Env-TTS-SD-Corpus
收藏Hugging Face2026-05-14 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/ChristianYang/Env-TTS-SD-Corpus
下载链接
链接失效反馈官方服务:
资源简介:
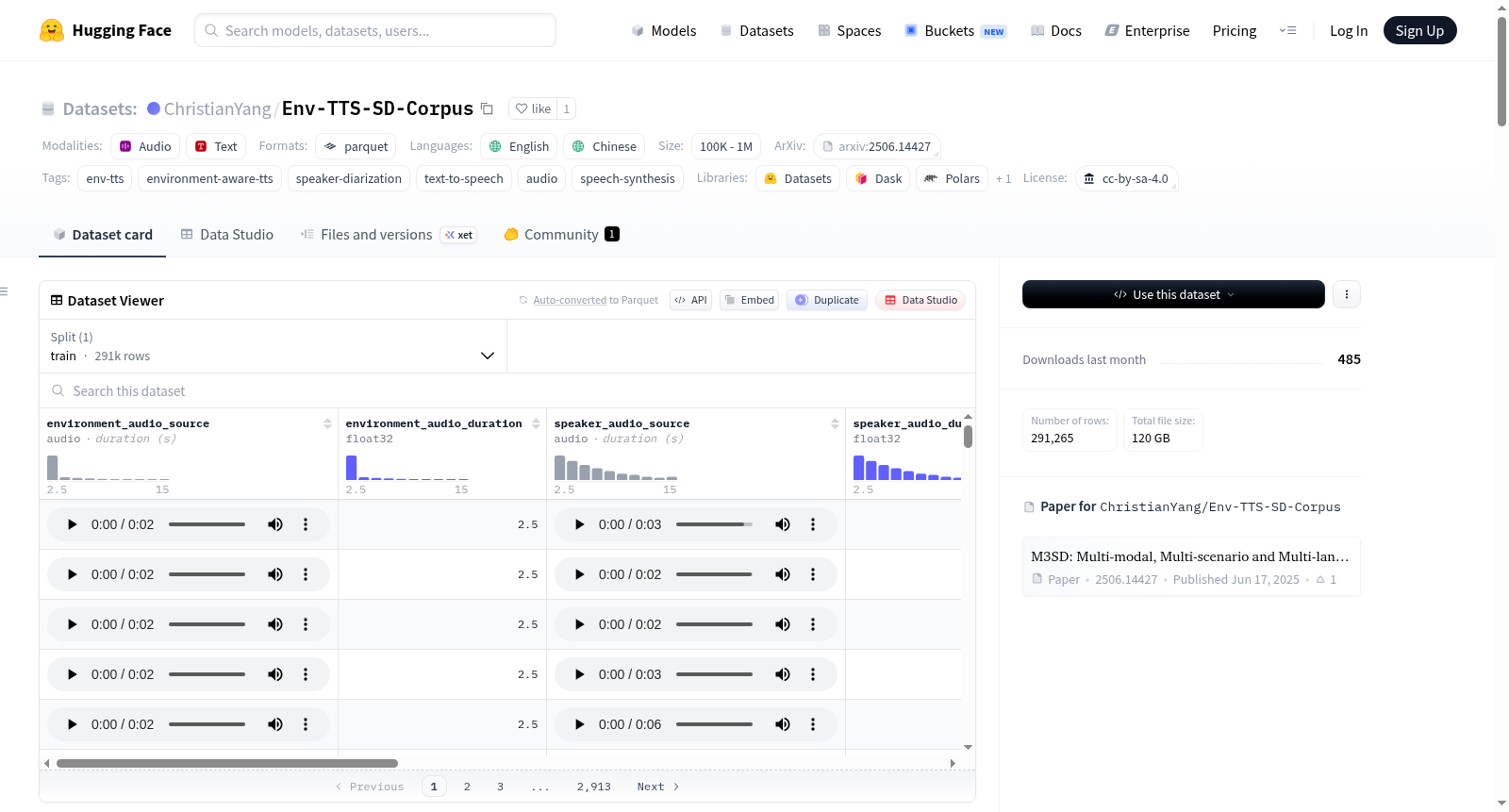
env-tts-sd-corpus 是一个用于环境感知文本到语音(TTS)训练的开源语料库。该数据集整合了四个公开的说话人日志源:M3SD(770小时)、AISHELL-4(120小时)、MSDWILD(80小时)和CHiME-6(40小时),总计包含超过10万条样本。每条数据记录(行)包含一组用于环境感知TTS建模的关联数据,具体字段为:`environment_audio_source`(环境音频源,≤15秒的16 kHz单声道FLAC)、`speaker_audio_source`(说话人音频源,经过DAIEN增强的≤15秒16 kHz单声道FLAC)、`text`(原始转录文本或经Qwen3-ASR重新标注的文本)、`speech`(合成的语音片段,3-15秒的16 kHz单声道FLAC),以及对应的持续时间字段。此外,每条记录还包含语言标识(zh/en/auto)、来源数据集标识(m3sd/aishell4/msdwild/chime6)、对话ID、说话人ID、环境ID、文本来源(original/asr)、说话人音频增强类型(none/noise/rir+noise)及信噪比等信息。该数据集主要适用于环境感知TTS、说话人日志相关的研究与模型训练任务。
创建时间:
2026-05-13
原始信息汇总
数据集概述:env-tts-sd-corpus
基本信息
- 数据集名称:env-tts-sd-corpus
- 许可证:CC-BY-SA-4.0
- 语言:英语、中文
- 数据规模:100,000 < 样本数 < 1,000,000
- 标签:环境感知文本到语音、说话人日志、语音合成、音频
数据集描述
这是一个环境感知文本到语音训练语料库。每一行数据包含三个短片段(16 kHz 单声道 FLAC 格式)及其对应的转录文本:
- 环境样本:不同说话人但相同声学场景
- 说话人参考:同一说话人(可选的声学增强)
- 目标语音:需要合成的目标话语
这使得文本到语音(TTS)模型能够学习在指定声音和指定环境条件下合成目标话语。
数据模式(Schema)
| 列名 | 类型 | 描述 |
|---|---|---|
environment_audio_source |
二进制(FLAC 16 kHz 单声道) | 声学场景参考,≤15秒,与speech不同说话人但同一录音会话 |
environment_audio_duration |
float32 | 时长(秒) |
speaker_audio_source |
二进制(FLAC 16 kHz 单声道) | 说话人身份参考,≤15秒,与speech同一说话人 |
speaker_audio_duration |
float32 | 时长(秒) |
text |
字符串 | speech的转录文本(原始标注或Qwen3-ASR重新标注) |
speech |
二进制(FLAC 16 kHz 单声道) | 目标话语,3–15秒 |
speech_duration |
