PersonaLedger
收藏arXiv2026-01-07 更新2026-01-08 收录
下载链接:
https://huggingface.co/datasets/capitalone/PersonaLedger
下载链接
链接失效反馈官方服务:
资源简介:
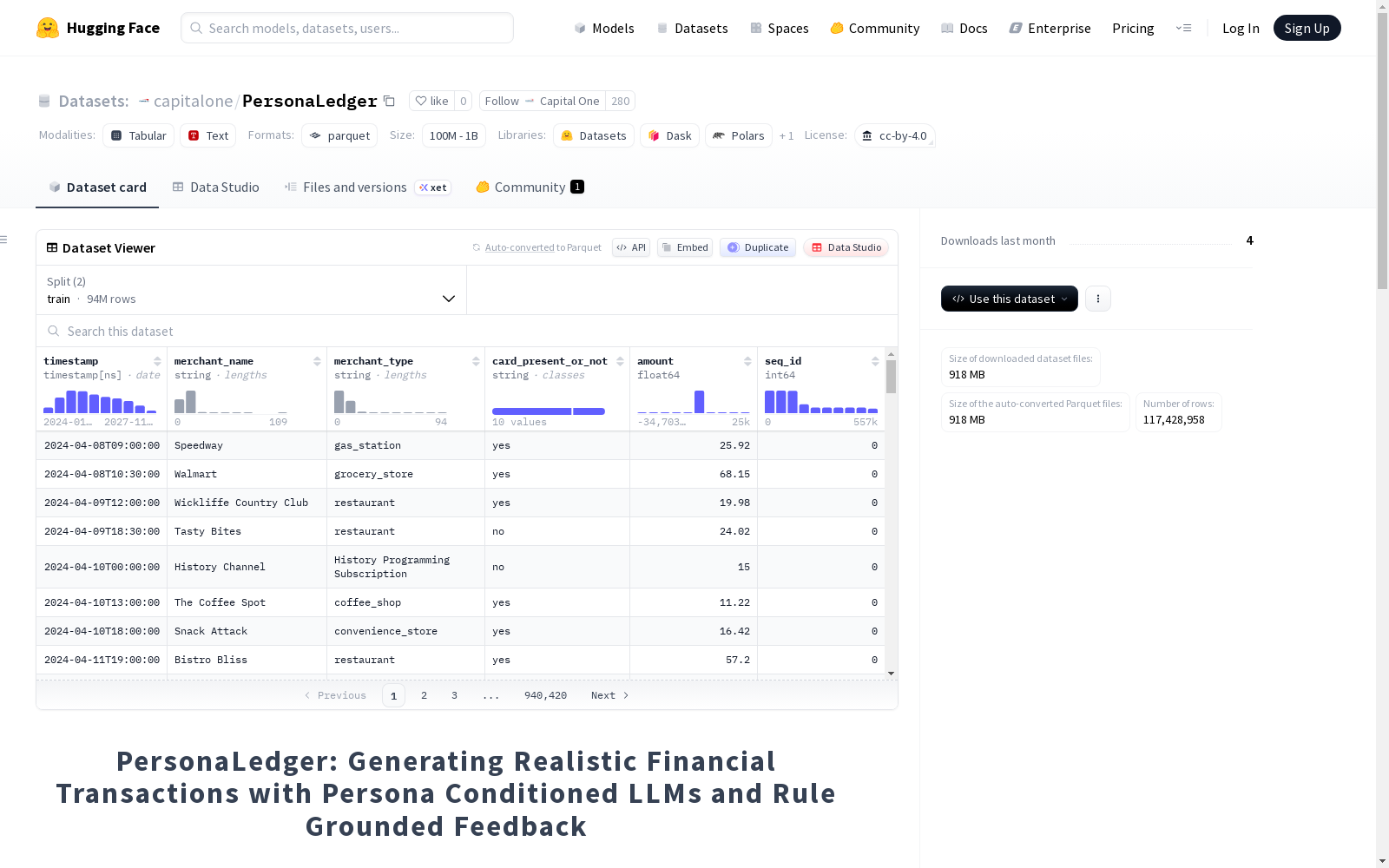
PersonaLedger是由第一资本联合多家机构构建的大规模金融交易模拟数据集,包含23,000名用户生成的3000万条交易记录,平均每用户覆盖两年活动周期。数据集通过结合大语言模型生成能力和规则引擎约束,实现了行为多样性与财务逻辑严谨性的统一,包含丰富的人物画像、商户类型和时间特征。该数据集支持流动性风险分类和身份盗用检测等金融AI任务,为隐私敏感的金融研究提供了合规的基准资源。
PersonaLedger is a large-scale financial transaction simulation dataset developed by Capital One in collaboration with multiple institutions. It comprises 30 million transaction records generated by 23,000 users, with an average activity cycle of two years per user. By integrating the generative capabilities of Large Language Models (LLMs) and the constraints of rule engines, this dataset achieves a balance between behavioral diversity and strict financial logic, and contains rich user personas, merchant categories and temporal features. It supports financial AI tasks such as liquidity risk classification and identity theft detection, providing compliant benchmark resources for privacy-sensitive financial research.
