fzmnm/TinyEncyclopedias-Chinese
收藏Hugging Face2024-06-19 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/fzmnm/TinyEncyclopedias-Chinese
下载链接
链接失效反馈官方服务:
资源简介:
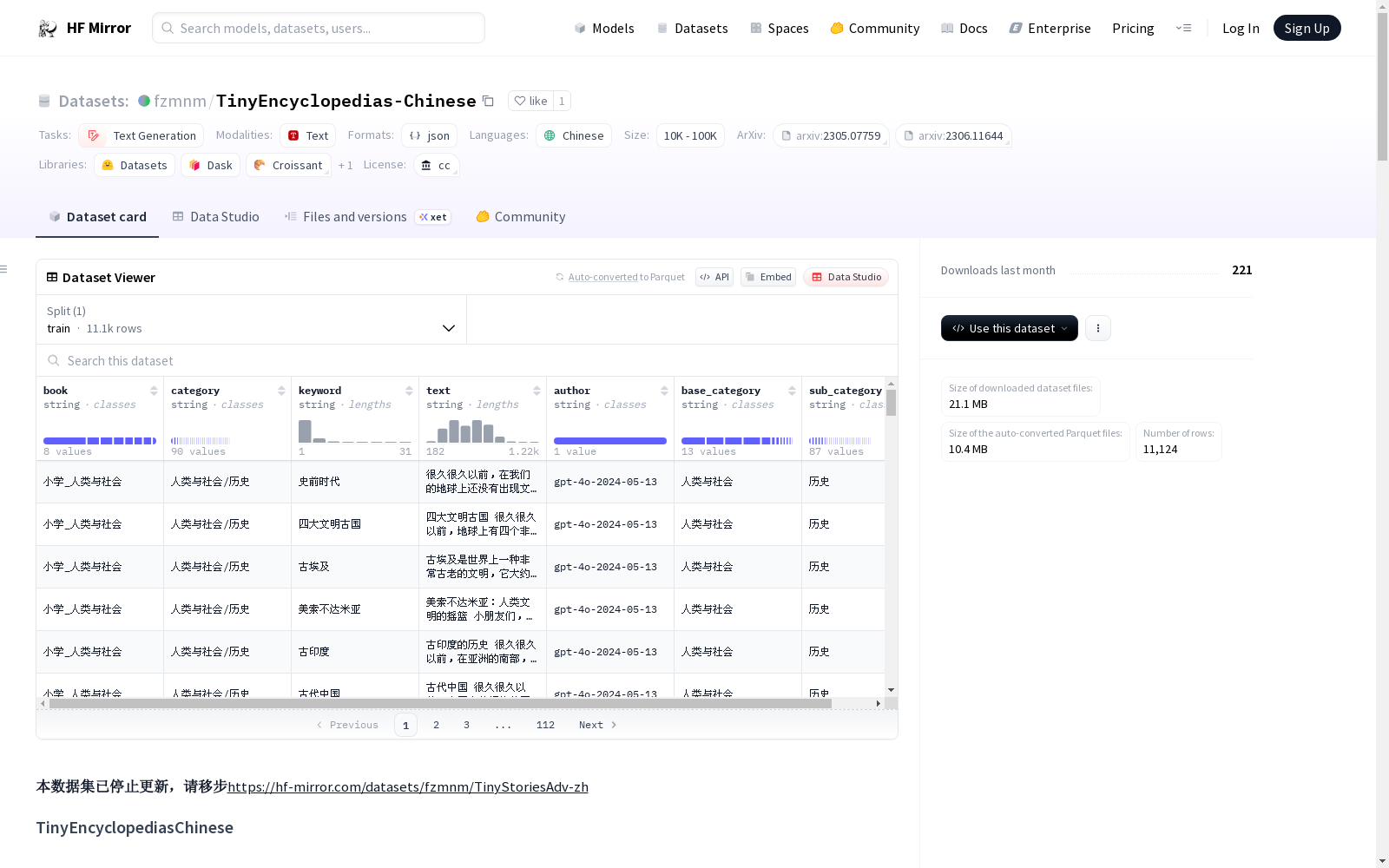
TinyEncyclopediasChinese数据集是一个为幼儿园和小学阶段儿童设计的AI生成百科全书。数据集包含AI生成的百科式短文和用户与AI助手之间的多轮对话,总计654万中文字符。生成过程中使用了特定的提示模板,确保内容适合儿童阅读,并涵盖了STEM、人文和日常常识等多个领域。特别增加了道德教育文章的比例,如如何交朋友、如何应对悲伤等。数据集专注于中文,强调中国文化和日常生活,未进行安全性和事实核查,可能存在不适合儿童的内容或事实错误。
TinyEncyclopediasChinese is an AI-generated encyclopedia-style dataset designed for kindergarten and elementary school children, providing short articles and multi-round QA sessions. The dataset contains 6.54M Chinese characters, covering STEM, humanities, and everyday common sense concepts, with a special emphasis on moral education articles. The dataset focuses on Chinese to avoid language complexities, emphasizing Chinese culture and daily life. The dataset has not yet undergone safety or factual checks and may contain content inappropriate for children or factual inaccuracies.
