nguyenvy/cleaned_nhanes_1988_2018
收藏Hugging Face2024-05-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/nguyenvy/cleaned_nhanes_1988_2018
下载链接
链接失效反馈资源简介:
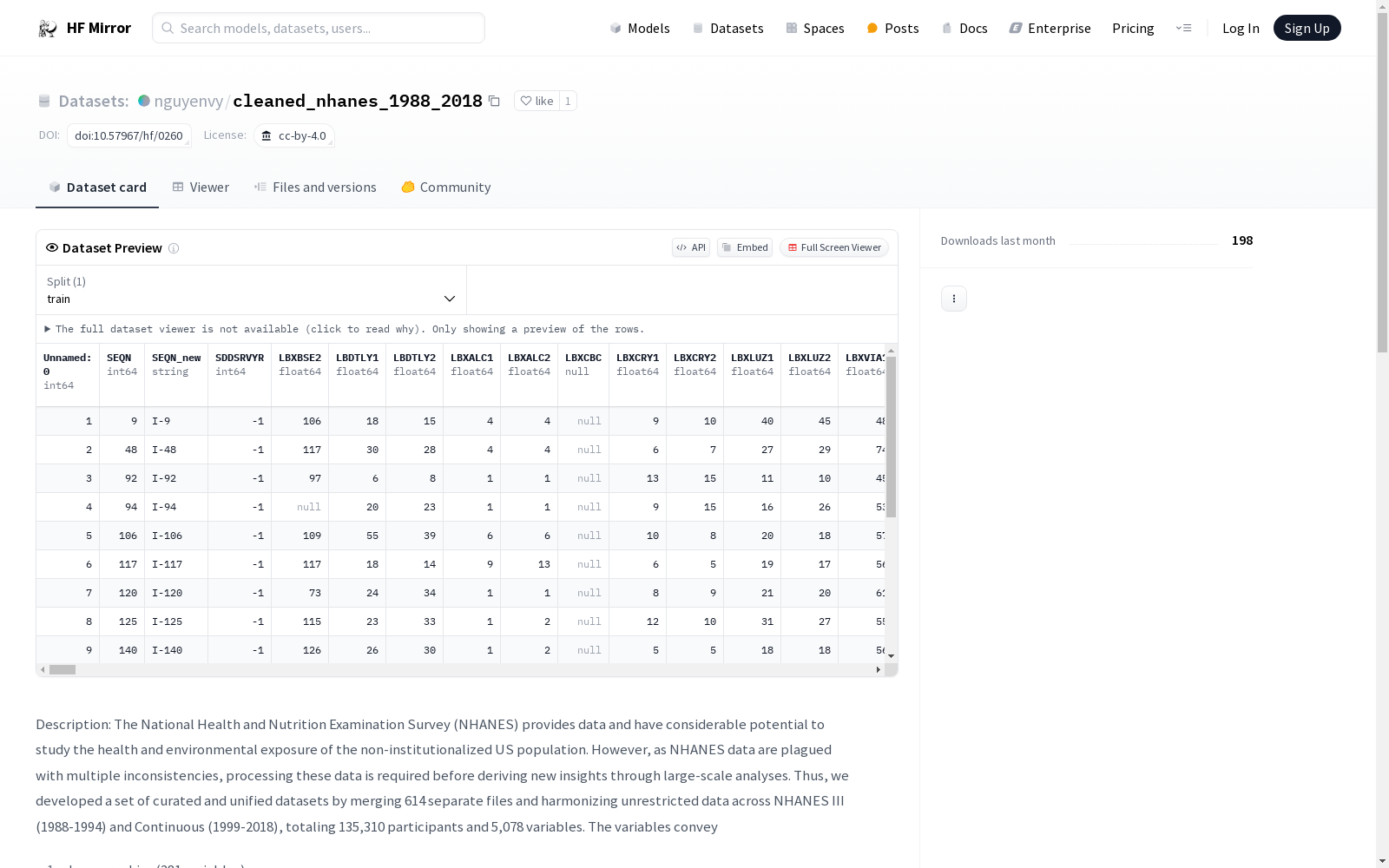
国家健康与营养调查(NHANES)数据集提供了1988年至2018年美国非机构化人口的健康和营养调查数据,包含135,310名参与者和5,078个变量。这些变量分为10个主要类别:人口统计(281个变量)、饮食消费(324个变量)、生理功能(1,040个变量)、职业(61个变量)、问卷(1,444个变量,如体育活动、医疗状况、糖尿病、生殖健康、血压和胆固醇、儿童早期)、药物(29个变量)、与国家死亡指数相关的死亡率信息(15个变量)、调查权重(857个变量)、环境暴露生物标志物测量(598个变量)以及指示测量值是否低于或高于检测下限的化学评论(505个变量)。数据集以CSV和R格式提供,并附有数据字典和清理文档。此外,还提供了R脚本和示例代码,帮助用户进行数据分析和模型构建。
The National Health and Nutrition Examination Survey (NHANES) dataset provides health and nutrition survey data for the non-institutionalized U.S. population from 1988 to 2018, covering 135,310 participants and 5,078 variables. These variables are categorized into 10 major groups: Demographics (281 variables), Dietary Consumption (324 variables), Physiological Function (1,040 variables), Occupation (61 variables), Questionnaires (1,444 variables including physical activity, medical conditions, diabetes, reproductive health, blood pressure and cholesterol, early childhood), Medications (29 variables), Mortality information linked to the National Death Index (15 variables), Survey Weights (857 variables), Environmental Exposure Biomarker Measurements (598 variables), and Chemical Comments (505 variables) indicating