ICML2022/ProteinGym
收藏Hugging Face2022-07-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ICML2022/ProteinGym
下载链接
链接失效反馈官方服务:
资源简介:
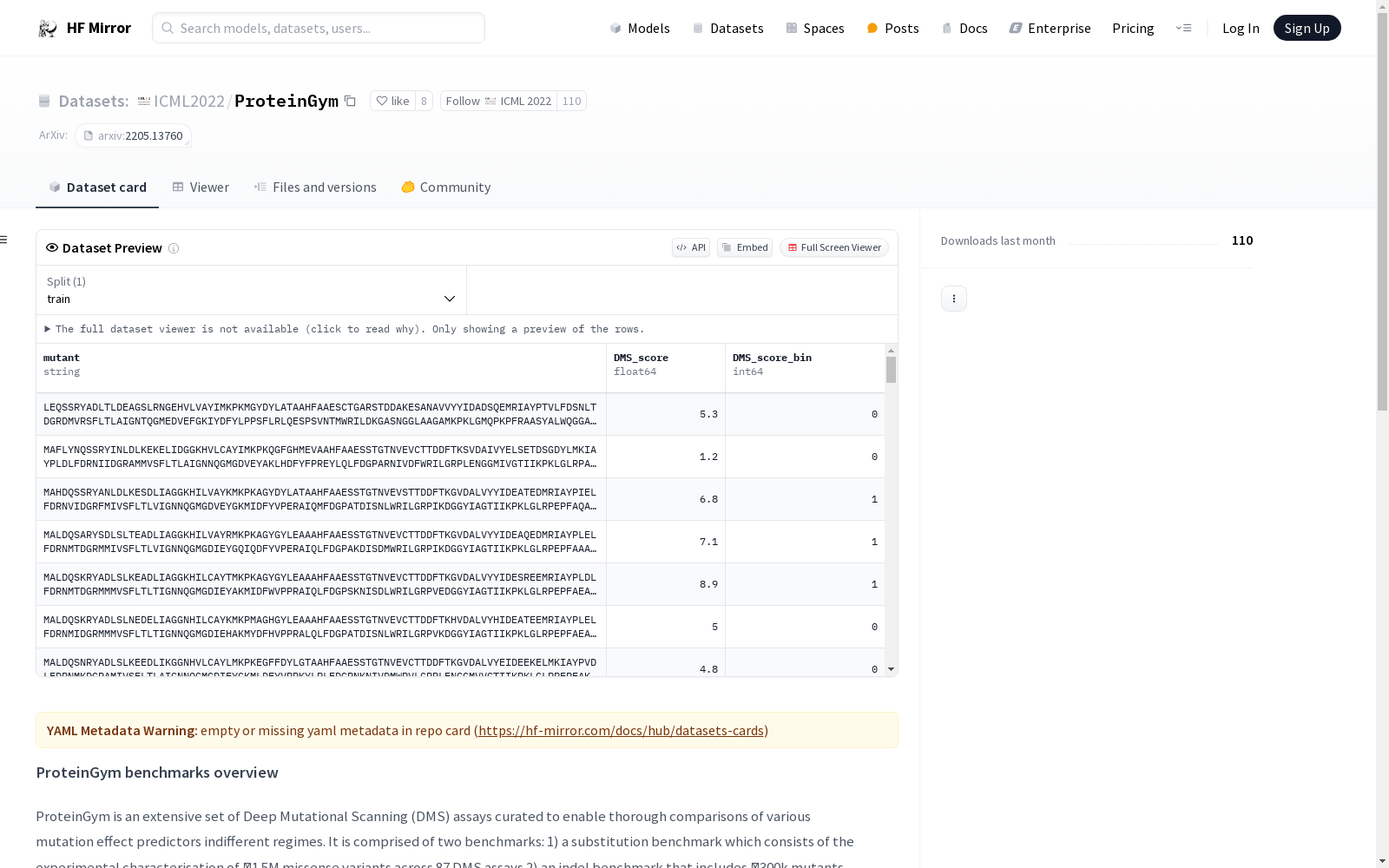
ProteinGym是一个广泛的深度突变扫描(DMS)实验集合,用于比较不同机制下的突变效应预测器。它包含两个基准测试:1)替换基准测试,包含87个DMS实验中的约150万个错义变体的实验表征;2)插入/删除基准测试,包含7个DMS实验中的约30万个突变体。每个基准测试中的处理文件对应一个DMS实验,并包含三个变量:突变体、DMS_score和DMS_score_bin。此外,还提供了两个参考文件,进一步详细说明了每个实验的相关信息。
ProteinGym is a comprehensive collection of deep mutational scanning (DMS) experiments intended for comparing mutation effect predictors across different mechanistic contexts. It includes two benchmark datasets: 1) the substitution benchmark, which covers experimental characterization of approximately 1.5 million missense variants across 87 DMS experiments; 2) the indel benchmark, which contains roughly 300,000 mutants from 7 DMS experiments. For each benchmark, the processing files correspond to one individual DMS experiment and encompass three variables: mutant, DMS_score, and DMS_score_bin. Furthermore, two reference files are provided to further elaborate on the relevant information associated with each experiment.
