serbian-llm-benchmark
收藏Hugging Face2024-10-07 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/datatab/serbian-llm-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
塞尔维亚语大型语言模型评估数据集,包含多个配置,用于问题回答和表格问题回答任务。每个配置包含查询、选项和答案等特征,并分为测试和验证数据集。
创建时间:
2024-10-03
原始信息汇总
Serbian LLM Evaluation Dataset
概述
- 语言: 塞尔维亚语 (sr)
- 任务类别:
- 问答 (question-answering)
- 表格问答 (table-question-answering)
- 数据集名称: Serbian LLM Evaluation Dataset
配置信息
arc_challenge_serbian
- 特征:
query: 字符串choices: 字符串序列answer: 整数 (int64)
- 分割:
test: 328831.29010238906 字节, 1136 个样本validation: 10420.709897610921 字节, 36 个样本
- 下载大小: 215945 字节
- 数据集大小: 339252 字节
arc_easy_serbian
- 特征:
query: 字符串choices: 字符串序列answer: 整数 (int64)
- 分割:
test: 563432.7272727273 字节, 2304 个样本validation: 17607.272727272728 字节, 72 个样本
- 下载大小: 356935 字节
- 数据集大小: 581040 字节
boolq_serbian
- 特征:
question: 字符串passage: 字符串answer: 字符串
- 分割:
test: 2134478 字节, 3171 个样本validation: 70288 字节, 99 个样本
- 下载大小: 1487502 字节
- 数据集大小: 2204766 字节
hellaswag_serbian
- 特征:
query: 字符串choices: 字符串序列answer: 整数 (int64)
- 分割:
test: 8060840.2947619995 字节, 9740 个样本validation: 249935.7052380004 字节, 302 个样本
- 下载大小: 5431323 字节
- 数据集大小: 8310776 字节
high_school_statistics_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 119009 字节, 205 个样本validation: 10499 字节, 21 个样本
- 下载大小: 79619 字节
- 数据集大小: 129508 字节
human_aging_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 52917 字节, 218 个样本validation: 5613 字节, 23 个样本
- 下载大小: 44239 字节
- 数据集大小: 58530 字节
mmlu_abstract_algebra_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 22316 字节, 100 个样本validation: 2345 字节, 11 个样本
- 下载大小: 14128 字节
- 数据集大小: 24661 字节
mmlu_all_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 7248461 字节, 13946 个样本validation: 790350 字节, 1523 个样本
- 下载大小: 4560106 字节
- 数据集大小: 8038811 字节
mmlu_anatomija_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 36290.177777777775 字节, 134 个样本validation: 3604 字节, 14 个样本
- 下载大小: 29603 字节
- 数据集大小: 39894.177777777775 字节
mmlu_astronomija_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 55447 字节, 152 个样本validation: 6160 字节, 16 个样本
- 下载大小: 43218 字节
- 数据集大小: 61607 字节
mmlu_college_biology_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 54564.48611111111 字节, 142 个样本validation: 5334 字节, 16 个样本
