YnJhY2lzMjAyNnRleHQyc3Fs/rede_saude_publica_test_set
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/YnJhY2lzMjAyNnRleHQyc3Fs/rede_saude_publica_test_set
下载链接
链接失效反馈官方服务:
资源简介:
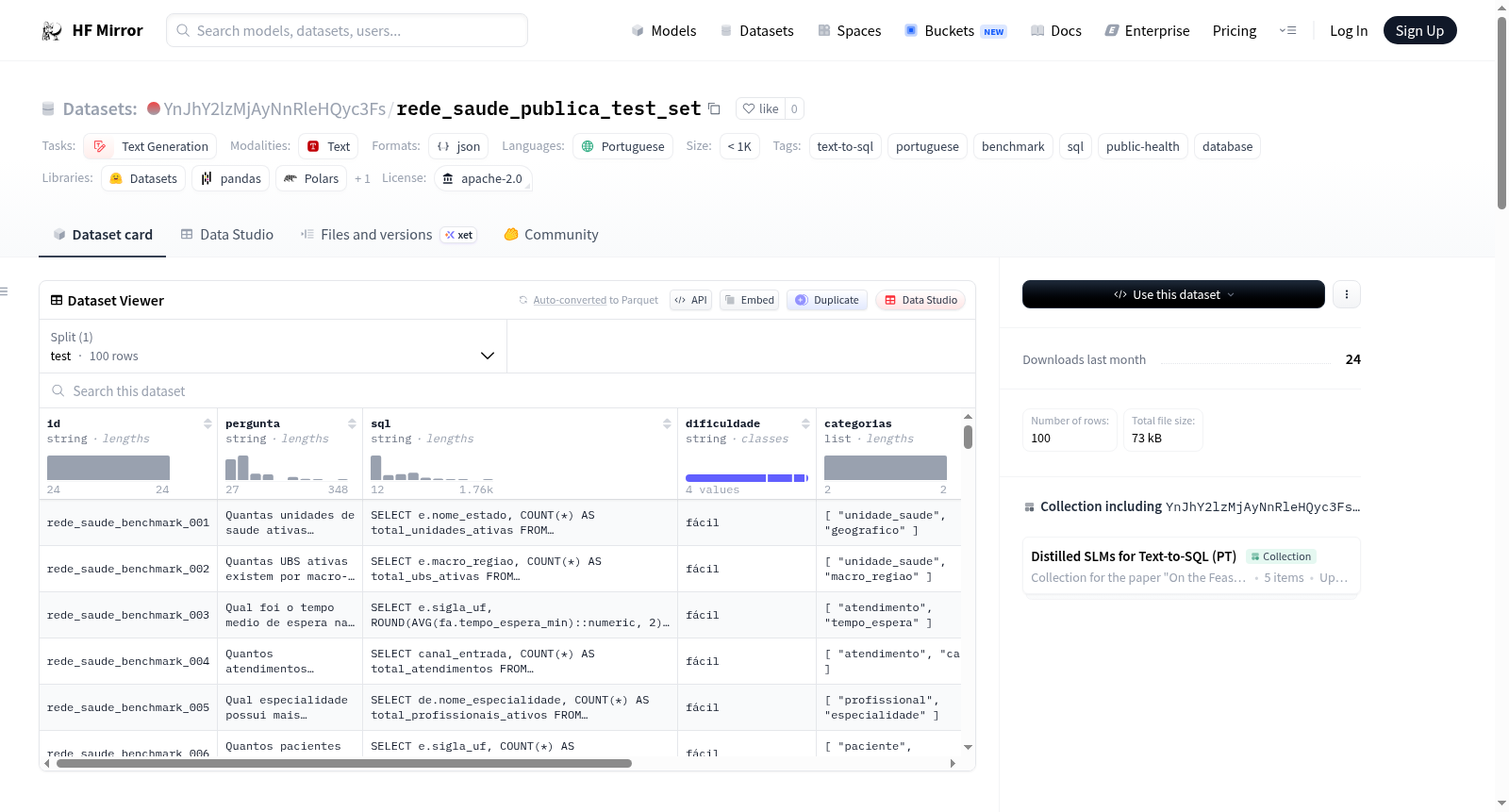
该数据集名为Rede Saude Publica Test Set,是一个用于评估葡萄牙语文本到SQL代理跨数据库泛化能力的基准测试集。数据集包含100行数据,分为50个SQL问题、25个澄清问题和25个不可回答问题。SQL问题根据难度分为16个简单、21个中等、10个困难和3个专家级别。数据集使用巴西葡萄牙语,数据库领域是合成的巴西公共卫生网络,涵盖健康单位、专业人员、患者、预约、住院、床位占用、药品库存和疫苗接种活动等内容。数据集还提供了各列的详细描述,包括ID、问题、SQL、难度标签等。
This dataset is named Rede Saude Publica Test Set and is a benchmark test set for evaluating the cross-database generalization ability of Portuguese text-to-SQL agents. The dataset contains 100 rows of data, divided into 50 SQL questions, 25 clarification questions, and 25 unanswerable questions. The SQL questions are further categorized by difficulty into 16 easy, 21 medium, 10 hard, and 3 expert levels. The dataset uses Brazilian Portuguese and the database domain is a synthetic Brazilian public-health network, covering health units, professionals, patients, appointments, hospitalizations, bed occupancy, medicine stock, and vaccination campaigns. The dataset also provides detailed descriptions of each column, including ID, question, SQL, difficulty labels, etc.
提供机构:
YnJhY2lzMjAyNnRleHQyc3Fs
搜集汇总
数据集介绍
构建方式
