JourneyDB
收藏arXiv2023-10-28 更新2024-06-21 收录
下载链接:
https://journeydb.github.io
下载链接
链接失效反馈官方服务:
资源简介:
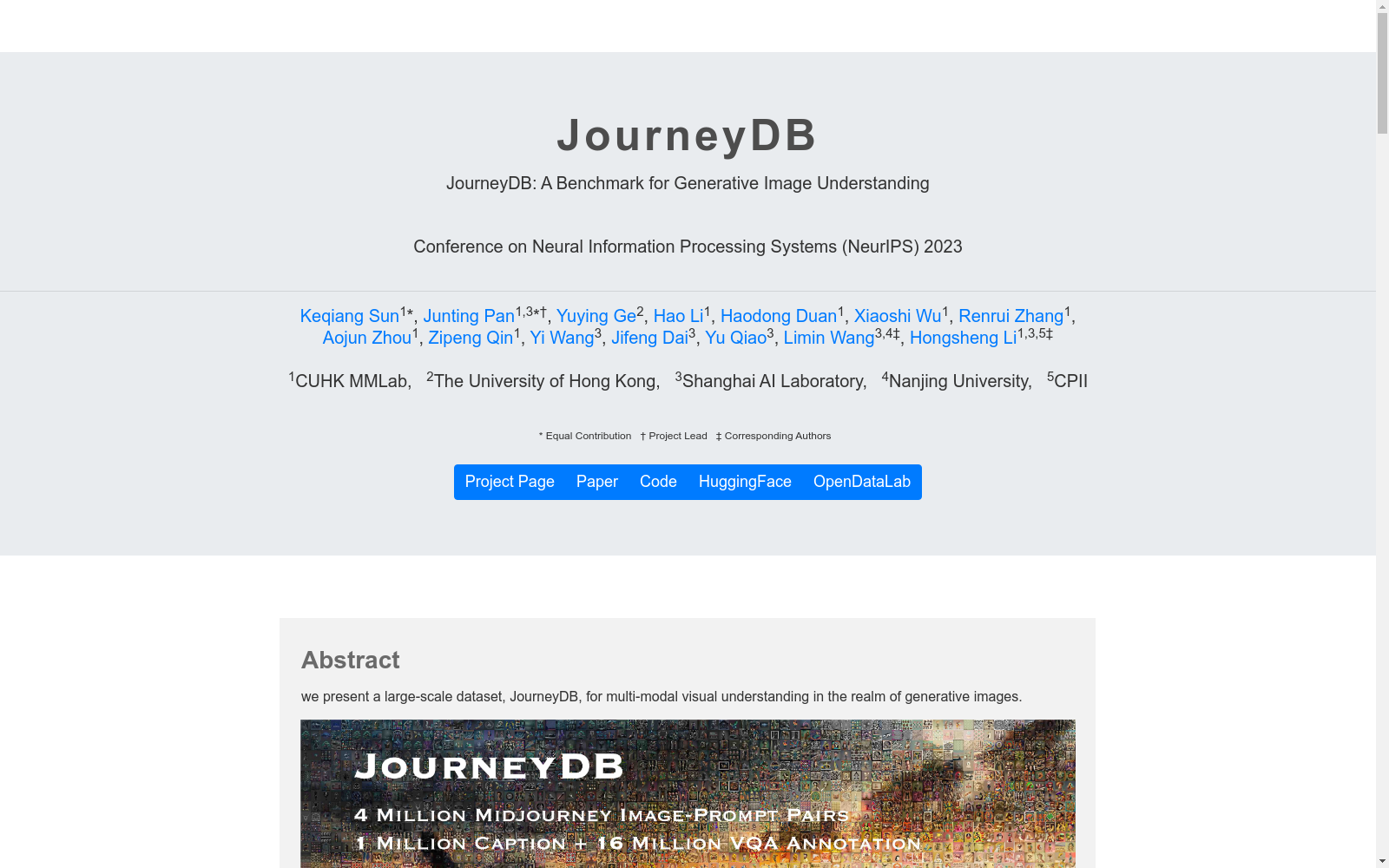
JourneyDB是由香港中文大学多媒体实验室创建的一个大规模数据集,专注于生成图像的多模态视觉理解。该数据集包含400万张高质量生成图像,每张图像都配有用于生成该图像的文本提示。此外,JourneyDB还引入了一个包含22种不同文本到图像生成模型的外部子集,使其成为评估生成图像理解能力的全面基准。数据集创建过程中,通过Discord平台收集图像,并利用GPT-3.5模型进行详细的下游任务标注,包括风格和内容的分离、图像标题生成以及视觉问答等。JourneyDB的应用领域主要集中在提升生成内容理解的研究,特别是在内容和风格的细粒度识别上,旨在解决现有模型在处理生成数据时遇到的挑战。
JourneyDB is a large-scale dataset created by the Multimedia Laboratory of The Chinese University of Hong Kong, focusing on multimodal visual understanding of generated images. This dataset contains 4 million high-quality generated images, each paired with the text prompt used to generate it. Additionally, JourneyDB includes an external subset consisting of 22 distinct text-to-image generation models, making it a comprehensive benchmark for evaluating generated image understanding capabilities. During the dataset construction process, images were collected via the Discord platform, and detailed downstream task annotations were performed using the GPT-3.5 model, including style-content separation, image caption generation, Visual Question Answering (VQA), and more. The application scenarios of JourneyDB primarily focus on research for improving generated content understanding, especially fine-grained recognition of content and style, aiming to address the challenges encountered by existing models when processing generated data.