提供机构:
ICML2022
原始信息汇总
ProteinGym 数据集概述
数据集组成
ProteinGym 包含两个基准:
- 替换基准:包含约1.5M错义变异体的实验特征,涵盖87个DMS测定。
- 插入缺失基准:包含约300k变异体,涵盖7个DMS测定。
数据集文件内容
每个处理过的文件对应一个DMS测定,包含以下三个变量:
- mutant (字符串):
- 替换基准:描述应用于参考序列的替换集合以获得变异序列。
- 插入缺失基准:对应完整的变异序列。
- DMS_score (浮点数): 表示DMS测定中的实验测量值,所有测定中DMS_score值越高,变异蛋白的适应性越高。
- DMS_score_bin (整数): 指示DMS_score是否高于适应性阈值(1表示适应,0表示不适应)。
参考文件
提供两个参考文件:
ProteinGym_reference_file_substitutions.csvProteinGym_reference_file_indels.csv
这些文件包含每个测定的详细信息,包括:
- UniProt_ID、分类和MSA深度类别
- 测定中使用的目标序列(target_seq)
- DMS_score从原始文件创建及二值化的详细信息
搜集汇总
数据集介绍
构建方式
ProteinGym数据集通过精心策划的深度突变扫描(DMS)实验构建,旨在为不同突变效应预测器提供全面的比较基准。该数据集包含两个主要基准:一是替代基准,涵盖了87个DMS实验中约150万个错义突变体;二是插入缺失基准,包含7个DMS实验中约30万个突变体。每个处理文件对应一个DMS实验,包含突变体描述、DMS得分及其二值化结果。此外,还提供了参考文件,详细记录了每个实验的蛋白质UniProt ID、分类信息、目标序列以及DMS得分的生成和二值化方法。
特点
ProteinGym数据集的显著特点在于其大规模和多样性,涵盖了广泛的蛋白质突变实验,为突变效应预测提供了丰富的数据支持。数据集中的每个突变体都经过实验验证,具有明确的DMS得分,能够准确反映突变对蛋白质适应性的影响。此外,数据集的结构化设计使得不同实验之间的比较和分析变得简便,为研究者提供了强大的工具来评估和改进突变效应预测模型。
使用方法
ProteinGym数据集适用于开发和验证蛋白质突变效应预测模型。研究者可以通过加载数据集中的处理文件,获取突变体信息、DMS得分及其二值化结果,进行模型训练和测试。参考文件提供了实验的详细背景信息,有助于理解数据集的构建过程和实验条件。通过结合这些数据,研究者可以构建和优化突变效应预测模型,进而应用于蛋白质工程和药物设计等领域。
背景与挑战
背景概述
ProteinGym数据集由Notin等人于2022年创建,旨在通过大规模的深度突变扫描(DMS)实验,提供一个全面的突变效应预测基准。该数据集包含两个主要部分:替换基准和插入缺失基准,分别涵盖了约150万个错义突变和30万个插入缺失突变。这些数据来自87个和7个DMS实验,每个实验都详细记录了突变序列及其对应的DMS评分,用于评估蛋白质的适应性。ProteinGym的发布为蛋白质工程和生物信息学领域提供了一个重要的资源,推动了对蛋白质突变效应预测模型的深入研究。
当前挑战
ProteinGym数据集在构建过程中面临多项挑战。首先,处理和整合来自多个DMS实验的庞大数据量,确保数据的准确性和一致性是一个复杂的过程。其次,如何有效地将实验测量的DMS评分转化为可用于模型训练的二元适应性评分,也是一个技术难题。此外,由于蛋白质突变效应的复杂性和多样性,开发能够准确预测这些效应的模型仍然是一个开放的研究问题。这些挑战不仅涉及数据处理和模型开发,还包括如何确保模型的泛化能力和在不同实验条件下的稳定性。
常用场景
经典使用场景
ProteinGym数据集在蛋白质突变效应预测领域具有经典应用场景。该数据集通过提供大规模的深度突变扫描(DMS)实验数据,支持研究人员对蛋白质突变的影响进行精确预测。其替换基准(substitution benchmark)和插入缺失基准(indel benchmark)分别涵盖了约150万错义突变和30万插入缺失突变,为开发和验证突变效应预测模型提供了丰富的实验数据。
实际应用
在实际应用中,ProteinGym数据集为蛋白质工程和药物设计提供了重要支持。通过预测突变对蛋白质功能的影响,研究人员可以优化蛋白质的稳定性和活性,从而加速新药的开发过程。此外,该数据集还可用于评估基因编辑技术的安全性,帮助识别潜在的有害突变,为精准医疗和个性化治疗提供数据基础。
衍生相关工作
ProteinGym数据集的发布催生了一系列相关研究工作。例如,基于该数据集的突变效应预测模型如Tranception,利用自回归变换器和推理时检索技术,显著提升了预测精度。此外,该数据集还激发了对蛋白质突变网络和进化动力学的深入研究,推动了蛋白质设计和功能预测领域的技术进步。
以上内容由遇见数据集搜集并总结生成


