CHASM
收藏arXiv2026-04-22 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/Jingyi77/CHASM-Covert_Advertisement_on_RedNote
下载链接
链接失效反馈官方服务:
资源简介:
CHASM是由香港科技大学(广州)与奥胡斯大学联合构建的首个多模态隐蔽广告检测数据集,基于中国社交平台RedNote(小红书)的真实场景数据。该数据集包含4,992条经过严格隐私处理的高质量标注样本,涵盖图文帖文及评论,其中12.3%为隐蔽广告正例,22.6%为易混淆的非广告商品分享内容。数据通过动态质量控制框架标注,采用三阶段流程(采集-过滤-匿名化)确保合规性,并创新性引入黄金测试题与多数投票机制提升标注一致性。该数据集旨在解决社交平台中伪装成常规内容的隐蔽广告检测难题,为多模态大语言模型在内容审核领域的性能评估与优化提供基准。
CHASM is the first multimodal hidden advertisement detection dataset jointly developed by The Hong Kong University of Science and Technology (Guangzhou) and Aarhus University, based on real-world scenario data from the Chinese social platform RedNote (Xiaohongshu). This dataset contains 4,992 high-quality annotated samples that have undergone strict privacy processing, covering image-text posts and comments. Among them, 12.3% are positive samples of hidden advertisements, and 22.6% are easily confusable non-advertising product-sharing content. The data was annotated using a dynamic quality control framework, which adopts a three-stage workflow (collection, filtering, anonymization) to ensure compliance, and innovatively introduces gold standard test questions and a majority voting mechanism to enhance annotation consistency. This dataset aims to address the challenge of detecting hidden advertisements disguised as regular content on social platforms, and provides a benchmark for performance evaluation and optimization of multimodal large language models (LLMs) in the field of content moderation.
提供机构:
香港科技大学·广州; 奥胡斯大学
创建时间:
2026-04-22
原始信息汇总
数据集概述
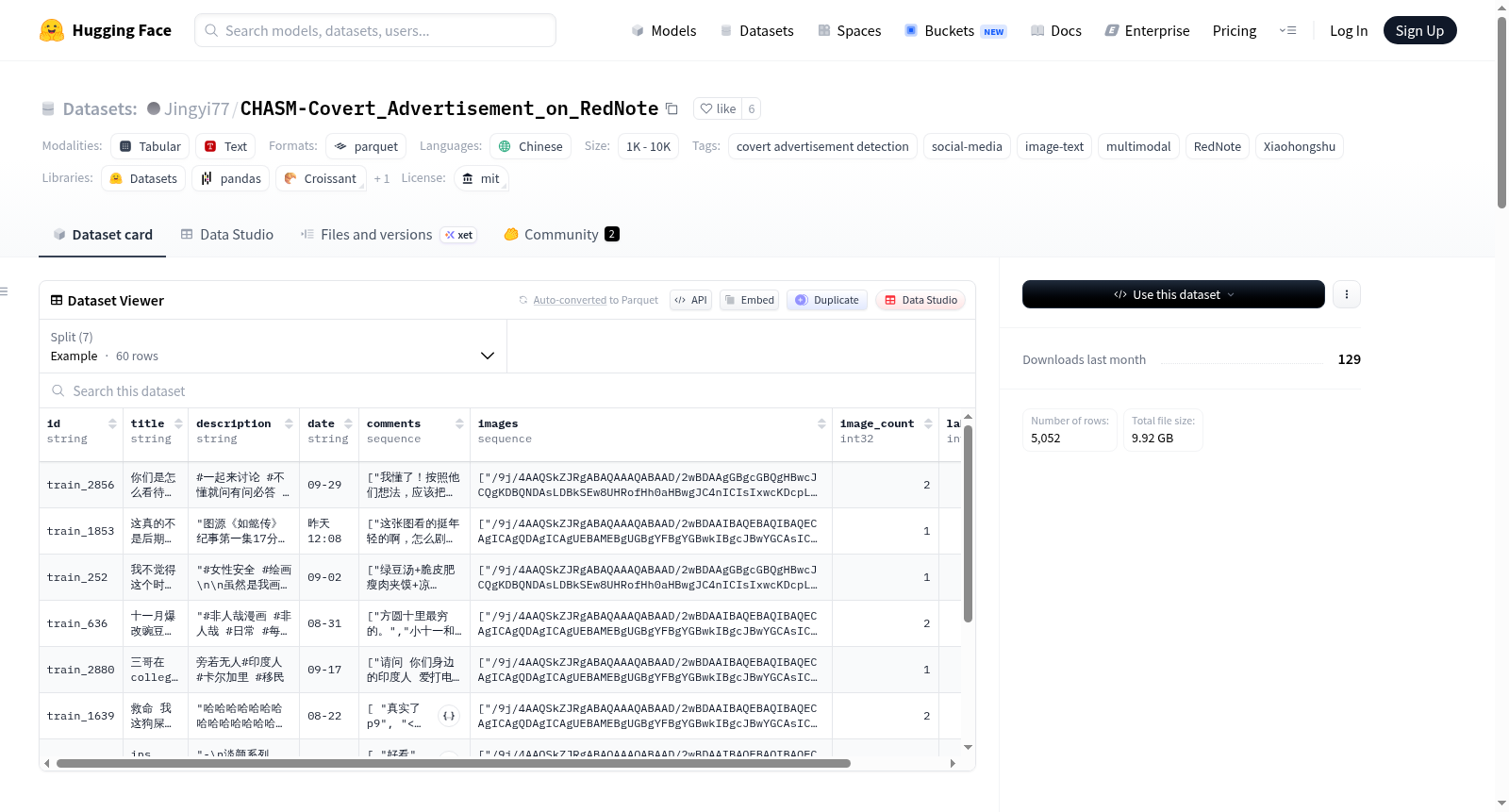
