dinercall-ner
收藏Hugging Face2025-08-31 更新2025-09-01 收录
下载链接:
https://huggingface.co/datasets/Luigi/dinercall-ner
下载链接
链接失效反馈官方服务:
资源简介:
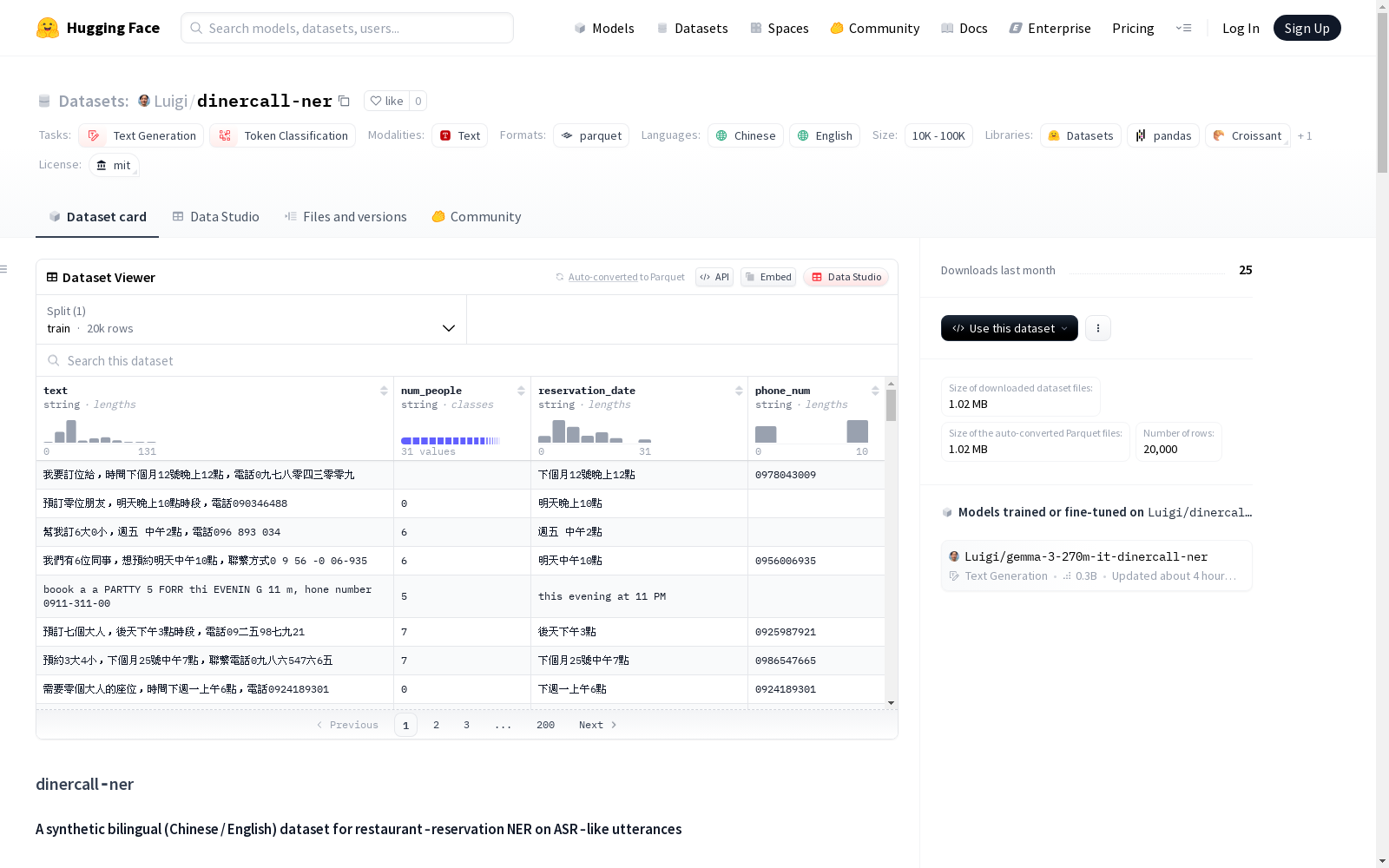
dinercall-ner是一个合成的双语(中文/英文)餐厅预订命名实体识别数据集,包含20000个模拟自动语音识别系统口语输入的预订请求。数据集适用于训练能够处理带噪声的口语输入的NER或槽填充模型。
创建时间:
2025-08-31
原始信息汇总
dinercall-ner 数据集概述
数据集基本信息
- 名称:dinercall-ner
- 类型:合成双语(中文/英文)餐厅预订命名实体识别数据集
- 许可证:Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC-BY-NC-SA 4.0)
- 任务类别:文本生成、令牌分类
- 语言:中文(繁体)、英文
- 数据规模:10K-100K样本
数据内容
- 样本数量:20,000个自动生成的预订请求
- 语言分布:70%中文(繁体),30%英文
- 文件格式:dataset.parquet(列式存储,适用于datasets或pandas)
数据字段说明
| 字段名 | 描述 |
|---|---|
text |
ASR风格的话语(可能包含同音替换、字符删除/重复、空格错误、大小写/标点噪声等) |
num_people |
标准化用餐人数(阿拉伯数字,如"4"),未提及则为空字符串 |
reservation_date |
标准化日期/时间字符串(如"明天晚上7點"或"tomorrow at 7 PM"),省略则为空 |
phone_num |
标准化台湾手机号(规范格式09XXXXXXXX),未提供或无效则为空 |
数据生成流程
- 使用Faker生成真实姓名、电话号码和日期
- 实体值生成:人数变化表达、预订日期多种模式、电话号码格式
- 规范化处理:混合中文/阿拉伯数字转换、去除标点、规范电话格式
- 模板渲染:使用8个中文和8个英文句子模板填充槽值
- ASR错误注入:80%的话语包含模拟错误(同音替换、字符省略/重复、额外空格、大小写错误等)
- 数据集扁平化:嵌套输出字典扩展为平面列并保存为Parquet文件
数据统计
| 统计指标 | 值 |
|---|---|
| 总样本数 | 20,000 |
| 中文话语 | ~14,000 |
| 英文话语 | ~6,000 |
| 包含电话号码的话语 | ~80% |
| 包含日期的话语 | ~90% |
| 包含人数计数的话语 | ~90% |
| 平均令牌长度 | 12-20个令牌(取决于语言) |
预期用途
- 双语语音助手的槽填充/命名实体识别模型
- 需要处理典型转录错误的鲁棒ASR到NLU管道
- 噪声口语数据的少样本提示或指令调整
- 现实错误条件下的多语言实体提取基准测试
引用方式