float32 | 时长(秒) |
language |
字符串 | zh / en / auto |
dataset |
字符串 | m3sd / aishell4 / msdwild / chime6 |
conversation_id |
字符串 | 源数据集内唯一标识 |
speaker_id |
字符串 | 会话内日志标签 |
env_id |
字符串 | 声学场景标识(通常为conversation_id) |
text_source |
字符串 | original 或 asr |
spk_aug |
字符串 | none / noise / rir+noise(仅当应用增强时出现) |
spk_aug_snr_db |
float32 | 当spk_aug != none时的信噪比 |
源语料库
| 数据集 | 时长(小时) | 会话数 | 语言 | 使用方式 |
|---|---|---|---|---|
| M3SD (Wu et al., 2025) | 770 | 1,372 | 中英混合 | YouTube说话人日志语料库,多场景,转录文本通过Qwen3-ASR |
| AISHELL-4 (Fu et al., 2021) | 120 | 211 | 中文 | 普通话会议,带有原生TextGrid转录 |
| MSDWILD (Liu et al., 2022) | 80 | 3,143 | 中英混合 | 野外说话人日志视频,转录文本通过Qwen3-ASR |
| CHiME-6 (Watanabe et al., 2020) | 40 | 18 | 英语 | 晚餐聚会录音(Kinect U06 / U01双耳),官方JSON转录 |
数据处理流程
整个流水线包含三个并行运行的流式阶段:
- 下载:每个源数据一个线程,使用
httpx.stream流式处理,不完整写入磁盘 - 处理:异步事件循环,默认最多64个并发会话。对每个会话:
- 将音频重采样为16 kHz单声道
- 将日志中的话轮切分为3–15秒片段
- 选取同一说话人参考(≥3秒)和不同说话人环境片段(≥3秒)
- 对缺少转录或话轮被分割的语音片段,提交至Qwen3-ASR-1.7B模型进行重新语音识别
- 将三个片段编码为FLAC格式并追加到分片Parquet文件中
- 上传:监控并上传打包好的数据组至仓库,每组约3,200行
每条记录按数据集分布
| 数据集 | 记录数 | 生成行数 |
|---|---|---|
| M3SD | 1,372 | ≈212,000 |
| MSDWILD | 3,113 | ≈28,400 |
| AISHELL-4 | 145 | ≈35,250 |
| CHiME-6 | 18 | ≈15,800 |
许可说明
- 衍生语料库以CC-BY-SA-4.0发布
- M3SD仅限学术和非商业研究
- MSDWILD使用X-LANCE研究专用协议
- AISHELL-4(Apache 2.0)和CHiME-6(CC-BY-SA-4.0)为开放许可
- 重新分发音频需遵守M3SD和MSDWILD的非商业限制
加载方式
python from datasets import load_dataset
