finepdfs-edu
收藏Hugging Face2025-11-12 更新2025-11-13 收录
下载链接:
https://huggingface.co/datasets/HuggingFaceFW/finepdfs-edu
下载链接
链接失效反馈官方服务:
资源简介:
FinePDFs-Edu 数据集包含来自 PDF 文档的 350B+ 教育性标记,涵盖了 69 种语言。该数据集是从 FinePDFs 数据集中筛选出来的,并通过教育质量分类器进行了过滤,以确保内容的教育性。数据集包含了从 2013 年到 2025 年的所有 CommonCrawl 垃圾桶。此外,还包括了用于过滤的教育分类器和标记数据,以及训练和推理代码。
提供机构:
HuggingFaceFW创建时间:
2025-11-11
原始信息汇总
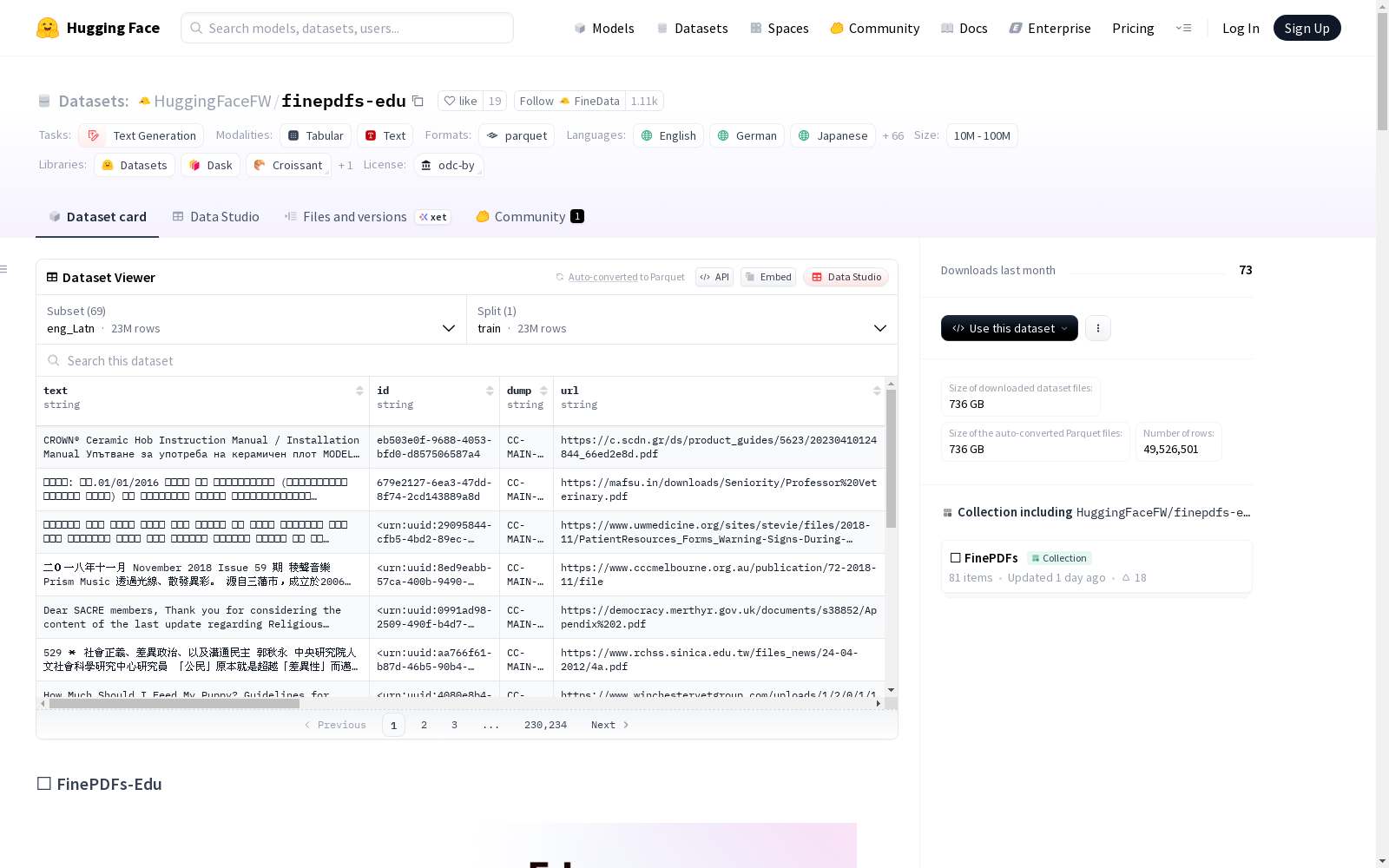
FinePDFs-Edu 数据集概述
数据集基本信息
- 数据集名称: FinePDFs-Edu
- 许可证: ODC-By
- 任务类别: 文本生成
- 数据规模: 超过1TB
- 令牌数量: 3500亿+教育令牌
语言覆盖
- 支持69种语言,包括:
- 英语 (eng_Latn)
- 德语 (deu_Latn)
- 日语 (jpn_Jpan)
- 法语 (fra_Latn)
- 西班牙语 (spa_Latn)
- 中文 (cmn_Hani)
- 俄语 (rus_Cyrl)
- 葡萄牙语 (por_Latn)
- 阿拉伯语 (arb_Arab)
- 韩语 (kor_Hang)
- 及其他59种语言
数据来源与处理
- 从FinePDFs数据集中筛选教育类PDF文档
- 覆盖CommonCrawl从CC-MAIN-2013-20到CC-MAIN-2025-08的所有转储
- 使用基于Qwen3-235B-A22B-Instruct-2507生成标注的教育质量分类器
- 对每种语言训练独立的分类器
- 保留教育评分最高的10%样本
技术特点
- 全局去重处理
- 支持多语言混合样本
- 基于ModernBERT-large(英语)和mmBERT-base(其他语言)的分类器
- 在H100 GPU上处理速度达220样本/秒
性能表现
- 在MMLU和ARC等教育基准测试中优于FinePDFs
- 相比原始FinePDFs,教育质量显著提升
使用方式
- 通过datatrove、huggingface_hub或datasets库访问
- 支持流式处理
- 可按语言子集下载
相关资源
- 教育分类器:https://huggingface.co/HuggingFaceFW/finepdfs_edu_classifier_eng_Latn
- 标注数据集:https://huggingface.co/datasets/HuggingFaceFW/finepdfs_eng_Latn_labeled
- 源代码:https://github.com/huggingface/finepdfs
引用信息
bibtex @misc{kydlicek2025finepdfs, title={FinePDFs}, author={Hynek Kydl{\i}{v{c}}ek and Guilherme Penedo and Leandro von Werra}, year={2025}, publisher = {Hugging Face}, journal = {Hugging Face repository}, howpublished = {url{https://huggingface.co/datasets/HuggingFaceFW/finepdfs_edu}} }
