GeoSound
收藏GeoSound 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类型: 音频分类、图像到文本
- 语言: 英语
- 标签: 音频、卫星图像、地理空间、声景、多模态、遥感
- 数据规模: 100K 至 1M 条记录
数据集构成
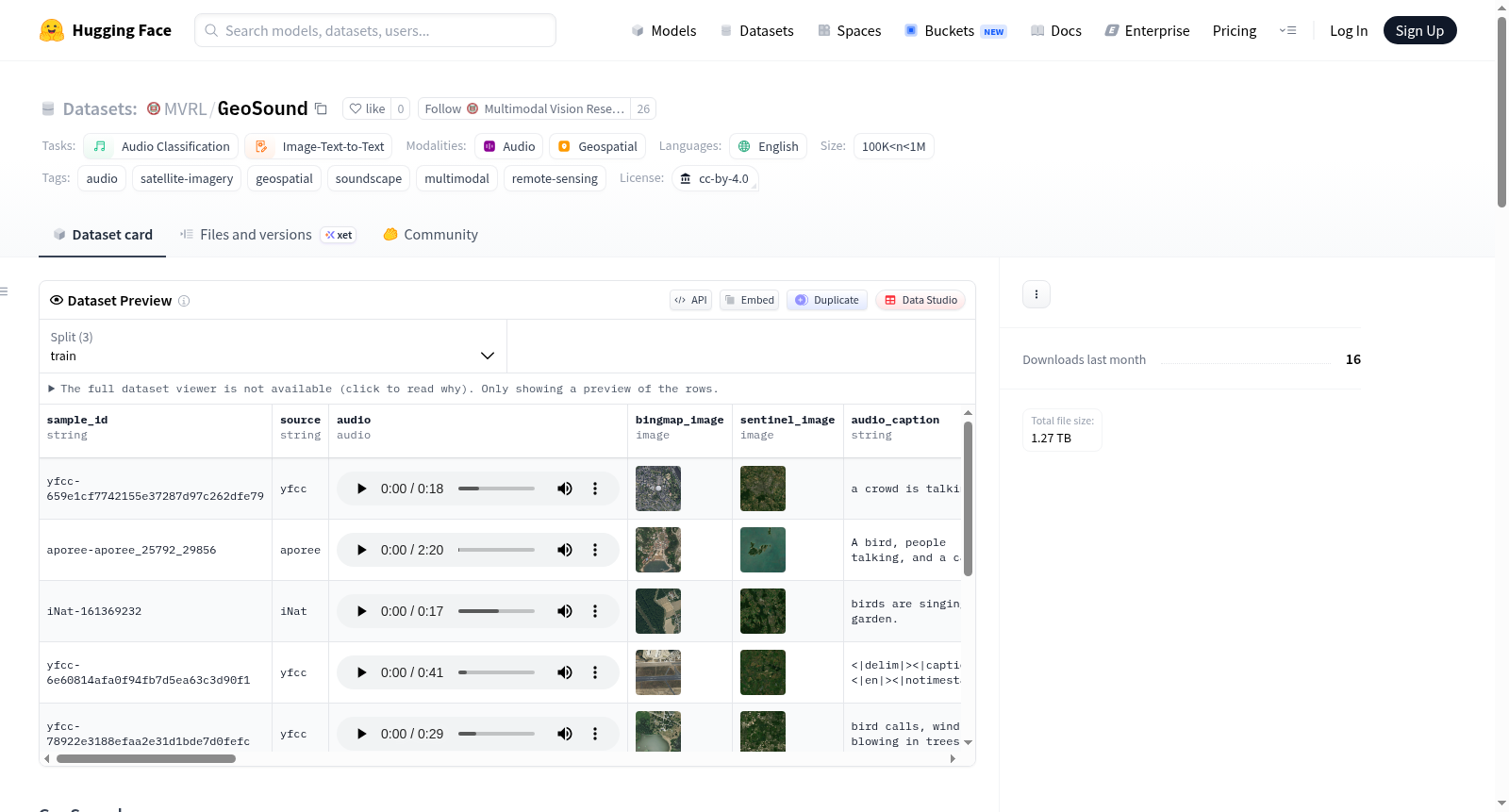
GeoSound 是一个地理参考声景数据集,将卫星/航拍图像与环境音频记录配对。数据来源于 iNaturalist、xeno-canto、Freesound 等多个平台,覆盖广泛的地理范围。
数据划分
| 划分 | 样本数 |
|---|---|
| 训练集 | 293,718 |
| 验证集 | 4,999 |
| 测试集 | 9,931 |
划分策略: 采用基于空间网格的地理划分策略,将地球表面划分为空间单元,每个完整单元仅分配给一个划分,防止地理信息泄露。
数据字段说明
| 字段名 | 类型 | 描述 |
|---|---|---|
sample_id |
字符串 | 样本唯一标识符 |
source |
字符串 | 数据来源平台 |
audio |
音频(32 kHz) | 原始波形 |
bingmap_image |
图像 | 录音位置的必应地图航拍瓦片 |
sentinel_image |
图像 | 录音位置的哨兵-2卫星瓦片 |
audio_caption |
字符串 | 描述音频的文本标题 |
audio_caption_source |
字符串 | 标题来源 |
mel_features |
float32 四维数组 | 预计算的 log-mel 频谱特征(5个增强视图) |
llava_caption_bingmap_zl{1,3,5} |
字符串 | LLaVA 生成的必应地图瓦片描述(缩放级别1、3、5) |
llava_caption_sentinel_zl{1,3,5} |
字符串 | LLaVA 生成的哨兵瓦片描述(缩放级别1、3、5) |
latitude |
float32 | 录音纬度 |
longitude |
float32 | 录音经度 |
date |
字符串 | 录音日期 |
description |
字符串 | 来源平台的自由文本描述 |
tags |
字符串 | 来源平台的逗号分隔标签 |
title |
字符串 | 录音标题 |
scientific_name |
字符串 | 观察物种的学名 |
common_name |
字符串 | 观察物种的常用名 |
sound_format |
字符串 | 原始音频格式 |
text |
字符串 | 用于检索的拼接自由文本字段 |
address |
字符串 | 录音位置的反向地理编码地址 |
original_sampling_rate |
int64 | 重采样前的原始音频采样率 |
bin_id |
字符串 | 用于地理划分分配的空间单元ID |
数据加载示例
python from datasets import load_dataset
完整数据集(推荐流式加载,总大小1.27TB)
ds = load_dataset("MVRL/GeoSound", split="train", streaming=True)
row = next(iter(ds)) audio = row["audio"]["array"] # np.ndarray, 32 kHz bingmap = row["bingmap_image"] # PIL Image caption = row["audio_caption"] lat, lon = row["latitude"], row["longitude"]
预计算梅尔频谱:形状 (5, 1, 1001, 64) — 选择5个片段之一
import numpy as np mel = np.asarray(row["mel_features"], dtype="float32")[0]
引用信息
若使用 GeoSound 数据集,请引用 PSM 论文: bibtex @inproceedings{khanal2024psm, title = {PSM: Learning Probabilistic Embeddings for Multi-scale Zero-Shot Soundscape Mapping}, author = {Khanal, Subash and Eric, Xing and Sastry, Srikumar and Dhakal, Aayush and Xiong Zhexiao and Ahmad, Adeel and Jacobs, Nathan}, year = {2024}, month = nov, booktitle = {ACM Multimedia}, }