venra
收藏资源简介:
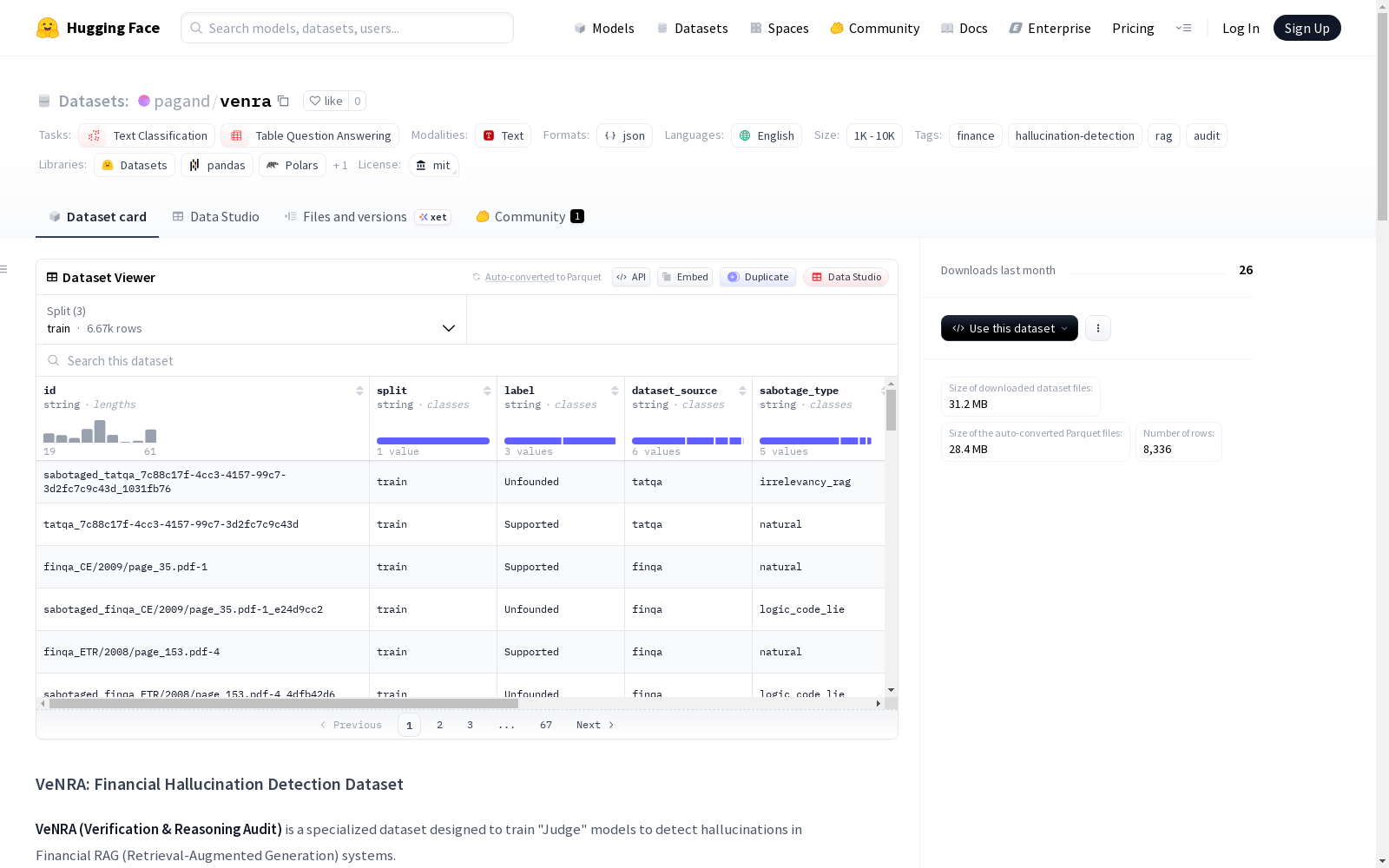
VeNRA(验证与推理审计)是一个专门设计用于训练“法官”模型以检测金融RAG(检索增强生成)系统中幻觉的数据集。该数据集采用对抗模拟的方法,通过程序化破坏高质量金融记录来科学重建RAG系统在生产中表现出的特定认知失败。数据集针对金融代理的特定失败模式,包括逻辑错误、邻居陷阱和不相关性。每个(查询、上下文、跟踪、句子)元组被严格分类为支持、无根据或一般三类。数据集整合并转换了五个顶级金融QA数据集,通过不同的攻击向量创建错误样本。总记录数为8,351条,分为训练集6,683条、验证集834条和测试集834条。数据集经过严格的教师审计协议,确保样本质量,其中约95%自动验证,4%通过AI代理验证,1%人工验证。适用于金融领域的文本分类和表格问答任务。
VeNRA (Verification and Reasoning Audit) is a dataset specifically designed to train "judge" models for detecting hallucinations in financial Retrieval-Augmented Generation (RAG) systems. This dataset adopts an adversarial simulation approach to scientifically reconstruct the specific cognitive failures exhibited by RAG systems in production environments by programmatically corrupting high-quality financial records. The dataset targets specific failure modes of financial AI Agents, including logical errors, neighbor traps, and irrelevance. Each (query, context, trace, sentence) tuple is strictly categorized into three classes: supported, ungrounded, and generic. The dataset integrates and transforms five top-tier financial QA datasets to create erroneous samples via diverse attack vectors. The total number of records is 8,351, which are split into 6,683 training samples, 834 validation samples, and 834 test samples. The dataset has undergone a rigorous teacher-led audit protocol to ensure sample quality, with approximately 95% automatically verified, 4% verified via AI Agents, and 1% manually verified. It is applicable to text classification and tabular question answering tasks in the financial domain.
