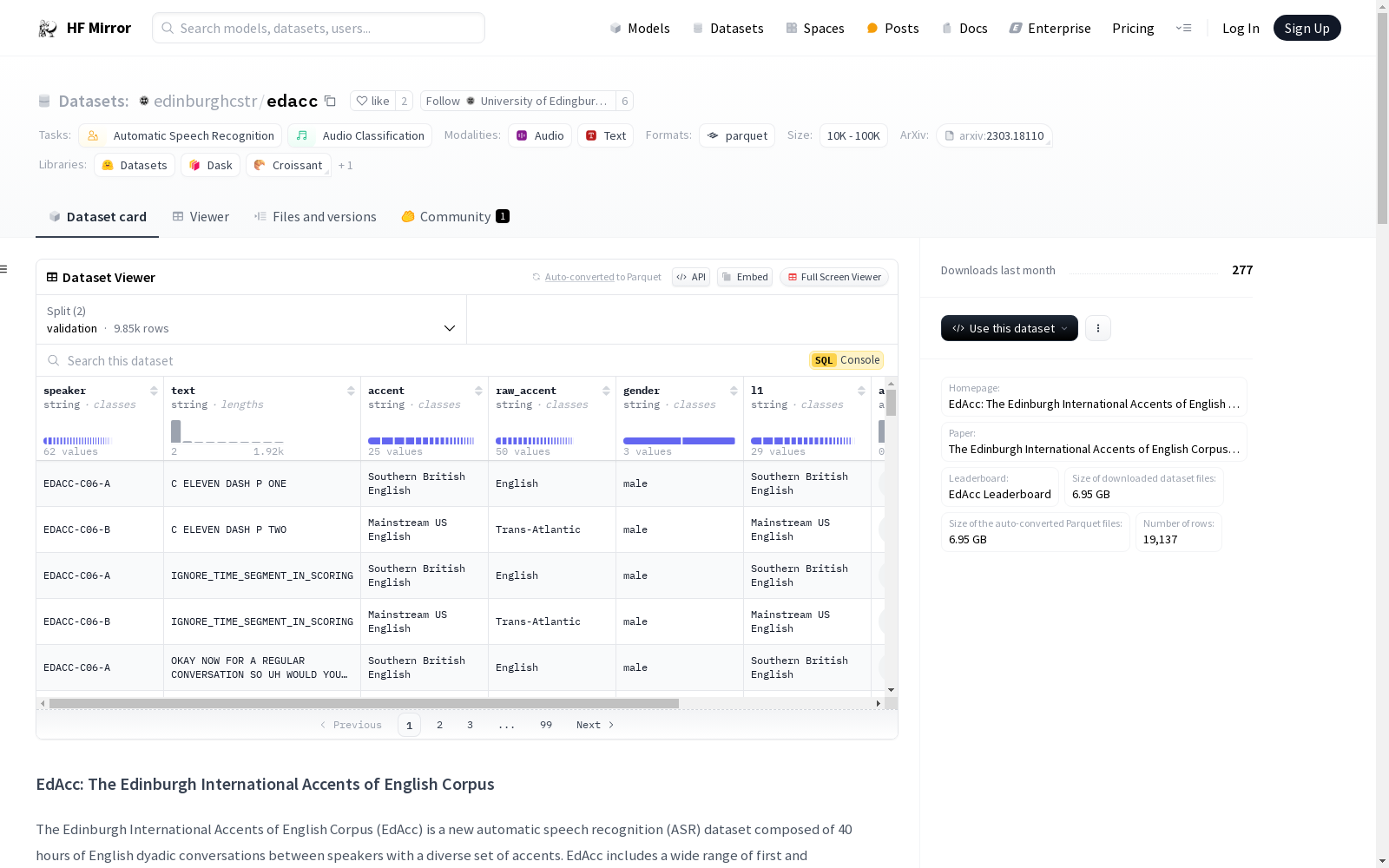
edinburghcstr/edacc
收藏Hugging Face2024-02-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/edinburghcstr/edacc
下载链接
链接失效反馈官方服务:
资源简介:
爱丁堡国际英语口音语料库(EdAcc)是一个新的自动语音识别(ASR)数据集,包含40小时的英语对话,涵盖了多种英语口音。数据集包括广泛的第一和第二语言英语变体,以及每个说话者的语言背景资料。最新的公共和商业模型结果显示,EdAcc突显了当前英语ASR模型的不足,这些模型在现有基准测试中表现良好,但在不同口音的说话者上表现显著下降。
爱丁堡国际英语口音语料库(EdAcc)是一个新的自动语音识别(ASR)数据集,包含40小时的英语对话,涵盖了多种英语口音。数据集包括广泛的第一和第二语言英语变体,以及每个说话者的语言背景资料。最新的公共和商业模型结果显示,EdAcc突显了当前英语ASR模型的不足,这些模型在现有基准测试中表现良好,但在不同口音的说话者上表现显著下降。
提供机构:
edinburghcstr
原始信息汇总
数据集概述
数据集描述
基本信息
- 数据集名称: EdAcc: The Edinburgh International Accents of English Corpus
- 数据集大小: 7542124660.365999 字节
- 下载大小: 6951164322 字节
数据集结构
- 特征字段:
speaker: 说话者ID,类型为字符串text: 音频文件的转录文本,类型为字符串accent: 说话者的口音,由训练有素的语言学家标注,类型为字符串raw_accent: 说话者自述的口音,类型为字符串gender: 说话者的性别,类型为字符串l1: 说话者的母语,由训练有素的语言学家标准化,类型为字符串audio: 包含音频文件名、解码后的音频数组和采样率的字典,类型为音频
数据分割
- 验证集:
- 样本数: 9848
- 字节数: 2615574877.928
- 测试集:
- 样本数: 9289
- 字节数: 4926549782.438
支持的任务
- 自动语音识别 (ASR): 模型接收音频文件并将其转录为书面文本,主要评估指标为词错误率 (WER)。
- 音频分类: 模型接收音频文件并预测说话者的口音或性别,主要评估指标为百分比准确率。
数据集创建
数据收集过程
- 参与者通过Zoom进行放松的对话,并填写详细的问卷以收集元数据信息。