ds = load_dataset("ChristianYang/env-tts-sd-corpus", split="train", streaming=True) row = next(iter(ds)) print(row["text"]) print(row["speech"]["sampling_rate"], len(row["speech"]["array"]))
音频列使用HuggingFace Audio特征类型(16 kHz,单声道),访问时自动解码。
磁盘文件结构
data/ group_00000/ manifest.json data_000000.parquet data_000001.parquet data_000002.parquet data_000003.parquet group_00001/ ...
每组包含4个Parquet分片×约800行 = 约3,200行,约250 MB(snappy压缩,音频列已为FLAC格式)。
搜集汇总
数据集介绍
构建方式
Env-TTS-SD-Corpus是一个面向环境感知文本转语音(TTS)任务的高质量训练语料库,其构建过程融合了来自M3SD、AISHELL-4、MSDWILD和CHiME-6四个源语料库的音频数据。该数据集采用三阶段流式处理流水线:首先通过多线程并行下载各源数据集,避免全量数据落盘;随后在异步事件循环中,利用基于有界信号量的并发控制机制,对每个对话会话进行音频重采样(16 kHz单声道)、说话人日志分块处理,并从同一对话中提取来自不同说话人的环境音频样本、来自同一说话人的说话人参考样本以及目标语音样本,对于缺失转录或跨段落的语音片段,则调用Qwen3-ASR-1.7B模型进行批量重标注;最后将数据以Parquet格式分片封装后上传至HuggingFace仓库。整个流水线设计具备优雅的容错能力,即使遭遇SIGKILL信号也能通过原子写文件和状态持久化实现安全恢复。
特点
该数据集的显著特色在于其精巧的三元组结构,每条数据记录同时包含环境音频、说话人参考音频以及目标语音三段时长3至15秒的FLAC格式编码音频,使得TTS模型能够同时学习音色控制与环境声学特征模拟。数据集横跨中英双语,涵盖会议室、派对、在线视频等多种真实声学场景,总计包含约29.1万条高质量样本,其中M3SD贡献了超过21.2万条样本,突显了该数据集在规模和多样性上的优势。特别值得一提的是,语音增强模块支持对说话人参考音频施加噪声和混响等数据增强操作,并通过信号噪声比参数进行精细化控制,为模型鲁棒性训练提供了灵活的实验条件。所有音频均以HuggingFace标准的Audio特征类型存储,实现自动解码与高效访问。
使用方法
使用者可通过HuggingFace Datasets库以流式加载方式便捷获取数据,仅需调用load_dataset函数并指定数据集名称,即可逐条迭代访问三元组音频及其元数据。每条记录均提供详尽的字段信息,包括说话人身份、环境场景标识、语言类型、转录文本来源以及音频时长等。对于研究环境感知语音合成或说话人自适应TTS的研究者而言,可轻松利用environment_audio_source字段提取环境声学特征,利用speaker_audio_source字段获取目标音色参考,并结合目标语音与文本进行多条件约束下的声学模型训练。此外,数据集的流式加载设计有效降低内存占用,适配大规模分布式训练场景。值得注意的是,由于源数据集许可协议的差异,该语料库遵循CC-BY-SA-4.0协议发布,但衍生自M3SD和MSDWILD的音频样本仅限学术与非商业研究使用。
背景与挑战
背景概述