搜集汇总
数据集介绍
构建方式
在构建FinePDFs-Edu数据集的过程中,研究者从FinePDFs原始语料库中筛选出教育价值较高的PDF文档,覆盖了69种语言。通过利用Qwen3-235B-A22B-Instruct-2507模型对约30万样本进行0-5分的教育质量评分,并基于评分结果训练了针对每种语言的BERT式回归分类器。最终采用保留各语言前10%高分样本的策略,实现了全局去重,确保了数据集的纯净度与教育相关性。
特点
FinePDFs-Edu数据集以其超过3500亿标记的庞大规模脱颖而出,涵盖多语言教育内容,并通过严格的分类器过滤机制提升质量。该数据集在MMLU和ARC等教育基准测试中表现卓越,显著优于原始FinePDFs及其他开放网络数据集。其独特之处在于实现了跨语言的全局去重,同时保留了丰富的语言转换样本,为多语言模型训练提供了高质量基础。
使用方法
用户可通过datatrove工具包直接读取Parquet格式数据,或利用huggingface_hub进行批量下载,亦能借助datasets库以流式传输方式加载特定语言子集。为处理数据中的语言混合现象,建议使用官方提供的代码切换过滤功能。该数据集适用于文本生成任务的模型训练,尤其适合需要多语言教育语料的场景,使用者可根据实际需求灵活调整数据采样规模。
背景与挑战
背景概述
随着数字教育资源的爆炸式增长,如何从海量非结构化文档中筛选高质量教育内容成为自然语言处理领域的关键课题。FinePDFs-Edu数据集由HuggingFace研究团队于2025年创建,通过构建基于Qwen3大语言模型的跨语言教育质量分类器,从涵盖69种语言的PDF文档库中精选出超过3500亿标记的教育内容。该数据集采用全局去重技术,显著提升了多语言教育文本的数据纯度,为知识密集型语言模型的训练提供了标准化语料支撑。
当前挑战
在解决教育内容质量评估问题时,该数据集面临多语言语义一致性判定的核心难题,需克服不同文化背景下教育价值标准的差异性。构建过程中遭遇了长文档信息密度分布不均的技术瓶颈,通过首尾分段评分机制优化处理流程。针对原始数据中仅2%样本符合传统阈值的情况,创新采用动态百分比筛选策略,同时需应对69种语言分类器并行训练时的计算资源分配挑战。
常用场景
经典使用场景
在自然语言处理领域,FinePDFs-Edu数据集凭借其覆盖69种语言、经过严格教育质量筛选的3500亿标记规模,成为多语言文本生成模型训练的首选资源。该数据集通过基于Qwen3大模型构建的教育质量分类器,从海量PDF文档中精选出最具教育价值的内容,为构建高质量语言模型提供了经过全局去重的纯净语料。其多语言特性与教育内容优先的筛选策略,使其在跨语言知识传递和学术文本生成任务中展现出独特价值。
实际应用
在实际应用层面,FinePDFs-Edu为教育科技领域提供了高质量的多语言知识基底。基于该数据集训练的模型可支撑智能教育助手、跨语言学术资源检索系统等应用场景,其严格的教育内容筛选机制确保了生成文本的准确性与教育价值。在数字化教育资源建设方面,该数据集为构建覆盖多学科、多语言的教育内容库提供了标准化数据源,显著提升了教育类自然语言处理应用的可靠性与实用性。
衍生相关工作
该数据集催生了系列重要衍生研究,其核心贡献在于构建了可扩展的多语言教育质量分类器框架。基于相同方法论构建的FineWeb-Edu等姊妹数据集,形成了教育内容筛选的技术谱系。相关研究团队进一步开发了基于ModernBERT-large和mmBERT-base的优化分类器,推动了教育内容自动评估技术的发展。这些工作共同构成了从数据标注、质量评估到模型训练的全链条创新,为多语言教育语料库建设提供了完整的技术蓝图。
以上内容由遇见数据集搜集并总结生成