whether measured values fall below or above the lower limit of detection. The dataset is available in CSV and R formats, accompanied by a data dictionary and cleaning documentation. Additionally, R scripts and sample code are provided to assist users with data analysis and model construction.
提供机构:
nguyenvy
原始信息汇总
数据集概述
数据集名称
国家健康与营养检查调查(NHANES)数据集
数据集内容
该数据集通过整合614个独立文件,统一了NHANES III(1988-1994)和连续调查(1999-2018)的无限制数据,总计包含135,310名参与者和5,078个变量。这些变量涵盖以下类别:
- 人口统计(281个变量)
- 饮食消费(324个变量)
- 生理功能(1,040个变量)
- 职业(61个变量)
- 问卷调查(1444个变量,如体力活动、医疗状况、糖尿病、生殖健康、血压和胆固醇、早期儿童)
- 药物(29个变量)
- 从国家死亡指数链接的死亡信息(15个变量)
- 调查权重(857个变量)
- 环境暴露生物标志物测量(598个变量)
- 化学评论,指示哪些测量值低于或高于检测下限(505个变量)
数据记录格式
- CSV数据记录:包括23个.csv文件和1个excel文件。其中,20个.csv文件涉及10个模块,每个模块有两个文件,一个未清洗版本和一个清洗版本。此外,还包括变量字典和协调类别字典。
- R数据记录:为使用R语言的研究人员提供,包括清洗后的NHANES模块和数据字典,以.zip文件形式提供,包含.RData文件和.R文件。
示例代码
提供四个R markdown文件,用于帮助用户进行暴露分析,包括数据集合并、模型建立、统计计算和多重回归分析的示例代码。
AI搜集汇总
数据集介绍
构建方式
在构建nguyenvy/cleaned_nhanes_1988_2018数据集时,研究者通过整合美国国家健康与营养检查调查(NHANES)的614个独立文件,实现了对NHANES III(1988-1994)和连续调查(1999-2018)数据的统一处理。这一过程涉及对135,310名参与者和5,078个变量的数据进行清洗和标准化,确保了数据的一致性和可用性。具体操作包括合并不同模块的数据、消除不一致性,并生成详细的清洗文档,以记录所有受影响变量的处理细节。
特点
nguyenvy/cleaned_nhanes_1988_2018数据集的显著特点在于其广泛的数据覆盖和细致的分类。该数据集涵盖了从人口统计、饮食消费到生理功能、职业信息等多个领域的281至1444个变量。此外,数据集还包括与环境暴露、药物使用、死亡信息以及调查权重相关的详细记录。这些丰富的数据类型和详细的分类为研究者提供了深入分析美国非机构化人口健康和环境暴露的宝贵资源。
使用方法