提供机构:
第一资本; 谷歌; 马里兰大学帕克分校
创建时间:
2026-01-07
原始信息汇总
PersonaLedger 数据集概述
数据集基本信息
- 数据集名称: PersonaLedger
- 发布机构: Capital One Research 等机构的研究人员
- 许可证: CC-BY-4.0
- 数据规模: 包含3000万条合成的金融交易记录
核心特征
- 采用角色驱动的大型语言模型生成数据,以确保行为多样性。
- 使用程序化引擎来强制保证会计正确性。
基准测试套件
任务定义
-
偿付能力预测
- 任务类型: 序列分类(用户级别)。
- 目标: 给定n个月的交易历史,预测用户是否会在近期内变得“缺乏流动性”。
- 偿付能力/流动性不足定义: 指在特定时刻,用户的信用卡余额超过其可用现金流和信用额度的状态。
-
身份盗窃检测
- 任务类型: 分割(事件级别)。
- 目标: 在用户的合法交易历史中识别隐藏的欺诈性交易。
- 数据构成: 数据集中将来自次要用户(盗窃者)的一天的、按时间顺序排列的交易记录注入到主要用户的历史记录中。
数据集结构
数据集包含以下目录和文件:
identity_theft_1months/: 身份盗窃检测数据(1个月周期),包含train.parquet和test.parquet文件。identity_theft_3months/: 身份盗窃检测数据(3个月周期),包含train.parquet和test.parquet文件。insolvency_prediction_1months/: 偿付能力预测数据(1个月周期),包含train.parquet、test.parquet和labels.json文件。insolvency_prediction_3months/: 偿付能力预测数据(3个月周期),包含train.parquet、test.parquet和labels.json文件。raw_generation/: 原始生成数据,包含insolvent/(偿付能力不足实体样本)和normal/(正常实体样本)子目录。
数据生成与基准测试说明
raw_generation/目录中的是由大型语言模型生成的原始交易记录。通过对这些生成数据进行后处理,生成了其余四个目录的数据。- 如需使用此数据集对流行的时间序列Transformer模型进行基准测试(如论文中表2和表3所示),请参考相关代码。
搜集汇总
数据集介绍
构建方式
在金融人工智能领域,数据隐私法规严格限制了真实交易数据的获取,阻碍了开放式研究的进展。PersonaLedger数据集通过一种创新的闭环生成引擎构建,该引擎结合了基于用户画像条件化的大型语言模型与可配置的程序化规则系统。生成过程以Nemotron-Personas提供的丰富用户画像为起点,利用Llama-3.3-70B模型推断用户的财务状况。在每日循环中,语言模型根据当前用户状态和画像提议候选交易,随后程序化引擎严格验证交易是否符合现金守恒、信用额度、付款截止日期等硬性财务约束。若交易有效,引擎确定性地更新用户状态;若违反规则,则生成结构化提示反馈给语言模型以引导其修正。这种交互确保了生成的3000万笔交易在保持行为多样性的同时,严格遵守会计逻辑与财务可行性。
特点
PersonaLedger数据集展现出高度的行为多样性与逻辑严谨性。其核心特征在于通过23,000个具有详细人口统计、职业背景与生活方式属性的用户画像,驱动生成了涵盖近75,000家独特商户的广泛交易序列。数据集模拟了真实世界的消费规律,例如支出随教育水平、汽车拥有状况和年龄生命周期曲线变化,并体现了节假日与工作日的消费模式差异。尤为重要的是,所有交易均通过程序化规则强制保证了会计正确性,包括余额一致性、定期订阅结转以及流动性约束的遵守。数据集还附带了完整的用户状态快照与规则满足度元数据,为建模提供了可靠且可审计的基础。
