中国陆域及周边逐日1km全天候地表温度数据集(TRIMS LST;2000-2025)
收藏国家青藏高原科学数据中心2026-05-11 更新2024-03-01 收录
下载链接:
https://data.tpdc.ac.cn/zh-hans/data/05d6e569-6d4b-43c0-96aa-5584484259f0
下载链接
链接失效反馈官方服务:
资源简介:
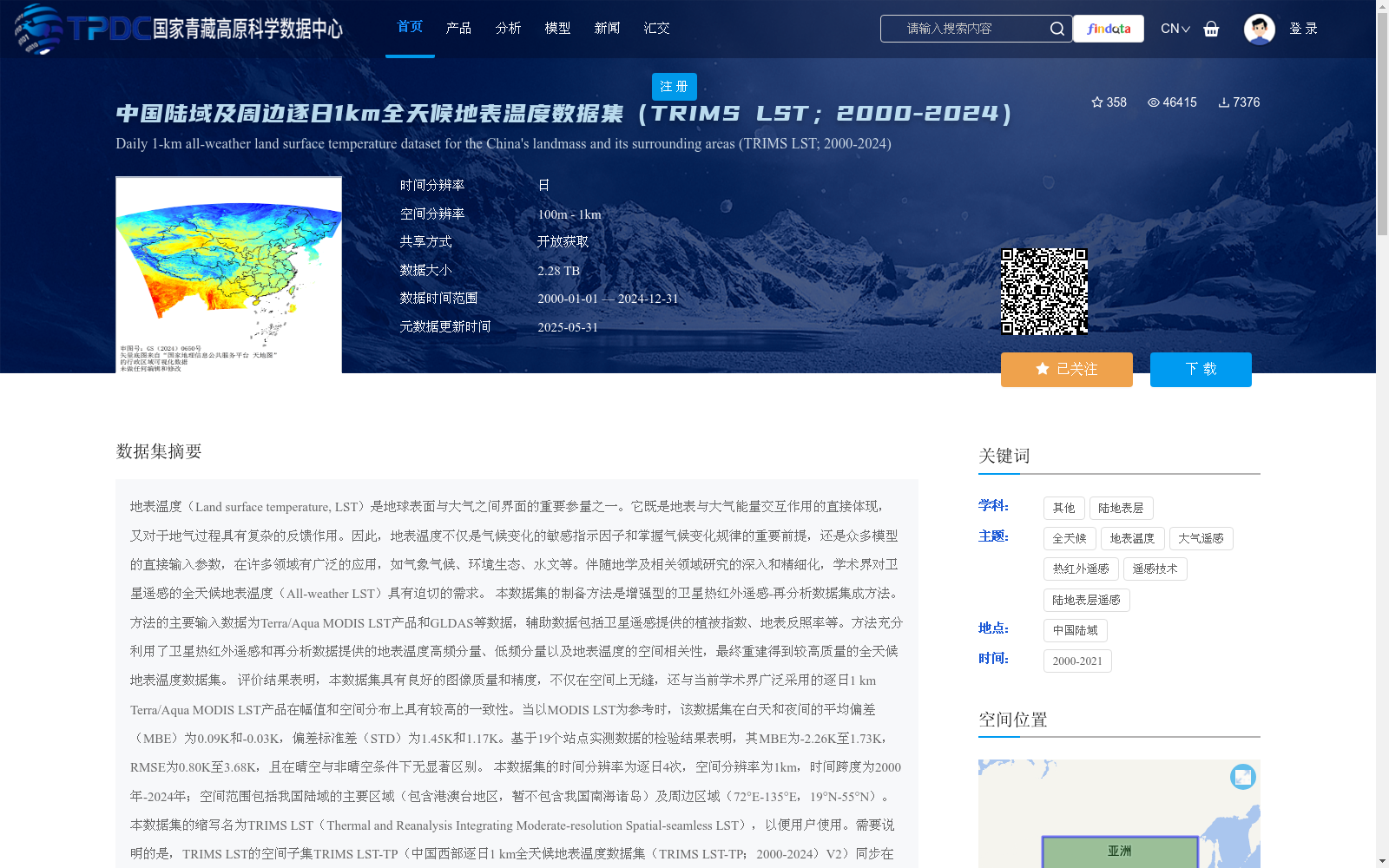
地表温度(Land surface temperature, LST)是地球表面与大气之间界面的重要参量之一。它既是地表与大气能量交互作用的直接体现,又对于地气过程具有复杂的反馈作用。因此,地表温度不仅是气候变化的敏感指示因子和掌握气候变化规律的重要前提,还是众多模型的直接输入参数,在许多领域有广泛的应用,如气象气候、环境生态、水文等。伴随地学及相关领域研究的深入和精细化,学术界对卫星遥感的全天候地表温度(All-weather LST)具有迫切的需求。
本数据集的制备方法是增强型的卫星热红外遥感-再分析数据集成方法。方法的主要输入数据为Terra/Aqua MODIS LST产品和GLDAS等数据,辅助数据包括卫星遥感提供的植被指数、地表反照率等。方法充分利用了卫星热红外遥感和再分析数据提供的地表温度高频分量、低频分量以及地表温度的空间相关性,最终重建得到较高质量的全天候地表温度数据集。
评价结果表明,本数据集具有良好的图像质量和精度,不仅在空间上无缝,还与当前学术界广泛采用的逐日1 km Terra/Aqua MODIS LST产品在幅值和空间分布上具有较高的一致性。当以MODIS LST为参考时,该数据集在白天和夜间的平均偏差(MBE)为0.09K和-0.03K,偏差标准差(STD)为1.45K和1.17K。基于19个站点实测数据的检验结果表明,其MBE为-2.26K至1.73K,RMSE为0.80K至3.68K,且在晴空与非晴空条件下无显著区别。
本数据集的时间分辨率为逐日4次,空间分辨率为1km,时间跨度为2000年-2025年;空间范围包括我国陆域的主要区域(包含港澳台地区,暂不包含我国南海诸岛)及周边区域(72°E-135°E,19°N-55°N)。本数据集的缩写名为TRIMS LST(Thermal and Reanalysis Integrating Moderate-resolution Spatial-seamless LST),以便用户使用。需要说明的是,TRIMS LST的空间子集TRIMS LST-TP(中国西部逐日1 km全天候地表温度数据集(TRIMS LST-TP;2000-2025)V2)同步在国家青藏高原科学数据中心发布,以减少相关用户数据下载和处理的工作量。
Land Surface Temperature (LST) is one of the critical parameters at the interface between the Earth's surface and the atmosphere. It directly reflects the energy interaction between the land surface and the atmosphere, and exerts complex feedback effects on land-atmosphere coupling processes. Therefore, LST not only serves as a sensitive indicator of climate change and a key prerequisite for understanding climate change patterns, but also acts as a direct input parameter for numerous models, with wide applications in various fields such as meteorology, climatology, environmental ecology, and hydrology. With the in-depth and refined research in geoscience and related disciplines, the academic community has an urgent demand for all-weather Land Surface Temperature (All-weather LST) derived from satellite remote sensing.
