data-archetype/bg_photo_concepts_bucketed_1024
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/data-archetype/bg_photo_concepts_bucketed_1024
下载链接
链接失效反馈官方服务:
资源简介:
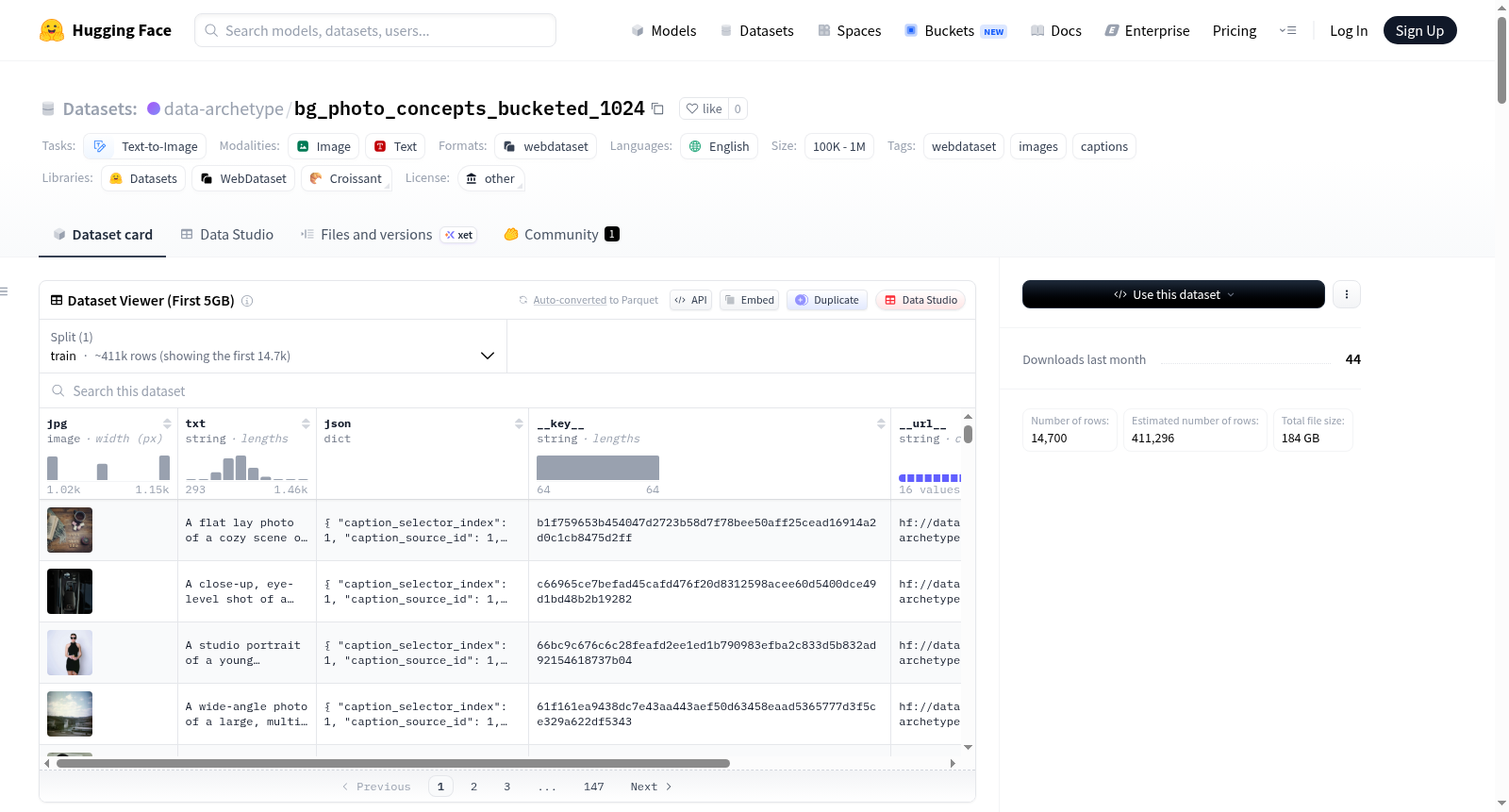
bghira_photo_concepts_bucketed_1024是一个用于文本到图像任务的WebDataset格式数据集,包含分桶处理的图像和对应的文本描述。数据集采用SDXL风格的分桶策略,基于1024×1024的分辨率,支持多种分辨率调整和图像预处理(如重新编码JPEG、调整大小和裁剪)。每张图像配有UTF-8编码的文本描述和JSON格式的元数据(包括分辨率、图像模式等)。数据集还提供了详细的标题选择策略,优先使用Gemini和Mistral模型生成的标题。适用于需要高效加载和处理的图像生成任务。
bghira_photo_concepts_bucketed_1024 is a WebDataset-formatted dataset for text-to-image tasks, containing bucketed images and corresponding text captions. The dataset uses an SDXL-style bucketing strategy based on 1024×1024 resolution, supporting multiple resolution adjustments and image preprocessing (e.g., JPEG re-encoding, resizing, and cropping). Each image is accompanied by a UTF-8 encoded text caption and JSON metadata (including resolution, image mode, etc.). The dataset also provides detailed caption selection strategies, prioritizing captions generated by Gemini and Mistral models. Suitable for image generation tasks requiring efficient loading and processing.