- 下载大小: 46975 字节
- 数据集大小: 59898.48611111111 字节
mmlu_college_chemistry_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 27873 字节, 100 个样本validation: 2610 字节, 8 个样本
- 下载大小: 26704 字节
- 数据集大小: 30483 字节
mmlu_college_computer_science_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 45492.48 字节, 99 个样本validation: 5375 字节, 11 个样本
- 下载大小: 39712 字节
- 数据集大小: 50867.48 字节
mmlu_college_mathematics_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 27080 字节, 100 个样本validation: 2955 字节, 11 个样本
- 下载大小: 23145 字节
- 数据集大小: 30035 字节
mmlu_college_medicine_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 63485.387283236996 字节, 169 个样本validation: 7787.181818181818 字节, 21 个样本
- 下载大小: 53595 字节
- 数据集大小: 71272.56910141882 字节
mmlu_college_physics_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 32636 字节, 102 个样本validation: 3665 字节, 11 个样本
- 下载大小: 27572 字节
- 数据集大小: 36301 字节
mmlu_computer_security_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 30670.08 字节, 98 个样本validation: 4953 字节, 11 个样本
- 下载大小: 29021 字节
- 数据集大小: 35623.08 字节
mmlu_conceptual_physics_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 48701 字节, 235 个样本validation: 5593 字节, 26 个样本
- 下载大小: 36300 字节
- 数据集大小: 54294 字节
mmlu_econometrics_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 42769 字节, 114 个样本validation: 5250 字节, 12 个样本
- 下载大小: 32138 字节
- 数据集大小: 48019 字节
mmlu_electrical_engineering_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 30675.972413793104 字节, 144 个样本validation: 3552 字节, 16 个样本
- 下载大小: 26586 字节
- 数据集大小: 34227.972413793104 字节
mmlu_formalna_logika_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 52688.19047619047 字节, 124 个样本validation: 6852 字节, 14 个样本
- 下载大小: 32391 字节
- 数据集大小: 59540.19047619047 字节
mmlu_global_facts_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 21406 字节, 100 个样本validation: 2195 字节, 10 个样本
- 下载大小: 18616 字节
- 数据集大小: 23601 字节
mmlu_high_school_biology_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 122475.20967741935 字节, 305 个样本validation: 12491 字节, 32 个样本
- 下载大小: 89344 字节
- 数据集大小: 134966.20967741933 字节
mmlu_high_school_chemistry_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 67222 字节, 203 个样本validation: 8146 字节, 22 个样本