- 问卷包括参与者的语言背景、英语学习时间、语言使用情况、居住历史、与对话伙伴的关系以及对英语口音的自我认知。
- 还包括参与者的社会人口统计信息,如年龄、性别、种族背景和教育水平。
- 对话由专业转录员转录,确保每个说话者的发言、重叠、环境声音、笑声和犹豫都被准确记录。
许可信息
- 许可: 公共领域,Creative Commons Attribution-ShareAlike International Public License (CC-BY-SA)
引用信息
@inproceedings{sanabria23edacc, title="{The Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR}", author={Sanabria, Ramon and Bogoychev, Nikolay and Markl, Nina and Carmantini, Andrea and Klejch, Ondrej and Bell, Peter}, booktitle={ICASSP 2023}, year={2023}, }
贡献者
- 感谢 @sanchit-gandhi 添加此数据集。
搜集汇总
数据集介绍
构建方式
爱丁堡国际英语口音语料库(EdAcc)的构建过程旨在捕捉自然的语音表达。参与者通过Zoom进行轻松的对话,并填写一份详尽的问卷,以收集有关其语言背景的元数据信息。该问卷涵盖了参与者的第一和第二语言、英语学习的时间、语言在不同生活领域的使用情况、居住历史、与对话伙伴的关系性质以及对自身英语口音的自我认知。此外,还收集了参与者的社会人口统计信息,如年龄、性别、种族背景和教育水平。对话由专业转录员进行转录,确保每个发言者的发言、任何重叠、环境声音、笑声和犹豫都被准确记录,从而丰富了数据集的真实性。
特点
EdAcc数据集的一个显著特点是其多样化的口音和语言背景。该数据集包含了40小时的英语对话,涉及多种第一和第二语言的英语变体,以及每个发言者的语言背景概况。此外,数据集提供了详细的元数据,包括发言者的性别、口音、母语(L1)以及音频文件的转录文本。这些特征使得EdAcc成为评估和改进自动语音识别(ASR)模型在处理不同口音和语言背景时的性能的理想选择。
使用方法
使用EdAcc数据集可以通过Hugging Face的`datasets`库轻松实现。只需两行代码即可加载和预处理数据集。例如,使用`load_dataset`函数可以下载并预处理EdAcc数据集,并返回验证集中的第一个样本。此外,数据集还支持流式加载,通过添加`streaming=True`参数,可以在不下载整个数据集的情况下逐个加载样本。这种流式加载方式特别适用于处理大规模音频数据集,避免了将整个数据集下载到本地的需求。
