Researchy-GEO
收藏Hugging Face2025-12-17 更新2025-12-18 收录
下载链接:
https://huggingface.co/datasets/cx-cmu/Researchy-GEO
下载链接
链接失效反馈官方服务:
资源简介:
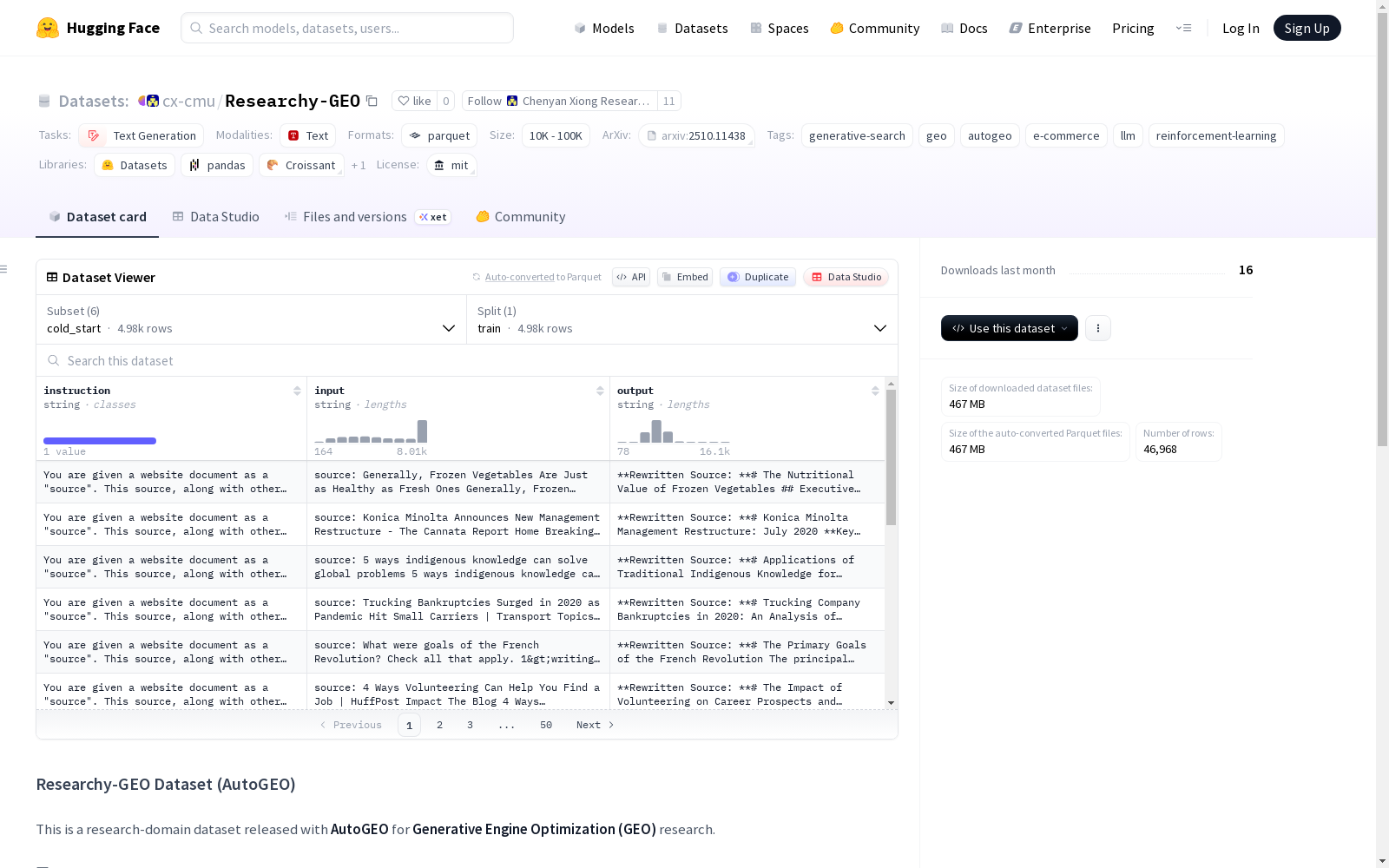
这是一个与AutoGEO一起发布的研究领域数据集,用于生成引擎优化(GEO)研究。数据集包含多个配置:main(用于GEO训练和评估的主要训练/测试数据,约10k训练/1k测试样本)、rule_candidate(用于内容偏好规则提取的数据,约10k样本)、cold_start(用于AutoGEO Mini监督微调的数据,约5k样本)、inference(仅用于推理的数据,约1k样本)、grpo_input(GRPO训练的输入数据,约10k样本)和grpo_eval(GRPO训练模型的评估数据,约10k样本)。
创建时间:
2025-12-13
原始信息汇总
Researchy-GEO 数据集概述
基本信息
- 数据集名称: Researchy-GEO Dataset (AutoGEO)
- 发布目的: 用于生成引擎优化(Generative Engine Optimization, GEO)研究。
- 关联研究: 随 AutoGEO 项目发布。
- 许可证: MIT
研究背景
- 论文标题: "What Generative Search Engines Like and How to Optimize Web Content Cooperatively"
- 论文地址: https://arxiv.org/abs/2510.11438
- 作者: Yujiang Wu*, Shanshan Zhong*, Yubin Kim, Chenyan Xiong (*Equal contribution)
- 代码仓库: https://github.com/cxcscmu/AutoGEO
数据集配置
数据集包含多个配置,每个配置对应不同的数据子集和用途:
- main: 用于GEO训练和评估的主要训练/测试数据(约10k训练样本 / 约1k测试样本)。
- rule_candidate: 用于内容偏好规则提取的数据(约10k样本)。
- cold_start: 用于AutoGEO Mini监督微调的数据(约5k样本)。
- inference: 仅用于推理的数据(约1k样本)。
- grpo_input: 用于GRPO训练的输入数据(约10k样本)。
- grpo_eval: 用于评估GRPO训练模型的数据(约10k样本)。
数据格式与访问
- 主要格式: Parquet 文件。
- 访问方式: 通过配置选择器选择不同的子集。
任务类别与标签
- 主要任务类别: 文本生成(text-generation)
- 标签: generative-search, geo, autogeo, e-commerce, llm, reinforcement-learning
引用格式
bibtex @article{wu2025generative, title={What Generative Search Engines Like and How to Optimize Web Content Cooperatively}, author={Wu, Yujiang and Zhong, Shanshan and Kim, Yubin and Xiong, Chenyan}, journal={arXiv preprint arXiv:2510.11438}, year={2025} }
搜集汇总
数据集介绍
构建方式