提供机构:
多媒体实验室,香港中文大学
创建时间:
2023-07-03
搜集汇总
数据集介绍
构建方式
JourneyDB 数据集的构建过程始于 Midjourney Discord 通道中生成的图像的收集。研究者们利用 DiscordChatExporter 工具下载了这些图像及其对应的文本提示,并保留了仅由文本提示生成的图像。为了提高数据集的多样性,他们还引入了来自 22 个其他文本到图像生成模型的 45,803 张图像。此外,GPT-3.5 用于对下游任务进行标注,包括将提示分为 '风格'、'内容'、'氛围' 和 '其他' 类别,根据内容生成描述性标题,以及生成与风格和内容相关的多项选择题。为了确保测试集的质量,研究人员还进行了人工验证,以删除与图像不符的文本描述。
特点
JourneyDB 数据集具有以下特点:1)包含 4 百万个独特且高质量的生成图像,每个图像都配对了用于其创建的相应文本提示;2)引入了 22 个文本到图像生成模型的图像作为外部子集,使其成为一个全面的基准,用于评估生成图像的理解能力;3)包含四个基准任务,用于评估生成图像理解在内容和解码解释方面的性能,这些任务包括提示反转、风格检索、图像描述和视觉问答。
使用方法
使用 JourneyDB 数据集的方法包括以下步骤:1)数据收集:从 Midjourney Discord 通道中收集图像及其文本提示,并引入其他文本到图像生成模型的图像;2)数据标注:利用 GPT-3.5 对下游任务进行标注,包括提示分类、标题生成和多项选择题生成;3)数据分割:将数据集随机分割为训练集、验证集和测试集;4)基准评估:使用各种多模态模型对数据集上的四个基准任务进行评估,以了解模型在生成内容理解方面的优势和局限性。
背景与挑战
背景概述
随着人工智能生成内容(AIGC)领域的迅猛发展,尤其是扩散模型在生成内容质量上的显著提升,AIGC平台如DALLE、Stability AI、Runway和Midjourney等日益受到用户青睐。这些平台允许用户利用自然语言描述的文本提示来生成高质量的图像。与从真实图像中获取的描述不同,用于图像生成的文本提示往往包含高度详细和具体的描述,超越了仅仅描绘显著内容的范畴。这些文本提示在视觉生成中扮演着至关重要的角色,其复杂性包含了多样化的风格元素,如灯光、相机角度、艺术风格、媒介等。鉴于这些特点,我们认为,这些详细的文本提示和生成的图像本身都是宝贵的信息来源,可以纳入现有的视觉理解基准中。一方面,详细的文本提示提供了对视觉场景的更全面的解释,使我们能够感知场景并理解其底层风格。另一方面,生成图像中大量新颖的物体组合提供了不受传统感官偏见限制的领域见解,有助于探索传统视觉理解之外的领域。考虑到上述特征,我们提出了一个包含4百万精心生成的图像和相应文本提示的数据集,用于创建一个由四个不同任务组成的基准,这些任务共同促进了对生成内容的全面评估。