使用方法
PersonaLedger数据集为金融时间序列分析与异常检测研究提供了可直接应用的基准测试套件。研究人员可利用其进行流动性风险分类与身份盗用分割两项核心任务。数据集已划分为标准的训练、验证与测试集,并提供了强基线模型的结果。用户可直接从Hugging Face平台获取数据,数据格式包含时间戳、商户名称、类型、交易金额等字段。对于模型开发,建议采用保留交易金额符号并对数值进行对数压缩的特征表示方法,并对商户名称与类型进行基于频率的独热编码。数据集的生成代码、规则集与完整日志均已公开,支持数据的精确复现、规则扩展以及在新经济情境下的难度调整,确保了研究的可重复性与可扩展性。
背景与挑战
背景概述
在金融人工智能领域,严格的隐私法规限制了真实交易数据的获取,阻碍了开放式研究的进展。为应对这一挑战,Capital One、Google及马里兰大学的研究团队于2026年共同推出了PersonaLedger数据集。该数据集旨在通过合成数据填补真实数据稀缺的空白,其核心研究问题是:如何在保证行为多样性的同时,确保交易序列符合逻辑约束与会计规则。PersonaLedger采用基于大语言模型的生成引擎,结合用户画像与程序化规则反馈,生成了包含23000名用户、3000万笔交易的大规模公开数据集,为金融预测、风险管理和异常检测等任务提供了高保真、隐私安全的基准资源,显著推动了金融AI研究的可复现性与创新速度。
当前挑战
PersonaLedger数据集致力于解决金融交易序列生成中的双重挑战:在领域问题层面,需克服行为多样性与逻辑基础性之间的平衡难题。传统规则驱动模拟器虽能保证规则遵循,却难以捕捉人类消费的丰富行为模式;而基于学习的生成器虽能模拟统计相关性,却常违反硬性财务约束,且依赖私有数据训练。在构建过程中,研究团队面临的具体挑战包括:如何设计闭环交互机制,使大语言模型在生成多样化交易提议时,能实时接受程序化引擎的规则校验与状态反馈;如何确保长期序列生成中不出现预算漂移、逾期账单或账户不一致等累积性错误;以及如何基于用户画像推断其财务状态,并整合订阅、周期性账单等动态要素,以维持模拟的真实性与一致性。
常用场景
经典使用场景
在金融人工智能领域,PersonaLedger数据集为研究提供了高度逼真的合成交易序列,其经典应用场景在于模拟多样化用户行为下的消费与支付模式。通过结合丰富用户画像与规则约束的生成引擎,该数据集能够复现现实世界中由职业、生活习惯、收入节奏等因素驱动的复杂交易动态,为预测模型和异常检测算法的开发与验证奠定了坚实基础。
解决学术问题
PersonaLedger有效解决了金融AI研究中因隐私限制导致真实数据匮乏的学术难题。它通过合成数据生成技术,在保证行为多样性与逻辑一致性的前提下,为流动性风险分类和身份盗用分割等任务提供了可重复的基准测试平台。这一资源促进了开放研究,使得学者能够在无需接触敏感信息的情况下,深入探索交易序列中的长期依赖关系与异常模式识别。
衍生相关工作
围绕PersonaLedger数据集,衍生了一系列专注于时间序列分析与金融AI的经典研究工作。这些研究探索了Transformer架构在交易序列预测中的有效性,并推动了针对类不平衡与长尾分布的模型改进。此外,该数据集启发了结合程序化规则与大语言模型的混合生成框架,为合成数据生成领域提供了新的方法论范式,促进了行为模拟与约束满足的融合创新。
以上内容由遇见数据集搜集并总结生成