bibtex @dataset{dinercall-ner, author = {Luigi}, title = {dinercall-ner: Synthetic bilingual restaurant reservation dataset with ASR noise}, year = {2025}, publisher = {HuggingFace}, version = {v1.0}, url = {https://huggingface.co/datasets/Luigi/dinercall-ner} }
搜集汇总
数据集介绍
构建方式
在语音识别与自然语言处理交叉领域,dinercall-ner数据集通过自动化流程构建。采用Faker库生成真实姓名、电话号码及多语言日期数据,结合中英文模板库进行语义填充,并创新性地注入同音替换、字符缺失重复、空格异常等ASR典型错误特征,最终经规范化处理输出为Parquet列式存储格式,完美模拟现实场景下的语音转文本噪声环境。
特点
该数据集涵盖中英双语语音文本,其中中文占比70%,英文占30%,包含2万条餐厅预订语句。每条数据均包含原始噪声语句及标准化实体标注,突出表现为语音识别场景下的错误多样性,如数字表达变异、日期格式混合及电话号码的国际化表示。其多模态噪声结构和实体标注体系为跨语言语义理解研究提供了高价值样本。
使用方法
研究者可通过HuggingFace datasets库直接加载数据集,或使用pandas读取Parquet文件进行访问。该数据适用于命名实体识别、槽位填充等任务,尤其擅长评估模型在噪声环境下的跨语言表现。支持少样本学习与指令微调场景,为构建鲁棒性语音助手系统提供基准测试框架。
背景与挑战
背景概述
在语音助手与自然语言处理技术蓬勃发展的背景下,dinercall-ner数据集由研究者Luigi于2025年创建并发布。该数据集专注于餐厅预订场景下的命名实体识别任务,旨在解决多语言环境下自动语音识别系统输出文本的语义解析问题。其核心研究价值在于通过合成方法生成包含典型ASR错误模式的双语语料,为构建鲁棒的对话系统提供重要数据支撑,对跨语言语音交互系统的研究与开发具有显著推动作用。
当前挑战
数据集构建面临多维度挑战:在领域问题层面,需准确识别含噪声文本中的实体信息,包括处理同音替换、字符缺失重复等ASR典型错误;在构建过程中,需平衡中英文语言特性差异,设计合理的错误注入机制,并确保实体值规范化的一致性。同时,生成语料需保持语言表达的多样性与真实性,避免模板化痕迹过重,这对数据生成管道的设计提出了较高要求。
常用场景
经典使用场景
在语音助手和对话系统领域,dinercall-ner数据集为餐厅预订场景下的命名实体识别任务提供了标准测试平台。该数据集通过模拟自动语音识别系统输出的噪声文本,包含中英双语混合的订位语句,研究者可借此评估模型在真实语音转文本环境中的实体抽取能力,特别是对人数、预约时间和电话号码等关键信息的识别精度。
解决学术问题
该数据集有效解决了多语言环境下噪声文本的实体识别难题,为研究社区提供了可控的噪声注入机制和标注规范。通过模拟同音替换、字符缺失和格式错误等常见ASR问题,它助力学者开发更具鲁棒性的自然语言理解模型,推动语音交互系统在噪声环境下的语义解析准确度提升。
衍生相关工作
该数据集催生了多项关于噪声鲁棒性实体抽取的创新研究,包括基于跨语言迁移学习的联合建模方法和端到端的语音语义理解框架。部分工作进一步扩展了数据集的噪声类型和语言覆盖范围,推动了语音自然语言处理技术在真实场景中的落地应用与性能边界拓展。
以上内容由遇见数据集搜集并总结生成