CHASM-Covert_Advertisement_on_RedNote 是一个用于检测小红书(RedNote)平台上的隐性广告的中文多模态数据集。
基本信息
- 语言:中文
- 许可协议:MIT
- 数据规模:共 4992 篇帖子,包含 613 篇广告帖和 4379 篇非广告帖,总计 26324 张图片
数据划分
| 数据划分 | 帖子总数 | 广告帖 | 非广告帖 | 图片总数 |
|---|---|---|---|---|
| 训练集 | 3493 | 426 | 3067 | 18543 |
| 验证集 | 499 | 57 | 442 | 2678 |
| 测试集 | 1000 | 130 | 870 | 5103 |
| 总计 | 4992 | 613 | 4379 | 26324 |
数据字段
每条数据包含以下字段:
id:帖子的唯一标识符title:帖子标题description:帖子描述内容date:发布日期(格式:MM-DD)comments:评论列表images:Base64 编码的图片列表image_count:图片数量label:标签(0=非广告,1=广告)split:数据划分(训练/验证/测试)
数据集特点
- 多模态数据:每条帖子同时包含文本(标题、描述、评论)和图像信息
- 真实数据:采集自小红书平台的实际社交媒体帖子
- 多图支持:每篇帖子可能包含多张图片,平均每帖约 5.27 张图片
数据格式
完整数据集以 WebDataset 格式存储,每个样本包含:
- 一张或多张 JPG 格式的图片文件
- 一个 JSON 格式的元数据文件,包含:
id、title、description、date、comments、label
引用信息
@dataset{CHASM, author = {Jingyi Zheng, Tianyi Hu, Yule Liu, Zhen Sun, Zongmin Zhang, Wenhan Dong, Zifan Peng, Xinlei He}, title = {CHASM: Unveiling Covert Advertisements on Chinese Social Media}, year = {2025}, publisher = {Hugging Face}, journal = {Hugging Face Hub}, howpublished = {url{https://huggingface.co/datasets/Jingyi77/CHASM-Covert_Advertisement_on_RedNote}} }
搜集汇总
数据集介绍
构建方式
CHASM数据集源自中国主流社交平台小红书,严格遵循平台用户协议与隐私保护政策,通过三个全新账号收集2024年9月至10月间的公开内容。经过滤除明确标注为广告的样本后,对剩余数据实施匿名化处理,包括文本中个人信息的掩码与图像中面部的模糊化。数据集包含4,992个多模态实例,涵盖帖子标题、正文、图像、评论及发布时间。标注过程由五名母语为中文的标注者完成,采用动态质量控制框架:先由一名标注者判断内容是否与商品相关,若不相关则直接标记为非广告;若相关,则引入三名标注者的多数投票机制,确保至少一名经验丰富的标注者参与。同时内嵌50道黄金标准题进行质量监控,使标注准确率从单标注者的78%提升至94%,且标注资源消耗降低至全面三人投票的43.3%。
特点
CHASM具有多项显著特点。作为首个专注于社交媒体隐性广告检测的数据集,其核心挑战在于包含大量与隐性广告高度相似的真实产品体验分享帖,增加了区分难度。12.3%的正样本(隐性广告)与87.7%的负样本构成类别不平衡,其中22.6%为产品相关但非广告的样本,形成尤为困难的子集。数据集涵盖文本、图像及评论的多模态信息,平均每样本含5.28张图像与196.63字正文。为应对标注主观性,系统提供了基于证据的详细标注指南,涵盖促销证据、语言风格、图文结构三大维度。动态质量控制策略有效平衡了可靠性与效率,初始标注者间一致性(Fleiss' kappa=0.65)反映了任务固有歧义,而优化后的流程显著提升了标注质量。