VeNRA 金融幻觉检测数据集概述
数据集简介
VeNRA(Verification & Reasoning Audit)是一个专门设计用于训练“法官”模型以检测金融RAG(检索增强生成)系统中幻觉的专业数据集。该数据集采用对抗模拟理念,通过对高质量的“黄金”财务记录进行程序化篡改,科学地重建了RAG系统在生产环境中表现出的特定认知故障。
核心特点
- 对抗模拟哲学:区别于依赖“生成幻觉”(要求大语言模型虚构错误)的数据集,本数据集通过模拟金融智能体的特定故障模式来构建。
- 故障模式:
- 逻辑错误:代码是有效的Python,但输入是错误的(例如,将2022年收入与2023年收入互换)。
- 邻域陷阱:模型检索到正确的表格,但提取了紧邻正确单元格的单元格(例如,错误的年份、错误的指标)。
- 无关性:检索结果在语义上相似,但在时间或上下文上无关(例如,用2022年的文档回答2023年的问题)。
数据分类
数据集将每个(查询,上下文,追踪,句子)元组严格分类为以下三类之一:
| 标签 | 定义 | 验证逻辑 |
|---|---|---|
| Supported(有据可依) | 句子在逻辑上遵循所提供的文本上下文和/或代码追踪。 | 证据 → 结论 |
| Unfounded(无据可依) | 句子与证据相矛盾、错误归因数字、包含逻辑错误,或与特定用户查询无关。 | 证据 ⊥ 结论 |
| General(常识) | 句子不在提供的上下文中,但属于被广泛接受的金融公理(例如,“美国证券交易委员会监管美国市场”)。 | 世界知识(零样本) |
数据来源与构成
数据集整合并转换了五个顶级金融问答数据集:
| 源数据集 | 在VeNRA中的作用 | 转换/攻击向量 |
|---|---|---|
| FinQA | 逻辑核心 | 追踪逻辑破坏:将Lisp风格的程序转译为Python,然后通过程序化交换输入变量来创建“代码谎言”。 |
| TAT-QA | 混合核心 | 邻域陷阱:使用表格坐标将正确答案与相邻单元格(行/列偏移)交换。 |
| FinanceBench | 语义核心 | 无关性攻击:交换问题(例如,年份2021 → 2020),同时保留原始证据,以模拟RAG检索失败。 |
| TruthfulQA | 公理核心 | 噪声注入:向“常识”行中注入随机的金融文本块,迫使模型忽略无关上下文。 |
| Phantom | 长上下文 | 大海捞针:验证从长达20k个标记的10-K文档中进行有效/无效提取。 |
数据集统计
- 总记录数:8,351
- 训练集:6,683
- 验证集:834
- 测试集:834
质量保证(“教师-审计员”协议)
数据集中的每个“被破坏”行都经过了严格的审计流程:
- 程序化注入:记录被交换的确切值(例如,“100” → “150”)。
- 教师审计:审计员模型审查被破坏的样本。
- 验证:仅当教师独立识别出我们注入的确切错误范围时(例如,教师指出“错误是150”),才接受该样本。
- 人工介入:约5%的模糊案例由人工标注者手动审查。
- AI代理:使用最强的推理模型来处理原始数据集与教师审计之间的不匹配问题以修复问题。
分布情况:
- 自动验证(教师):约95%
- AI代理验证:约4%
- 人工验证:约1%
使用方式
可通过Hugging Face datasets库加载数据集:
python
from datasets import load_dataset
ds = load_dataset("pagand/venra-hal-det-data", revision="v1.0")
引用与代码
项目代码可在Github获取。
基本信息
- 语言:英语
- 许可证:MIT
- 任务类别:文本分类、表格问答
- 标签:金融、幻觉检测、RAG、审计
- 规模类别:1K<n<10K