- 下载大小: 50739 字节
- 数据集大小: 75368 字节
mmlu_high_school_computer_science_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 48159.36 字节, 96 个样本validation: 3968 字节, 9 个样本
- 下载大小: 39089 字节
- 数据集大小: 52127.36 字节
mmlu_high_school_european_history_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 250885.21212121213 字节, 164 个样本validation: 28918 字节, 18 个样本
- 下载大小: 175083 字节
- 数据集大小: 279803.21212121216 字节
mmlu_high_school_geography_serbian
- 特征:
query: 字符串subject: 字符串choices: 字符串序列answer: 字符串
- 分割:
test: 50013.656565656565 字节, 196 个样本validation: 5321
搜集汇总
数据集介绍
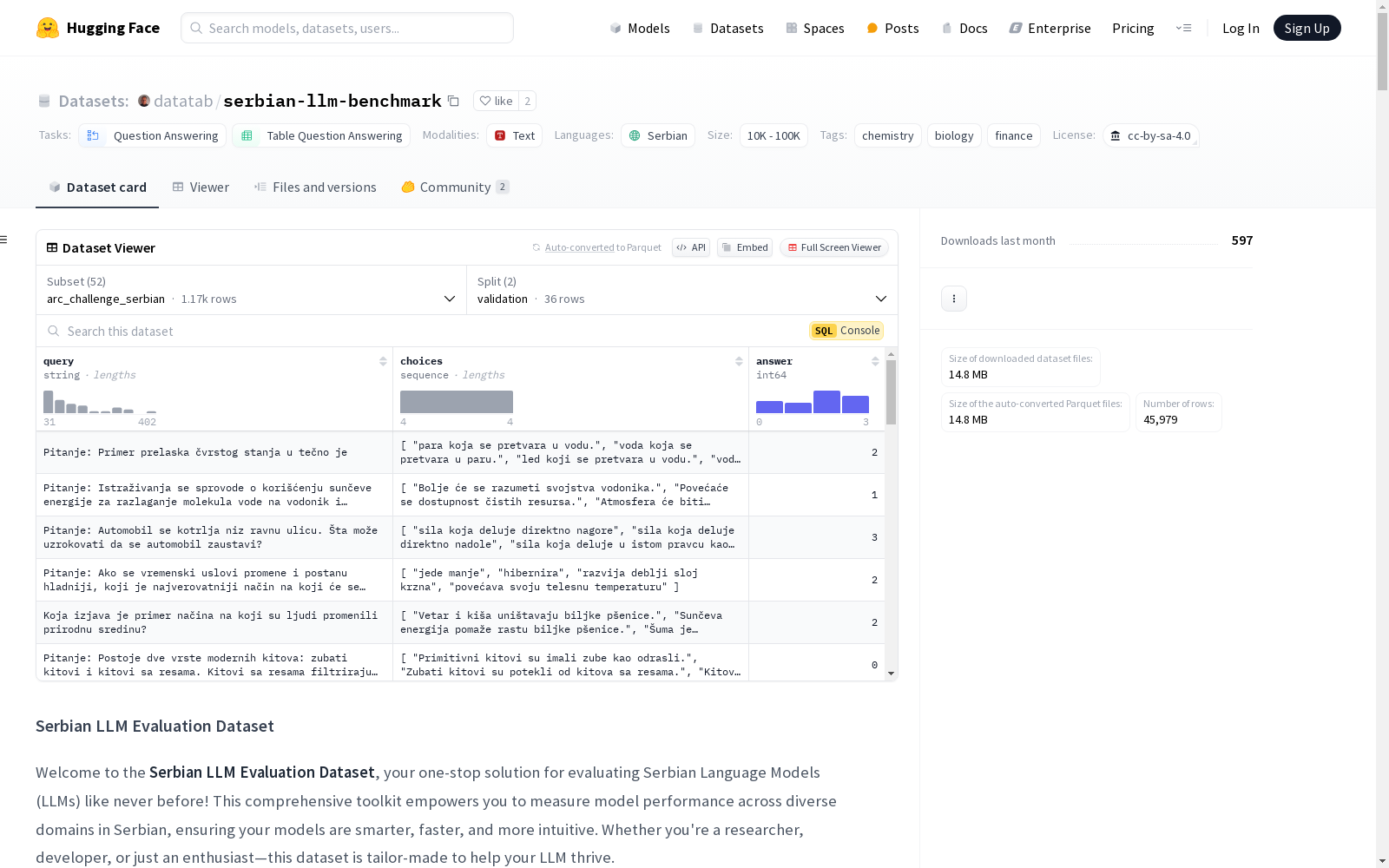
构建方式
Serbian LLM Evaluation Dataset 是通过对多个任务类别进行精心设计和构建的,涵盖了问答、表格问答等多种任务类型。数据集的构建基于塞尔维亚语,确保了语言的本土化和多样性。每个配置(config)都包含了查询、选项和答案等关键特征,并通过测试集和验证集的分割,确保了数据的全面性和可靠性。数据集的构建过程严格遵循科学方法,确保了数据的准确性和代表性。
特点
该数据集的特点在于其广泛的任务覆盖范围和多样化的数据配置。每个配置都针对不同的学科领域,如生物学、化学、计算机科学等,提供了丰富的查询和选项。数据集的语言为塞尔维亚语,填补了该语言在自然语言处理领域的数据空白。此外,数据集的结构清晰,每个配置都包含了详细的特征描述和分割信息,便于研究人员进行深入分析和模型训练。
使用方法
该数据集的使用方法灵活多样,适用于多种自然语言处理任务。研究人员可以通过加载不同的配置,针对特定任务进行模型训练和评估。数据集提供了测试集和验证集,便于进行模型的性能测试和验证。使用该数据集时,建议首先根据任务需求选择合适的配置,然后利用提供的查询和选项进行模型训练,最后通过答案字段进行模型评估。数据集的结构设计使得其易于集成到现有的机器学习框架中,为塞尔维亚语的自然语言处理研究提供了强有力的支持。
背景与挑战
背景概述
Serbian LLM Evaluation Dataset 是一个专门用于评估塞尔维亚语大语言模型性能的数据集,涵盖了问答、表格问答等多个任务类别。该数据集的创建旨在填补塞尔维亚语自然语言处理领域的空白,特别是在多任务评估方面的不足。数据集的核心研究问题在于如何通过多样化的任务和领域知识,全面评估模型在塞尔维亚语环境下的表现。其影响力不仅体现在为塞尔维亚语NLP研究提供了基准数据,还推动了多语言模型在低资源语言上的应用与发展。
当前挑战
该数据集面临的挑战主要体现在两个方面。首先,塞尔维亚语作为一种低资源语言,其语料库的构建和标注过程面临数据稀缺和质量控制的难题,尤其是在涉及复杂任务如表格问答和逻辑推理时。其次,数据集的多样性和广泛性要求涵盖多个学科领域,如数学、物理、化学等,这对数据收集和验证提出了更高的要求,确保数据的准确性和代表性成为构建过程中的主要挑战。此外,如何平衡数据集的规模与质量,以支持模型的泛化能力,也是该数据集构建过程中需要解决的关键问题。
常用场景
经典使用场景
在自然语言处理领域,serbian-llm-benchmark数据集被广泛用于评估和优化塞尔维亚语语言模型的性能。该数据集涵盖了多个任务类别,如问答、表格问答等,能够全面测试模型在不同语境下的理解与推理能力。通过该数据集,研究人员可以深入分析模型在复杂语言环境中的表现,进而推动塞尔维亚语语言模型的发展。
实际应用
在实际应用中,serbian-llm-benchmark数据集为塞尔维亚语智能助手、教育工具和翻译系统的开发提供了重要支持。通过该数据集训练的模型能够更好地理解塞尔维亚语的语法和语义,从而提升用户体验。此外,该数据集还可用于优化多语言模型在塞尔维亚语环境中的表现,推动跨语言技术的应用。
衍生相关工作
基于serbian-llm-benchmark数据集,许多经典研究工作得以展开。例如,研究人员利用该数据集开发了针对塞尔维亚语的预训练语言模型,并在问答和推理任务中取得了显著进展。此外,该数据集还催生了一系列关于多语言模型优化的研究,为塞尔维亚语自然语言处理技术的发展奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