该数据集名为rede_saude_publica_test_set,是为评估葡萄牙语Text-to-SQL智能体跨数据库泛化能力而构建的公共健康领域迁移基准。其数据库模式为合成的巴西公共健康网络,涵盖卫生单位、专业人员、患者、预约、住院、床位占用、药品库存及疫苗接种活动等实体。数据集包含100条测试样本,其中50条为SQL可查询问题,25条为需澄清问题,25条为不可回答问题,SQL问题按难度分为16个简单、21个中等、10个困难及3个专家级。每条样本携带自然语言问题、金标准SQL或终止标签、难度标签、主题类别及行序、列数、行数是否关键的语义标志。
特点
该数据集的核心特点在于其作为跨数据库泛化评估的公共健康迁移基准。所有SQL问题均基于未出现在微调模型训练轨迹中的合成模式,从而严格测试模型在新数据库结构上的适应能力。数据集精心设计了可回答、需澄清与不可回答三类问题,覆盖了智能体实际部署中可能遇到的多元场景。SQL问题难度分布广泛,从简单到专家级逐步递进,便于细致刻画模型在不同复杂度下的表现。此外,每一条样本都附带了关于行顺序、列数量和行数量是否重要的元信息,为评估结果提供了更高层次的语义维度。
使用方法
使用者可通过HuggingFace页面直接加载本数据集,并使用配套的GitHub仓库中提供的智能体运行时进行本地评估。评估流程要求搭建PostgreSQL数据库环境,通过Docker Compose启动服务后,利用命令行工具初始化数据库并运行评估脚本。SQL行通过将生成SQL与参考SQL在相同数据库上执行并比对结果来评分,非SQL行则依据终端动作类型进行判定。数据集的Apache 2.0许可允许自由使用与分发,其合成性质避免了真实医疗数据的隐私风险,适用于学术界与工业界对葡萄牙语Text-to-SQL智能体的标准化、可复现迁移测试。
背景与挑战
背景概述
在自然语言处理领域,将非结构化文本转化为可执行的数据库查询语句(Text-to-SQL)一直是人机交互研究的重要前沿。该领域的进展对于提升医疗健康等专业场景的数据获取效率具有深远意义,然而,现有基准测试多聚焦于英语,针对葡萄牙语及公共卫生垂直领域的跨数据库泛化评估则相对匮乏。在此背景下,由匿名的研究人员或研究机构于近期创建的Rede Saude Publica Test Set应运而生。该数据集源于一项关于蒸馏小语言模型(SLM)以提升葡萄牙语Text-to-SQL能力的研究工作,旨在专门评估模型在未见过的数据库模式下的泛化性能。通过构建一个涵盖医疗单位、专业人员、患者、预约、住院、床位占用、药品库存及疫苗接种计划等多元化信息的巴西公共卫生合成数据库,该测试集包含100条样本,精心设计了50个SQL查询问题、25个澄清需求问题及25个不可回答的问题,并细分了难易程度,为葡萄牙语Text-to-SQL代理的跨库泛化能力提供了极具价值的基准标杆,有力推动了该语种在专业应用领域的模型评测发展。
当前挑战
