FactCheck
收藏Hugging Face2025-07-24 更新2025-07-25 收录
下载链接:
https://huggingface.co/datasets/FactCheck-AI/FactCheck
下载链接
链接失效反馈官方服务:
资源简介:
FactCheck是一个用于评估大型语言模型在知识图谱事实验证上的基准数据集。它整合了来自YAGO、DBpedia和FactBench的结构化事实,并结合了从网页中提取的证据,包括问题、摘要、全文和元数据等。该数据集设计用于句子级别的事实检查和问答任务。
创建时间:
2025-07-21
原始信息汇总
FactCheck数据集概述
📝 数据集摘要
FactCheck是一个用于评估大型语言模型在知识图谱事实验证任务上的基准数据集。该数据集结合了来自YAGO、DBpedia和FactBench的结构化事实,以及从网络提取的证据(包括问题、摘要、全文和元数据)。数据集包含专为句子级事实核查和问答任务设计的示例。
📚 支持任务
- 问答:回答源自知识图谱三元组的事实核查问题
- 大型语言模型基准测试
🗣 语言
- 英语(en)
- 可能包含其他语言的Google搜索引擎结果
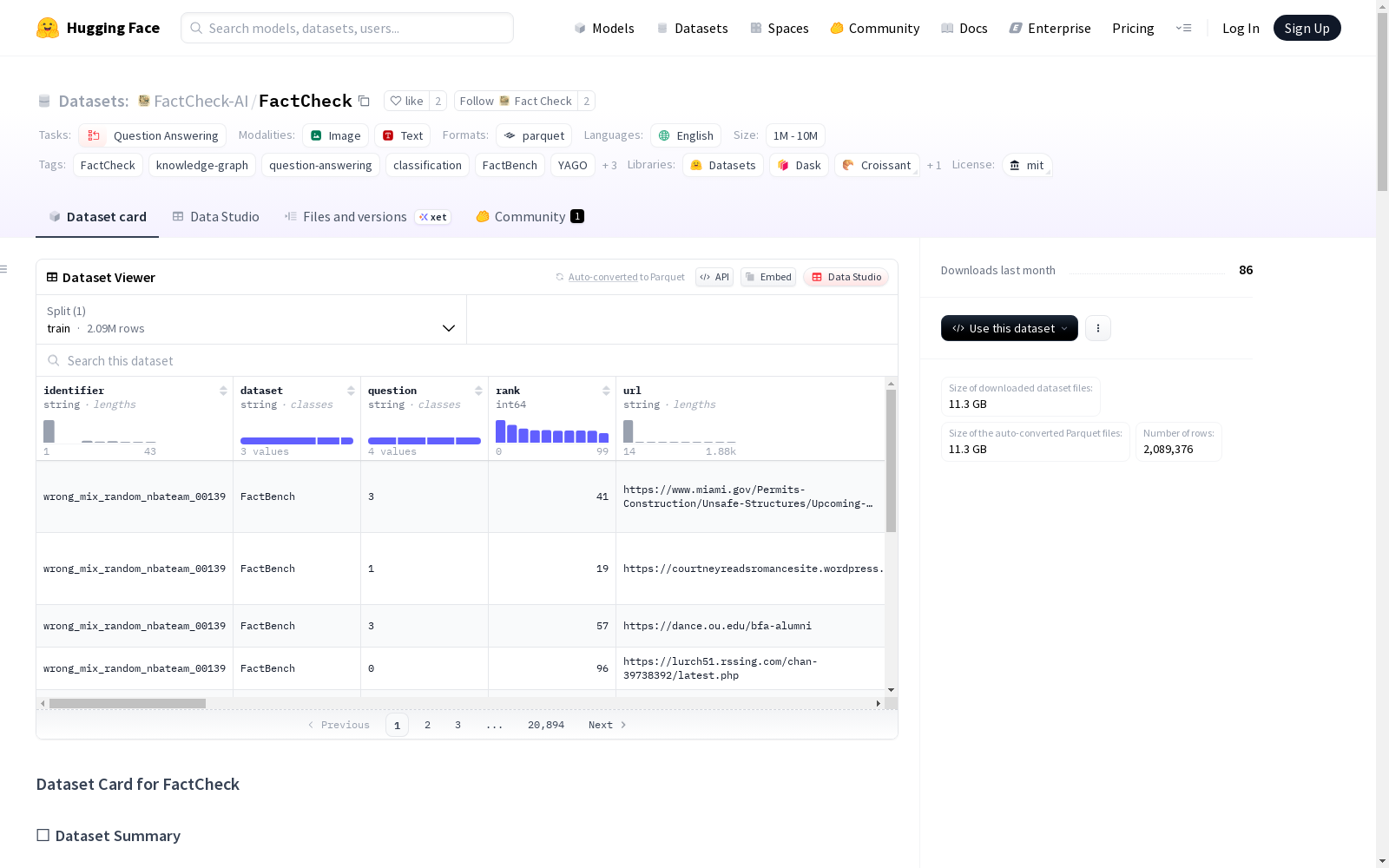
🧱 数据集结构
数据集包含以下字段:
核心字段
identifier:唯一标识符dataset:来源知识图谱(YAGO/DBpedia/FactBench)question:从事实派生的问题rank:问题/页面的相关度排名
内容字段
title:网页标题summary:摘要text:全文内容
媒体资源
images:图片资源movies:视频资源
元数据字段
url:网页源链接read_more_link:扩展阅读链接keywords:关键词meta_keywords:元关键词authors:作者publish_date:发布日期meta_description:元描述meta_site_name:网站名称top_image:顶部图片meta_img:元图片canonical_link:规范链接
🚦 数据划分
仅包含训练集(train),包含2,812,737个示例
🛠 数据集创建
数据来源
- FactBench:约2,800个事实
- YAGO:约1,400个事实
- DBpedia:约9,300个事实
- 使用Google SERP获取的网络证据
处理流程
- 事实检索并与搜索查询配对
- 网页抓取、解析、清理和存储
- 元数据标准化
- 可选排名和过滤以优先处理高相关度证据
⚠️ 隐私信息
数据集不包含个人或隐私数据,所有信息均来自公开可访问的知识图谱和网络证据。
🧑💻 数据集维护者
- Farzad Shami(帕多瓦大学)
- Stefano Marchesin(帕多瓦大学)
- Gianmaria Silvello(帕多瓦大学)
✉️ 联系方式
如有问题请在GitHub仓库提交issue
🔍 分析查询
提供5个SQL查询示例用于数据集分析:
- 按来源知识图谱统计行数
- 按发布日期统计条目数
- 统计缺失标题或摘要的数量
- 统计最常见的前5个域名
- 计算每个示例的平均关键词数量
搜集汇总
数据集介绍
构建方式
FactCheck数据集通过整合YAGO、DBpedia和FactBench等知识图谱的结构化事实构建而成,旨在评估大型语言模型在知识图谱事实验证方面的性能。数据构建过程包括从知识图谱中检索事实,生成相关查询,并通过Google搜索引擎结果页面获取网络证据。随后对网页内容进行抓取、解析和清洗,并统一规范化元数据字段。数据来源均为公开可获取的知识图谱和网络内容,确保了数据的广泛性和可靠性。