提供机构:
data-archetype
搜集汇总
数据集介绍
构建方式
该数据集以分桶分片(bucketed-shards)格式构建,基于SDXL风格的原始桶(proto buckets),以1024×1024为基础分辨率,并延伸至768和512分辨率。图像预处理采用确定性流程,包括EXIF转置、RGB转换、基于torch CPU双三次插值的覆盖缩放(cover-resize),且默认不执行上采样,过小样本被丢弃。缩放后依据样本键的SHA256哈希从指定角落裁剪至桶目标尺寸。JPEG编码质量设为95,采用自适应子采样策略。数据集通过瀑布式优先规则选择标注文本,优先采用最新且优先级最高的标注来源。
特点
该数据集包含超过56万张图像,涵盖丰富的宽高比分布,从1:1正方形到4:1超宽幅面,有效模拟真实世界的视觉多样性。每张图像均附带文本、JPEG字节及包含宽高、标注来源等信息的JSON元数据。标注文本经由多重模型生成,包括Google Gemini 3 Flash Preview、Gemini及Mistral Medium 3.1,优先选用质量最高的标注。缺失标注的样本被直接丢弃,确保数据质量。数据集的桶化设计便于按分辨率或宽高比灵活采样。
使用方法
推荐以webdataset风格顺序读取TAR分片,在分片级别及分片内部进行洗牌以平衡随机性与吞吐量。可通过manifest.json全局清单遍历桶和分片列表。Python用户可利用webdataset库加载图像、标注及元数据,或基于tarfile模块手动解析。加载时可根据manifest.json中存储的目标宽高信息动态调整图像尺寸,也可在运行时应用EXIF方向并执行缩放裁剪操作,以适应不同训练或推理场景的需求。
背景与挑战
背景概述
在文本到图像生成模型迅猛发展的背景下,高质量、大规模且经过精细预处理的图像-文本配对数据集成为推动模型性能提升的关键基石。bghira_photo_concepts_bucketed_1024数据集由研究者在2026年创建,旨在为SDXL等扩散模型提供一套标准化、高效加载的图文数据资源。该数据集基于bghira_photo_concepts_core原始数据,通过先进的分桶(bucketed-shards)与瀑布式标题选择(waterfall caption selection)技术,构建了涵盖超过56万张图像的异构分辨率样本集。其核心创新在于采用1024基分辨率的多尺度分桶策略,解决了不同长宽比图像在统一训练中的适配难题,对提升文本到图像生成模型的视觉质量与构图多样性具有重要推动作用,尤其在摄影概念理解与精细化图像描述领域产生了深远影响。
当前挑战
该数据集面临的核心挑战包括:领域问题层面,文本到图像生成任务长期受困于图像分辨率单一导致的构图僵化与细节丢失,传统固定尺寸数据集难以覆盖真实世界的多样长宽比,而该数据集通过SDXL风格的分桶机制,将不同尺度的图像按目标分辨率归类,处理了从1:2到4:1的宽泛长宽比分布,有效缓解了此问题。构建过程层面,挑战体现在多源标题的优先级融合与质量降噪,数据集采用基于时间戳的瀑布式选择策略,从Gemini、Mistral等不同模型生成的标题中择优保留,需解决不同模型风格差异与标注噪声问题;同时,为维持数据一致性,图像预处理采用了严格的cover-resize与角点裁剪策略,并设置了“never upsample”规则以剔除需放大的低分辨率样本,这些精细的过滤逻辑在保证数据质量的同时,也增加了构建流程的复杂性与计算开销。
常用场景
经典使用场景
在文本到图像生成的学术研究中,bg_photo_concepts_bucketed_1024数据集作为高质量、多分辨率的图文对资源,被广泛用于训练和评估扩散模型,尤其是以Stable Diffusion XL(SDXL)为代表的潜在扩散模型。该数据集将图像按预设的长宽比进行分桶(bucketing)处理,并采用阶梯式下降的封面缩放与角点裁剪策略,确保输入图像在不被放大的前提下适配模型的目标分辨率。研究者通常利用此数据集进行条件生成模型的微调(fine-tuning),以提升模型对多样化构图和复杂语义描述的响应能力。其高效的webdataset格式支持大规模分布式训练,使得模型能够在包含不同宽高比的自然图像分布中学习到更为鲁棒的视觉语义映射关系。
解决学术问题
该数据集的核心学术贡献在于解决了图像生成模型中训练数据宽高比单一化导致的生成结果僵化问题。传统数据集常将所有图像强制缩放至固定正方形,造成细长或宽幅图像的构图信息与文本语义的错配。bg_photo_concepts_bucketed_1024通过保留原始图像的宽高比分布,并利用分桶策略对相似比例的样本进行归组,使得模型能够学习到不同构图下的空间布局规律。此外,数据集采用瀑布式字幕选择机制,优先使用Gemini和Mistral等大语言模型生成的精细描述,缓解了图文语义对齐不足的问题,为文本到图像生成中的细粒度控制与多样性研究提供了标准化训练基线。
衍生相关工作
基于该数据集的特性,学术界与工业界衍生出多项代表性工作。在模型架构方面,研究者提出了针对分桶策略的宽高比感知条件注入模块,使得扩散模型在训练过程中能够显式地利用bucket_id编码的几何先验,显著提升了异构分辨率下的生成质量。在文本编码器端,部分工作利用数据集的多源字幕数据训练语义对齐器,将CLIP文本特征的固定空间映射到更丰富的视觉概念空间。此外,围绕该数据集的水印与字幕选择机制,涌现出关于数据溯源与合成数据质量评估的研究,推动了数据集治理与干净训练范式的发展。这些衍生工作共同强化了数据集作为学术基准的影响力,并持续拓展了其在高保真文本到图像生成领域的应用边界。
以上内容由遇见数据集搜集并总结生成