该数据集所解决的领域核心挑战在于实现葡萄牙语Text-to-SQL系统的跨数据库泛化能力。在真实世界中,数据库模式千差万别,模型往往在训练集上表现优异,但面对未见过的表结构、关联关系及领域术语时,性能可能大幅衰减。此测试集专为此设计,揭示了现有模型在泛化至全新公共卫生数据库时的瓶颈。此外,高难度的SQL查询编写(涵盖10个困难与3个专家级问题)、对行序及列数的精确语义要求,以及必须区分可回答SQL问题与需要澄清或不可回答的场景,对模型的鲁棒性与常识推理构成了严峻挑战。在构建过程中,研究者面临的挑战在于如何生成一个既符合巴西公共卫生网络逻辑又具备足够复杂度的合成数据库,同时确保50个查询能够公平覆盖从简单到专家的难度层级,并人为注入真实交互中可能出现的模糊或不可回答提问,从而最大程度模拟实际应用中的不确定性。
常用场景
经典使用场景
在自然语言处理与数据库交互的交叉领域中,Rede Saude Publica Test Set 作为一项面向巴西葡萄牙语的文本到SQL跨数据库泛化基准,其核心使用场景在于评估模型能否在未见过的公共健康领域数据库模式上,准确地将自然语言问题转化为可执行的SQL查询。该数据集精心构建了50个SQL问题、25个澄清问题和25个不可回答问题,并按照难易程度划分为简单、中等、困难与专家四个层级,全面考验了智能体在真实异构数据库环境下的推理与适应能力。通过模拟巴西公共卫生网络的虚拟数据库,涵盖健康机构、专业人员、患者、预约、住院、床位占用、药品库存及疫苗接种等多元主题,该基准为衡量小型语言模型在领域迁移中的鲁棒性提供了标准化测试平台。
实际应用
在实际应用中,Rede Saude Publica Test Set 所代表的技术路径可无缝嵌入巴西公共健康信息系统的智能查询接口,赋能医护人员、行政管理者乃至政策制定者通过自然语言直接获取复杂的数据库信息。例如,基层卫生人员可以用巴西葡萄牙语提问“本月某市流感疫苗接种覆盖率”,系统即可自动生成对应的SQL查询并返回精准统计结果,大幅降低非技术用户的数据获取门槛。此外,该基准驱动的模型在跨数据库部署时展现的强泛化能力,使其能够适应不同区域的医疗健康数据库结构差异,从而支撑起一个可扩展、低成本的自然语言数据库查询服务,无需为每个新数据库单独训练模型。这在实际场景中极大地提升了公共卫生决策的数据响应速度与资源调度效率。
衍生相关工作
围绕Rede Saude Publica Test Set的构建与评估,衍生了一系列具有启发性的经典工作。最直接的是其关联仓库中基于Qwen3-4B和Qwen3.5-27B模型进行知识蒸馏的研究,通过对比基础模型与微调模型在该基准上的性能差异,系统验证了小型语言模型在文本到SQL跨数据库迁移中的有效性。该工作还探索了结合Docker容器化PostgreSQL环境的可复现评估框架,为社区提供了标准化的本地基准测试工具链。此外,该基准提出的非SQL问题评估(澄清与不可回答)分类法,催生了后续关于智能体终止行为建模的研究,推动了对话式文本到SQL系统从简单查询向交互式决策的演变。这些工作共同构成了巴西葡萄牙语自然语言接口领域的重要知识积累,也为其他低资源语言的类似研究提供了方法论范式。
以上内容由遇见数据集搜集并总结生成


