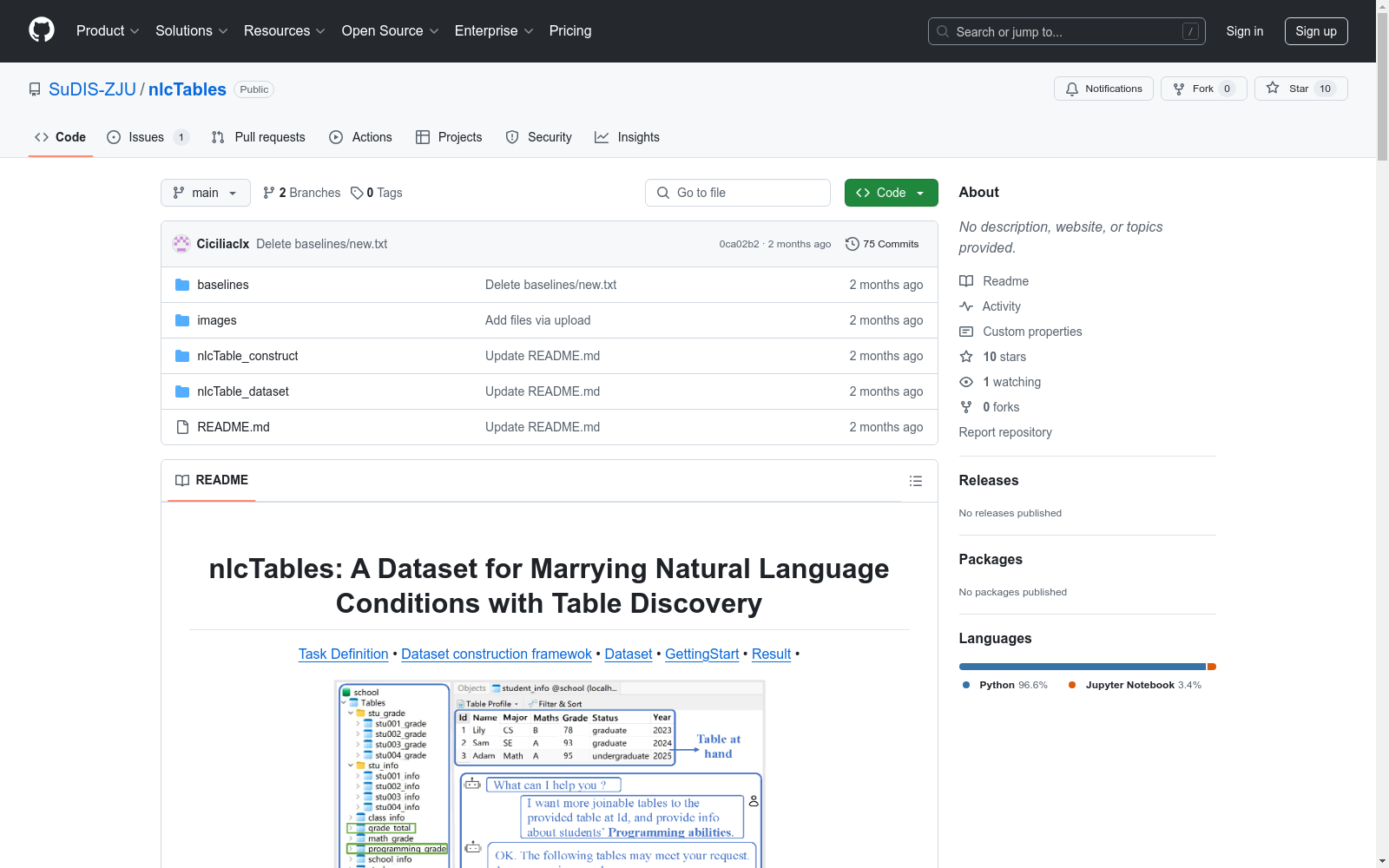
构建方式
nlcTables数据集通过多阶段流程构建,首先从Opendata、WebTable和GitTable等公开数据源收集表格数据,并应用严格的质量过滤标准(如行数≥50、列数≥8)。随后采用表格分割技术生成查询表与候选表,其中水平分割用于创建满足特定行条件的联合查询,垂直分割则用于生成可连接表。通过语义增强技术(如LLM驱动的列值转换)和基于Spider数据集的手动标注,最终形成包含627个查询、22,080个候选表和21,200条标注的基准数据集。
特点
该数据集首创性地融合了自然语言条件与表格发现任务,支持NL-only、联合、连接及混合条件等16种子类查询。其核心特点包括:1)规模性(平均表格行数543.9行,最大达69.5K行);2)多样性(覆盖教育、编程等多元主题及数值/日期等列类型);3)可配置性(通过调整pos_num/neg_num等参数灵活控制数据集规模)。特别提供的模糊版本(fz)通过语义增强模拟真实场景中的语义变异挑战。
使用方法
使用nlcTables需遵循三步流程:首先加载查询表与自然语言条件(如“查找可联合且包含数学成绩>90的表格”),随后调用检索系统匹配结构相似度与语义条件。评估时采用P@k/R@k/NDCG@k指标,重点关注前20个结果的排序质量。对于混合条件查询,需分阶段处理多条件组合。数据集提供Small/Medium/Large三种规模配置,并建议结合HNSW等索引技术提升效率。
背景与挑战
背景概述
nlcTables数据集由浙江大学区块链与数据安全国家重点实验室的研究团队于2025年提出,旨在解决表格数据发现领域的关键问题。随着政府、学术界和企业开放表格数据的快速增长,传统基于关键词或查询表格的发现方法存在检索结果过载、语义理解不足等局限性。该数据集创新性地提出了自然语言条件表格发现(NL-conditional Table Discovery)任务,允许用户通过结合查询表格和自然语言条件来精确定位目标表格。作为首个支持三元关系(查询表格-自然语言条件-候选表格)评估的基准数据集,nlcTables包含627个多样化查询、22,080个候选表格和21,200条相关性标注,覆盖联合、连接和模糊条件等16种子类别,为语义表格检索领域提供了重要的研究基础设施。