提供机构:
fzmnm
原始信息汇总
TinyEncyclopediasChinese
数据集概述
- 许可证:cc
- 任务类别:text-generation
- 语言:zh
- 数据量:10K<n<100K
数据集内容
- 总字符数:6.54M
- 内容类型:
- AI合成的百科式短文
- AI合成的用户与AI代理之间的多轮QA对话
生成方式
-
百科短文生成提示: python
分类:{path} 以“{keyword}”为题,编写一段适合小学生/幼儿园小朋友阅读的科普小短文。
-
QA对话生成提示: python
分类:{path} 以“{keyword}”为题,编写一段适合小学生和人工智能助手之间的多轮对话。一共10轮。要求语言生动活泼。格式: 问: 答:
数据集特点
- 分类和关键词:结合AI和人工输入,涵盖STEM、人文和日常常识概念。
- 道德教育文章:增加道德教育文章比例,如交友、应对悲伤、帮助父母做家务等。
- 语言专注:专注于中文,强调中国文化和日常生活。
- 质量保证:直接用中文编写,确保内容准确性和相关性。
注意事项
- 安全性和事实性:数据集尚未进行安全或事实性检查,可能包含不适合儿童的内容或事实错误。
搜集汇总
数据集介绍
构建方式
本数据集通过人工智能技术生成,包含科普短文及人机对话形式的QA会话。其构建过程主要采用AI合成的方式,以特定模板生成适合小学生和幼儿园小朋友的科普文章,同时辅以多轮人机对话形式,以增强语言模型的交互能力。
特点
本数据集的特点在于其内容均为针对儿童的人工智能生成文本,涵盖了基础的STEM、人文及日常生活常识概念。特别强调了道德教育文章的比例,旨在通过生动的故事和对话,提升AI在多模态任务中的表现,并加强中文语言及文化的特色。
使用方法
用户可通过HuggingFace提供的平台访问和下载数据集。使用时,可以直接将数据集应用于语言模型训练,尤其是针对儿童科普教育和多模态交互任务的模型训练。同时,用户需要自行对数据内容进行筛选,确保其符合实际应用场景的需求,并注意数据中可能存在的安全隐患。
背景与挑战
背景概述
在当前机器学习研究领域,构建针对儿童教育的高质量中文文本数据集愈发受到重视。TinyEncyclopedias-Chinese数据集,创建于2023年,由研究人员基于先前TinyBooksChinese的研究成果进一步发展而来。该数据集以AI生成的科普短文和多轮对话形式,涵盖了基础STEM、人文及日常生活常识等多个领域,旨在为机器学习模型提供适合儿童阅读的、富含教育意义的内容。数据集的生成注重中文语言文化的特色,并强调了对道德教育类文章的编纂,以期为AI提供关于人类交互的基本概念预习。该数据集的推出,不仅丰富了中文教育类数据集的多样性,也为相关领域的研究提供了新的资源,对于推动数据效率化机器学习研究具有一定的贡献。
当前挑战
尽管TinyEncyclopedias-Chinese数据集在教育和语言学习领域具有显著的应用潜力,但其在构建过程中同样面临诸多挑战。首先,数据集的生成完全依赖AI合成,尚未实施安全性和事实性检查,可能导致包含不适合儿童的内容和不准确信息。其次,数据集在构建过程中需确保文章和对话的质量及教育价值,这对于AI生成内容的准确性和适用性提出了较高要求。此外,数据集在多模态任务能力上的增强也面临技术挑战,需要不断优化数据合成策略以提高学习效果。
常用场景
经典使用场景
在文本生成任务中,TinyEncyclopedias-Chinese数据集以其高质量、适合儿童阅读的科普文章,成为训练小型语言模型以展现强大能力的典范。该数据集的运用,不仅促进了多模态任务能力的提升,也丰富了机器学习模型的训练素材,使其在处理儿童故事相关的文本生成任务时,表现出更为细腻和贴合儿童心理的特点。
实际应用
在实际应用中,该数据集可用于教育领域,支持开发面向儿童的人工智能教育产品,如智能故事书、科普问答系统等。同时,它也可以作为训练材料,用于提升机器翻译、文本摘要等自然语言处理技术的性能,特别是在中文语境下。
衍生相关工作
基于TinyEncyclopedias-Chinese数据集,研究者可以开展多项衍生工作,如构建更适合儿童的人工智能模型、开发道德教育相关的应用,以及探索多模态交互在儿童教育中的应用。这些工作将进一步推动儿童教育技术的发展,并可能对特殊教育领域产生积极影响。
以上内容由遇见数据集搜集并总结生成