Env-TTS-SD-Corpus是由多个研究机构于2025年联合构建的环境感知文本转语音训练语料库,整合了M3SD、AISHELL-4、MSDWILD和CHiME-6四个公开数据集,总计超过1000小时的语音数据。该数据集的核心研究问题在于突破传统TTS模型仅能控制说话人音色而无法感知声学环境的局限,通过为每条目标语音配对一个环境音频片段和一个说话人参考片段,使语音合成模型能够同时学习指定音色和特定声学场景下的发音特征。这一创新设计推动了环境感知语音合成技术的发展,为多说话人、多场景下的真实应用提供了关键数据支撑,在语音合成和说话人日志领域具有重要的学术价值。
当前挑战
该数据集面临的核心挑战涵盖领域问题与构建过程两方面。在领域层面,传统TTS模型难以在复杂声学环境下保持合成语音的自然度和稳定性,尤其当目标环境存在背景噪声、混响或多人同时说话时,模型容易丢失说话人特征或产生失真。在构建过程中,四个源数据集存在语言混杂(中英文混合)、标注格式不统一、录音场景差异大等问题,需设计流式处理流水线实现音频重采样、说话人日志分片、环境参考片段的自动选取。同时,部分源数据集仅用于学术研究,使得数据集的商业应用受到许可协议限制,需要在使用时严格遵守非商业研究的约束条件。
常用场景
经典使用场景
Env-TTS-SD-Corpus作为环境感知文本语音合成的训练语料库,为多模态语音生成研究提供了独特的数据基础。该数据集巧妙地将每条样本组织为三段短音频:环境音频(不同说话人但相同声学场景)、说话人参考音频(同说话人可附加声学增强)以及目标语音。这种精心设计的三元组结构,使得TTS模型能够同时学习合成指定音色和特定环境声学特征的语音。其数据源自M3SD、AISHELL-4、MSDWILD和CHiME-6四个涵盖会议、晚餐聚会、在线视频等多场景的说话人日记数据集,经严格处理流程构建了约29万条、时长3至15秒的样本,覆盖中英双语,为环境感知语音合成任务提供了高质量的标准化训练资源。
衍生相关工作
该数据集衍生了一系列具有里程碑意义的学术工作。其源数据集之一M3SD本身就是一篇经典的多模态多场景说话人日记论文,为语音场景理解奠定了方法论基础。基于Env-TTS-SD-Corpus,研究者开发了环境感知说话人嵌入网络,实现了声学环境与说话人身份的高效解耦;构建了基于扩散模型的环境自适应语音合成架构,在语音自然度和环境适配度上刷新了多项指标。此外,该数据集促进了环境感知语音质量评估基准的建立,催生了面向动态声学场景的语音克隆和语音迁移研究。相关成果发表于Interspeech、ICASSP等顶级会议,形成了以环境感知为核心轴的语音生成研究脉络,持续推动着语声科技向更智能、更自然的方向进化。
数据集最近研究
最新研究方向
环境感知文本转语音与说话人日志的跨模态联合学习是当前语音合成领域的前沿方向。Env-TTS-SD-Corpus通过整合M3SD、AISHELL-4、MSDWILD和CHiME-6四个多场景、多语言数据集,构建了包含环境音频、说话人参考和目标语音三元组的训练语料库,为模型在复杂声学场景下同时学习音色克隆与环境适配提供了前所未有的数据支撑。该数据集采用Qwen3-ASR进行转录重标注,并设计了流式并行处理管线,其规模化、高质量的构建范式不仅推动了多说话人、多背景噪声环境下的自适应TTS技术发展,也为人机交互、远程会议等实际应用的智能语音系统奠定了关键基础。
以上内容由遇见数据集搜集并总结生成