当前挑战
虽然基础模型在各种视觉理解任务中取得了无与伦比的能力,这得益于在数据集上的大规模预训练,如CLIP、Flamingo和BLIP-2等。然而,我们必须承认,当前的基础模型主要是在真实数据上进行预训练的,这引发了对它们泛化能力以及处理生成内容独特特征的效力的担忧。这些模型可能无法完全捕捉生成内容的细微之处,并且可能在理解和生成基于复杂文本提示的高质量图像方面遇到困难。为了应对这一挑战,我们的研究项目旨在通过创建一个包含大量精心生成的图像和相应文本提示的数据集来解决这一差距。该数据集作为由四个不同任务组成的基准的基础,共同促进了对生成内容的全面评估。这些任务包括:1)提示反转,涉及识别用户生成给定图像所使用的文本提示。这项任务旨在解码原始提示或描述,评估模型理解生成图像内容和风格的能力。2)风格检索,其中模型被要求根据其风格属性识别和检索类似的生成图像。这项任务评估模型在辨别生成图像中细微风格差异方面的能力。3)图像描述,要求模型生成能够准确代表生成图像内容的描述性描述。这项任务评估模型有效理解和用自然语言表达生成内容视觉元素的能力。4)视觉问答(VQA),其中模型被期望对与生成图像相关的问题提供准确答案。这项任务评估模型理解视觉和风格内容并根据提供的提示提供相关答案的能力。
常用场景
经典使用场景
JourneyDB数据集在生成图像的理解领域具有广泛的应用场景。该数据集包含4百万个独特且高质量的生成图像,以及用于创建这些图像的相应文本提示。这使得JourneyDB成为评估生成图像理解能力的综合基准。通过该数据集,研究人员可以评估模型在内容解释和风格理解方面的性能。此外,JourneyDB还包括来自22个其他文本到图像生成模型的图像,这为跨数据集评估提供了可能性。
衍生相关工作
JourneyDB数据集的提出为生成内容理解领域的研究开辟了新的方向。该数据集的创建和使用促进了多项相关工作的开展,包括但不限于图像生成模型的改进、图像描述模型的优化、风格检索技术的提升以及视觉问答模型的开发。这些相关工作的开展将进一步推动生成内容理解领域的发展,并为构建更加智能和高效的视觉理解系统提供支持。
数据集最近研究
最新研究方向
随着人工智能生成内容(AIGC)的快速发展,特别是扩散模型在提升生成内容质量方面的显著进步,生成式图像理解已成为视觉-语言模型领域的前沿研究方向。JourneyDB数据集的提出,旨在填补当前基础模型在处理生成内容时的性能缺口,为评估和提升模型对生成式内容的理解能力提供了宝贵的资源。该数据集包含4百万个独特的高质量生成图像及其对应的文本提示,并引入了22个文本到图像生成模型的结果作为外部子集,使其成为评估生成图像理解的全面基准。JourneyDB数据集不仅涵盖了图像内容,还引入了风格相关的描述,为模型提供了更加全面的训练和评估环境。在图像理解领域,JourneyDB的提出无疑将推动生成内容理解的研究,并为视觉-语言模型的进一步发展提供新的视角。
相关研究论文
- 1JourneyDB: A Benchmark for Generative Image Understanding多媒体实验室,香港中文大学 · 2023年
以上内容由遇见数据集搜集并总结生成