使用方法
CHASM可支持多种评估范式。在零样本设置下,向模型提供判断标准与完整的帖子内容,要求输出二分类结果;上下文学习则在提示中额外加入正负例各一个。微调实验采用5折交叉验证,在Qwen2.5-7B上插入LoRA适配器(秩8,α=32),以AdamW优化器、余弦学习率调度器训练3轮,批量大小通过梯度累积模拟更大规模。评估指标包含精确率、召回率、F1分数及AUC,其中F1作为核心指标。可用于系统评估各类多模态大语言模型,包括开源模型(如InternVL2.5、Qwen2.5-7B)与闭源模型(如GPT-4o、DeepSeek-V3),以及推理型模型(如Gemini 2.5 Pro)。数据集发布于Hugging Face,代码开源于GitHub,便于社区复现与扩展研究。
背景与挑战
背景概述
在社交媒体广告经济蓬勃发展的当下,隐性广告作为一种伪装成普通内容的推广形式悄然蔓延,严重威胁消费者权益与平台公信力。CHASM数据集由香港科技大学(广州)与奥胡斯大学的研究人员于2025年构建,聚焦于评估多模态大语言模型(MLLMs)对中文社交平台小红书(RedNote)上隐性广告的检测能力。该数据集包含4,992条精心标注的实例,涵盖大量与真实产品体验分享帖高度相似的样本,填补了现有基准在隐性广告这一关键安全漏洞上的空白,为模型训练与评估提供了首个标准化资源,对推动社交媒体内容审核研究具有里程碑意义。
当前挑战
CHASM数据集所应对的核心挑战源于隐性广告的欺骗性与多模态伪装:其一,广告主刻意隐藏推广意图,使其与普通生活分享帖在视觉、文本结构及语言风格上难以区分,导致传统图像分类或文本情感分析等单模态方法失效;其二,数据构建过程中面临主观标注歧义与成本控制的矛盾,团队采用动态质量控制框架,通过预置金标准问题与三人多数投票机制将标注精度从78%提升至94%,但仍需平衡效率与可靠性;此外,当前顶尖MLLMs在零样本与上下文学习设置下的最佳F1分数仅约0.6,暴露出模型对细粒度线索(如评论区隐藏链接、图片倒置镜像)的识别瓶颈,以及泛化至多品牌结构等复杂场景的局限性。
常用场景
经典使用场景
CHASM数据集的核心应用在于评估与提升多模态大语言模型对社交媒体中隐蔽广告的检测能力。该数据集精心收录了来自小红书平台的真实帖子,涵盖文本、图像及评论等丰富模态,尤其注重纳入大量与隐蔽广告高度相似的真实用户体验分享帖,以增加判别挑战性。研究者可借助该数据集,在零样本、上下文学习及微调等不同范式下,系统测试模型对伪装为日常分享的推广内容的识别敏锐度,从而深入剖析多模态模型在复杂社会语境下的理解与推理局限。
解决学术问题
该数据集填补了社交媒体内容审核领域针对隐蔽广告这一新兴威胁的评估空白。此前研究多聚焦于虚假新闻、仇恨言论等显性有害内容,而隐蔽广告因其高度的伪装性与主观判别歧义,长期缺乏系统标注与基准测试。CHASM通过定义清晰的判别准则、构建证据驱动的标注框架,解决了隐蔽广告识别中“证据不足”“线索遗漏”“语体风格混淆”“结构模式忽视”等核心学术难题,并揭示了现有多模态大模型在该任务上的显著不足,为后续模型训练提供了坚实的评估基准与改进方向。
衍生相关工作
CHASM数据集的出现催生了系列创新研究。例如,基于该数据集的工作探索了多模态大模型在隐蔽广告检测中的动态感知能力,研究者通过分析评论演变与帖子时间序列,提出了时序敏感型检测框架。此外,该数据集还推动了融合用户行为数据与创作者画像的跨维度检测模型开发,以及针对图像倒置、特殊符号嵌入等复杂伪装手法的专项对抗训练。这些衍生工作不仅深化了对隐蔽广告理解的理论认知,也拓展了多模态内容审核的技术边界。
以上内容由遇见数据集搜集并总结生成