背景与挑战
背景概述
爱丁堡国际英语口音语料库(EdAcc)是由爱丁堡大学语音技术研究中心创建的一个自动语音识别(ASR)数据集,旨在解决当前英语ASR模型在处理多样化口音时的性能下降问题。该数据集包含了40小时的英语对话录音,涵盖了多种第一语言和第二语言的英语口音,并提供了详细的说话者语言背景信息。EdAcc的创建时间可追溯至2023年,主要研究人员包括Ramon Sanabria、Nikolay Bogoychev等人。该数据集的核心研究问题是如何提升ASR模型对不同口音的识别能力,其影响力在于揭示了现有模型在多样化口音处理上的不足,推动了英语ASR技术的民主化进程。
当前挑战
EdAcc数据集面临的挑战主要集中在两个方面:一是如何有效解决自动语音识别模型在处理多样化口音时的性能下降问题,这要求模型能够适应并准确识别各种复杂的口音变体;二是数据集构建过程中遇到的挑战,包括如何确保录音的自然性和真实性,以及如何通过专业转录确保数据的准确性和丰富性。此外,数据集的多样性和复杂性也带来了技术上的挑战,如音频文件的解码和重采样,以及如何在保证数据质量的同时提高处理效率。
常用场景
经典使用场景
爱丁堡国际英语口音语料库(EdAcc)主要用于自动语音识别(ASR)和音频分类任务。在ASR任务中,模型接收音频文件并将其转录为书面文本,评估指标通常为词错误率(WER)。在音频分类任务中,模型需预测说话者的口音或性别,评估指标为准确率百分比。这些任务旨在评估和提升模型在处理不同英语口音时的性能,特别是在多样化的口音和语言背景下的表现。
衍生相关工作
基于EdAcc数据集,研究者们已经开展了一系列相关工作,包括改进现有ASR模型的算法和架构,以提高其在多样化口音环境下的性能。此外,还有研究探讨了如何利用该数据集进行口音识别和分类,以及如何结合其他语言特征来提升语音识别的准确性。这些工作不仅推动了ASR技术的发展,也为跨文化交流和语言多样性研究提供了新的视角和方法。
数据集最近研究
最新研究方向
近年来,爱丁堡国际英语口音语料库(EdAcc)在自动语音识别(ASR)领域引起了广泛关注。该数据集通过包含多样化的英语口音,揭示了现有ASR模型在处理非标准口音时的性能下降问题。研究者们正致力于开发能够适应多种口音的ASR模型,以提高系统的鲁棒性和公平性。此外,EdAcc还推动了音频分类任务的发展,特别是在口音和性别识别方面,为多语言和多文化背景下的语音技术应用提供了新的研究视角。这些研究不仅有助于提升语音识别技术的普适性,还对全球范围内的语音技术应用具有深远的意义。
以上内容由遇见数据集搜集并总结生成