使用方法
研究人员可通过Hugging Face平台直接加载该数据集,利用内置SQL查询接口进行交互式分析,快速掌握数据分布特征。针对不同任务需求,可灵活提取问题字段进行问答系统训练,或结合文本摘要与知识图谱来源实现事实核查模型开发。数据集提供的丰富元数据支持对模型预测结果进行多维分析,而预定义的训练集划分则简化了实验流程。对于高级应用,建议结合知识图谱嵌入技术,将结构化事实与文本证据进行联合建模。
背景与挑战
背景概述
FactCheck数据集由帕多瓦大学的FactCheck-AI团队构建,旨在为知识图谱事实验证任务提供基准评估。该数据集整合了来自YAGO、DBpedia和FactBench的结构化事实数据,并结合网络爬取的证据,包括问题、摘要、全文及元数据。其核心研究问题聚焦于评估大型语言模型在结构化知识图谱验证任务中的性能表现,无论是否依赖外部证据。该数据集的创建标志着知识表示与推理领域的重要进展,为事实核查和问答系统研究提供了丰富的多模态资源。
当前挑战
FactCheck数据集面临双重挑战。在领域问题层面,知识图谱事实验证需解决语义歧义消除、多源证据冲突调和以及跨模态信息融合等难题,这对模型的推理能力和知识整合提出极高要求。在构建过程中,研究团队需处理异构数据源的标准化问题,包括知识图谱三元组与网络文本的语义对齐,以及海量网络证据的质量过滤与相关性排序。此外,动态更新的网络内容与静态知识图谱之间的时效性差异,也为数据一致性维护带来显著挑战。
常用场景
经典使用场景
FactCheck数据集在知识图谱验证领域具有重要地位,其经典使用场景包括为大型语言模型(LLM)提供结构化事实验证的基准测试。通过整合YAGO、DBpedia和FactBench等知识图谱的数据,并结合网络提取的证据,该数据集能够支持句子级别的事实核查和问答任务。研究人员可以利用其丰富的元数据和多模态内容,评估模型在复杂知识推理任务中的表现。
解决学术问题
该数据集有效解决了知识图谱与自然语言处理交叉领域的若干关键学术问题。其核心价值在于弥合结构化知识与非结构化文本之间的语义鸿沟,为LLM的事实性验证提供了标准化评估框架。通过融合多源知识图谱和网络证据,它能够系统性地检验模型在知识一致性、推理能力和证据检索等方面的性能,推动了可信AI研究的发展。
实际应用
在实际应用层面,FactCheck数据集为构建可靠的事实核查系统提供了重要支撑。新闻机构可基于其开发自动化事实验证工具,辅助记者快速核实网络信息的真实性。教育领域可利用其构建智能问答系统,提升知识检索的准确性。此外,该数据集还能服务于搜索引擎优化,帮助算法识别和过滤虚假信息,提升网络内容的质量。
数据集最近研究
最新研究方向
随着大语言模型(LLM)在知识图谱推理和事实核查领域的广泛应用,FactCheck数据集已成为评估模型在结构化知识验证任务中性能的重要基准。该数据集整合了YAGO、DBpedia和FactBench等权威知识图谱的语义三元组,并创新性地引入了网络爬取的上下文证据,为研究社区提供了多模态验证场景。当前研究热点集中在三个维度:基于检索增强生成(RAG)的混合验证框架开发,通过结合知识图谱的精确性和网络证据的时效性来提升模型的事实性;跨语言事实核查系统的迁移学习,利用数据集中的多语言元数据探索低资源语言的适应策略;以及针对生成式模型的动态评估协议设计,通过数据集中丰富的媒体资产和结构化字段构建更贴近真实信息生态的测试环境。这些研究方向不仅推动了知识表示与推理技术的边界,也为应对数字时代的信息可信度挑战提供了方法论支持。
以上内容由遇见数据集搜集并总结生成