在生成式搜索引擎优化研究领域,Researchy-GEO数据集通过系统化的数据采集与标注流程构建而成。其核心数据来源于真实的网络内容与查询交互,并经过结构化处理,形成了涵盖训练、测试及多种专项任务配置的平行文件集合。构建过程中,研究人员依据生成式搜索引擎的行为模式与内容偏好,对原始文本进行了清洗、对齐与标注,确保了数据在语义层面的一致性与研究适用性。该数据集以Parquet格式存储,通过明确的配置划分支持不同研究场景的需求。
使用方法
使用该数据集时,研究者可根据具体实验目标选择相应的配置。例如,进行基础的生成式优化模型训练与评估,可加载‘main’配置中的训练与测试分割;若需进行强化学习策略优化,则可调用‘grpo_input’与‘grpo_eval’配置。数据集以Parquet文件格式提供,可通过Hugging Face数据集库或兼容的数据处理工具进行高效读取与流式加载。在实际应用中,建议结合配套的AutoGEO代码库,按照论文中阐述的数据预处理与模型训练流程,以复现或推进生成式搜索引擎优化的相关研究。
背景与挑战
背景概述
随着生成式人工智能与搜索引擎的深度融合,生成式搜索引擎优化(Generative Engine Optimization, GEO)作为一个新兴的研究领域应运而生,旨在探索如何优化网络内容以适配生成式搜索模型的偏好。Researchy-GEO数据集由卡内基梅隆大学等机构的研究人员于2025年发布,伴随AutoGEO框架一同公开,其核心研究问题聚焦于理解生成式搜索引擎的内容偏好机制,并以此为基础开发协同优化策略。该数据集通过提供多配置的结构化数据,为GEO领域的模型训练、规则提取与评估奠定了实证基础,推动了信息检索与内容生成交叉领域的前沿探索。
当前挑战
在领域问题层面,GEO研究面临的核心挑战在于生成式搜索模型的行为具有高度复杂性与黑箱特性,其内容偏好难以被传统搜索引擎优化方法所刻画,需要从海量交互数据中精准建模并提取可解释的优化规则。在数据集构建过程中,挑战主要体现在如何设计并采集能够全面反映生成式搜索多样意图与偏好的高质量查询-文档对,并在此基础上构建适用于不同训练范式(如监督微调与强化学习)的细分数据子集,以确保数据在支持模型泛化与公平评估方面的有效性与可靠性。
常用场景
经典使用场景
在生成式搜索引擎优化领域,Researchy-GEO数据集为训练和评估生成式内容优化模型提供了核心支持。该数据集通过其主配置(main)提供了约一万条训练样本和一千条测试样本,专门用于模拟生成式搜索引擎的偏好行为,使研究者能够构建和验证内容生成策略,以提升网页在生成式搜索环境中的可见性和相关性。
解决学术问题
该数据集直接应对生成式搜索引擎优化中的关键学术挑战,即如何量化并适应生成式搜索引擎的内容偏好。它通过结构化数据支持对内容生成规则的学习与提取,解决了传统搜索引擎优化技术在生成式范式下的不适用性问题,为探索协同优化机制奠定了实证基础,推动了信息检索与自然语言生成交叉领域的方法论创新。
实际应用
在实际电子商务与内容创作场景中,Researchy-GEO数据集能够指导开发自动化内容优化工具。基于其规则候选(rule_candidate)与冷启动(cold_start)等配置,企业可以训练模型自动生成或改写产品描述、营销文案,使其更符合生成式搜索引擎的推荐逻辑,从而有效提升在线内容的吸引力和转化率,实现智能化的网络营销。
数据集最近研究
最新研究方向
在生成式搜索引擎优化领域,Researchy-GEO数据集正推动前沿探索。该数据集支持生成式引擎优化的协同内容优化研究,其多配置设计如规则候选与冷启动子集,为内容偏好规则提取与模型微调提供了结构化基础。当前热点聚焦于利用强化学习策略,特别是基于GRPO的训练框架,以适配生成式搜索的排名机制,旨在提升内容在生成式搜索结果中的可见性与相关性。这一方向不仅呼应了大型语言模型在信息检索中的深度融合趋势,也为电子商务等场景的智能内容生成与优化开辟了实证路径,具有显著的行业应用潜力。
以上内容由遇见数据集搜集并总结生成


