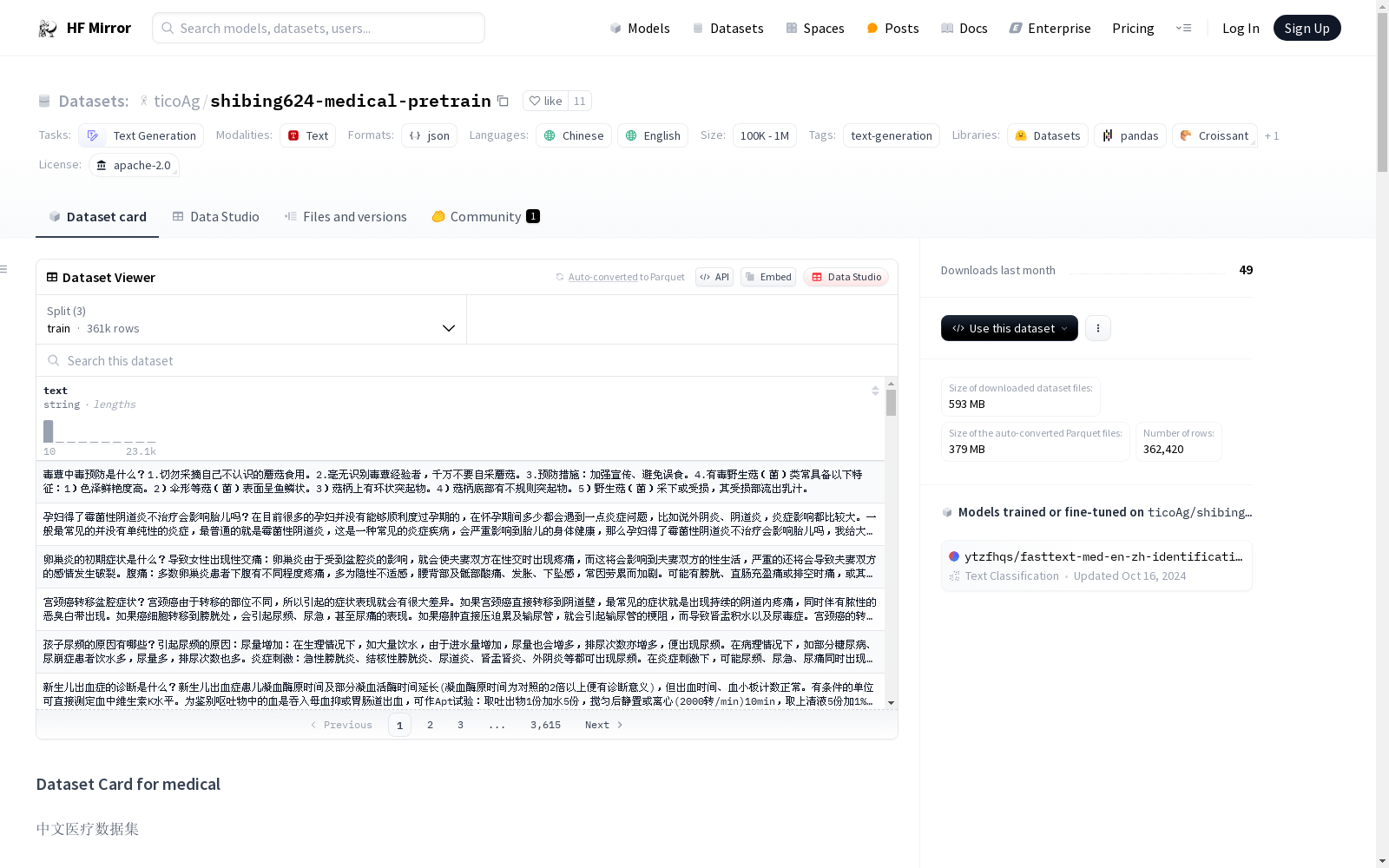
ticoAg/shibing624-medical-pretrain
收藏数据集卡片 for medical
数据集描述
medical 是一个中文医疗数据集,可用于医疗领域大模型训练。
数据集结构
目录结构
tree medical
|-- finetune # 监督微调数据集,可用于SFT和RLHF
| |-- test_en_1.json
| |-- test_zh_0.json
| |-- train_en_1.json
| |-- train_zh_0.json
| |-- valid_en_1.json
| -- valid_zh_0.json |-- medical.py # hf dataset 数据展示用 |-- pretrain # 二次预训练数据集 | |-- medical_book_zh.json | |-- test_encyclopedia.json | |-- train_encyclopedia.json | -- valid_encyclopedia.json
|-- README.md
-- reward # 奖励模型数据集 |-- test.json |-- train.json -- valid.json
数据实例
预训练数据集 pretrain
train_encyclopedia.json: 共36万条,来自医疗百科数据,拼接 questions 和 answers,形成 text 文本字段,语句通顺,用于预训练注入医疗知识。medical_book_zh.json: 共8475条,来自医疗教材的文本数据,只对长段落切分为2048字的小段落。
指令微调数据集 finetune
train_zh_0.json: 共195万条,来自中文医疗对话数据集的六个科室医疗问诊数据、在线医疗百科和医疗知识图谱。train_en_1.json: 共11万条,来自英文医疗问诊对话数据,合并了HealthCareMagic-100k、GenMedGPT-5k 数据集。
奖励模型数据集 reward
train.json: 共4000条,问题来自中文医疗对话数据集的随机4000条提问,response_chosen来自该数据集的医生答复,response_rejected来自本草模型的答复。
数据字段
预训练数据集 pretrain
text: 文本
指令微调数据集 finetune
instruction: 指令input: 问题(可为空)output: 答复
奖励模型数据集 reward
question: 问题response_chosen: 优质回答response_rejected: 低质回答
数据分割
wc -l medical// 500 medical/finetune/test_en_1.json 500 medical/finetune/test_zh_0.json 116617 medical/finetune/train_en_1.json 1949972 medical/finetune/train_zh_0.json 500 medical/finetune/valid_en_1.json 500 medical/finetune/valid_zh_0.json 8475 medical/pretrain/medical_book_zh.json 500 medical/pretrain/test_encyclopedia.json 361420 medical/pretrain/train_encyclopedia.json 500 medical/pretrain/valid_encyclopedia.json 100 medical/reward/test.json 3800 medical/reward/train.json 100 medical/reward/valid.json 2443484 total
许可信息
该数据集在 Apache 2.0 许可下可用。
引用信息
- https://github.com/Toyhom/Chinese-medical-dialogue-data
- https://github.com/FreedomIntelligence/Huatuo-26M/blob/main/README_zh-CN.md
- https://huggingface.co/datasets/FreedomIntelligence/huatuo_encyclopedia_qa
- https://huggingface.co/datasets/FreedomIntelligence/huatuo_knowledge_graph_qa
- https://github.com/Kent0n-Li/ChatDoctor
贡献
shibing624 整理并上传