使用nguyenvy/cleaned_nhanes_1988_2018数据集时,研究者可以通过提供的CSV和R数据文件进行数据导入和分析。数据集包括20个CSV格式的清洗版本文件和相应的数据字典,以及一个包含所有数据集的RData文件。此外,研究者可以使用提供的R Markdown示例代码,逐步学习如何合并数据集、进行加权回归分析、计算摘要统计以及运行多重回归模型。这些资源旨在帮助用户有效地利用数据集进行健康和环境暴露的深入研究。
背景与挑战
背景概述
国家健康与营养检查调查(NHANES)数据集自1988年至2018年收集,由美国非机构化人口的健康和环境暴露数据组成,具有重要的研究潜力。该数据集由614个独立文件合并而成,涵盖了135,310名参与者和5,078个变量,涉及人口统计、饮食消费、生理功能、职业、问卷调查、药物、死亡信息、调查权重、环境暴露生物标志物测量及化学评论等多个领域。主要研究人员通过统一和规范这些数据,旨在为大规模分析提供高质量的数据基础,从而推动健康和环境暴露研究的发展。
当前挑战
NHANES数据集在构建过程中面临多重挑战。首先,原始数据存在多种不一致性,需要进行复杂的处理和清洗。其次,数据集的规模庞大,涉及多个模块和变量,增加了数据整合和管理的难度。此外,数据集的多样性和复杂性要求研究人员具备高度的专业知识和技能,以确保数据的质量和一致性。最后,数据集的广泛应用需要提供详尽的数据字典和示例代码,以帮助用户理解和使用数据,这增加了数据集的维护和更新成本。
常用场景
经典使用场景
在公共卫生领域,nguyenvy/cleaned_nhanes_1988_2018数据集的经典使用场景主要集中在对美国非机构化人口的健康和营养状况进行大规模分析。通过整合和清洗来自NHANES III(1988-1994)和连续调查(1999-2018)的614个独立文件,该数据集提供了135,310名参与者和5,078个变量的统一数据,涵盖了从人口统计、饮食消费到生理功能、职业、问卷调查、药物使用、死亡信息、调查权重、环境暴露生物标志物测量等多个维度。这些数据为研究人员提供了丰富的资源,用于探索和分析美国人口的健康状况及其与环境因素的关系。
实际应用
在实际应用中,nguyenvy/cleaned_nhanes_1988_2018数据集被广泛用于公共卫生政策制定、疾病预防和健康促进项目。例如,研究人员可以利用该数据集分析不同饮食习惯与慢性疾病之间的关系,从而为营养指南的制定提供科学依据。此外,数据集中的环境暴露生物标志物测量数据可用于评估环境污染对公众健康的影响,为环境保护政策的制定提供支持。通过这些实际应用,该数据集在改善公众健康和提升生活质量方面发挥了重要作用。
衍生相关工作
基于nguyenvy/cleaned_nhanes_1988_2018数据集,许多经典工作得以展开。例如,有研究利用该数据集分析了长期暴露于特定环境污染物与心血管疾病发病率之间的关系,为环境健康研究提供了新的视角。此外,还有研究通过该数据集探讨了不同社会经济因素对健康状况的影响,揭示了社会不平等与健康结果之间的复杂联系。这些研究不仅丰富了公共卫生领域的知识体系,还为政策制定者提供了重要的参考依据,推动了相关领域的进一步发展。
以上内容由AI搜集并总结生成