The dataset is developed using an enhanced satellite thermal infrared remote sensing-reanalysis data integration method. The main input data of this method include Terra/Aqua MODIS LST products and GLDAS (Global Land Data Assimilation System) data, while the auxiliary data cover vegetation indices, surface albedo and other products provided by satellite remote sensing. This method fully leverages the high-frequency and low-frequency components of LST as well as the spatial correlation of LST provided by satellite thermal infrared remote sensing and reanalysis data, finally reconstructing a high-quality all-weather LST dataset.
Evaluation results demonstrate that this dataset features excellent image quality and accuracy, being not only spatially seamless, but also exhibiting high consistency with the widely used daily 1 km Terra/Aqua MODIS LST products in terms of magnitude and spatial distribution. Taking MODIS LST as the reference, the Mean Bias Errors (MBE) of this dataset during daytime and nighttime are 0.09 K and -0.03 K, respectively, and the Standard Deviations of Bias (STD) are 1.45 K and 1.17 K, respectively. Validation based on in-situ measurements from 19 meteorological stations shows that the MBE ranges from -2.26 K to 1.73 K, and the Root Mean Square Errors (RMSE) range from 0.80 K to 3.68 K, with no significant difference between clear-sky and non-clear-sky conditions.
The temporal resolution of this dataset is 4 times per day, with a spatial resolution of 1 km, and the temporal coverage spans from 2000 to 2024. The spatial extent covers the main terrestrial areas of China (including Hong Kong, Macao and Taiwan, excluding the South China Sea Islands temporarily) and its surrounding regions (72°E–135°E, 19°N–55°N). The abbreviation of this dataset is TRIMS LST (Thermal and Reanalysis Integrating Moderate-resolution Spatial-seamless LST) for user convenience. It should be noted that the spatial subset of TRIMS LST, namely TRIMS LST-TP (Daily 1 km All-weather Land Surface Temperature Dataset over Western China (TRIMS LST-TP; 2000–2024) V2), is simultaneously released at the National Tibetan Plateau Data Center to reduce the workload of data downloading and processing for relevant users.
提供机构:
周纪,张晓东,唐文彬,丁利荣,马晋,张旭
创建时间:
2021-04-09
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个覆盖中国陆域及周边地区(72°E-135°E,19°N-55°N)的逐日1km全天候地表温度数据集,时间跨度为2000年至2024年,具有高时空分辨率(逐日4次,1km)。它采用卫星热红外遥感与再分析数据集成方法制备,确保了数据的无缝空间覆盖和高精度,与MODIS LST产品一致性良好,适用于气象气候、环境生态等多领域研究。数据集以开放获取方式共享,提供GEOTIFF和NETCDF格式,便于用户直接处理和分析。
以上内容由遇见数据集搜集并总结生成