当前挑战
该数据集面临双重挑战:在领域问题层面,需要解决自然语言条件与表格结构的跨模态对齐问题,包括数值/日期列的条件解析、混合条件的复合推理等复杂场景,现有方法在NDCG@10指标上平均性能不足0.45;在构建过程层面,挑战体现在大规模高质量标注的生成(需平衡正负样本比例至1:21.8)、语义增强表格的验证(通过LLM转换后人工校验),以及跨源表格的标准化处理(来自OpenData、WebTable等多源数据的模式对齐)。特别地,模糊查询版本(nlcTables-*-fz)对现有方法的语义敏感性提出了更高要求,在表连接任务中导致基线模型性能下降达37%。
常用场景
经典使用场景
在数据湖和开放数据集的背景下,nlcTables数据集为自然语言条件与表格发现结合的创新研究提供了重要支持。该数据集通过整合查询表格与自然语言条件,使得研究人员能够在复杂的表格检索场景中测试和优化算法。例如,在教育数据分析中,教师可以通过提供学生信息表格和自然语言条件(如“成绩高于90分的学生”)来精确检索相关表格,从而显著提升数据检索的效率和准确性。
解决学术问题
nlcTables数据集解决了表格发现领域中的关键学术问题,特别是在自然语言条件与表格检索结合的复杂场景中。传统方法仅依赖关键词或查询表格进行检索,难以满足用户对精确性和语义理解的需求。该数据集通过引入自然语言条件,填补了这一空白,为研究表格语义理解、多模态信息检索和交互式数据发现提供了重要基础。其意义在于推动了表格检索技术向更智能、更用户友好的方向发展。
衍生相关工作
nlcTables数据集衍生了一系列经典研究工作,特别是在自然语言处理与表格检索的交叉领域。基于该数据集的研究推动了表格语义表示学习、多模态检索模型和交互式数据发现系统的发展。例如,一些研究利用预训练语言模型(如BERT)增强表格的语义理解能力,而另一些工作则探索了如何通过自然语言条件优化表格检索的排序算法。这些工作共同推动了表格发现技术的进步,并为未来的研究提供了丰富的基础。
以上内容由遇见数据集搜集并总结生成


