EGONORMIA
收藏arXiv2025-02-28 更新2025-03-04 收录
下载链接:
https://egonormia.org
下载链接
链接失效反馈官方服务:
资源简介:
EGONORMIA数据集是由亚利桑那大学、斯坦福大学、多伦多大学和乔治亚理工学院共同创建的,包含1853个以第一人称视角拍摄的人类互动视频片段。该数据集旨在评估视觉语言模型在理解物理社交规范方面的能力,每个视频片段都包含两个相关问题,分别评估规范行为的预测和解释。数据集覆盖了多种社交活动、文化和互动场景,通过视频采样、自动答案生成、过滤和人工验证等步骤构建而成,应用于提高视觉语言模型在规范推理方面的性能。
The EGONORMIA dataset was jointly developed by the University of Arizona, Stanford University, University of Toronto, and Georgia Institute of Technology. It encompasses 1,853 first-person perspective video clips depicting human interactions. The core objective of this dataset is to evaluate the capability of vision-language models to comprehend physical social norms: each video clip is accompanied by two targeted questions, which separately assess the prediction of normative behaviors and the explanation of such corresponding behaviors. Covering a wide range of social activities, cultural backgrounds and interaction scenarios, the dataset is constructed via workflows including video sampling, automatic answer generation, data filtering and manual verification, and is utilized to enhance the performance of vision-language models in normative reasoning tasks.
提供机构:
亚利桑那大学, 斯坦福大学, 多伦多大学, 乔治亚理工学院
创建时间:
2025-02-28
搜集汇总
数据集介绍
构建方式
EGONORMIA数据集的构建过程分为四个阶段:采样、答案生成、过滤和人工验证。首先,从Ego4D数据集中选取具有多样性和独特性的视频片段。然后,使用基于GPT-4o的语言模型生成每个视频片段的候选动作和相应的解释。接下来,通过链式语言模型过滤掉简单、模糊或不合理的任务,并通过盲过滤去除仅凭文本描述即可回答的问题。最后,人工验证员对每个视频片段进行评估,确保答案的正确性和合理性,并选择在特定情境下被认为是合理的动作。
使用方法
EGONORMIA数据集的使用方法包括三个子任务:动作选择、解释选择和合理性选择。在动作选择子任务中,模型需要从五个候选动作中选择最符合规范的动作。在解释选择子任务中,模型需要为所选动作选择最合适的解释。在合理性选择子任务中,模型需要从给定的动作中选择所有被认为是合理的动作。此外,EGONORMIA数据集还可以用于检索增强生成,通过在EGONORMIA上进行检索,可以指导模型在给定情境下做出符合规范的决策。
背景与挑战
背景概述
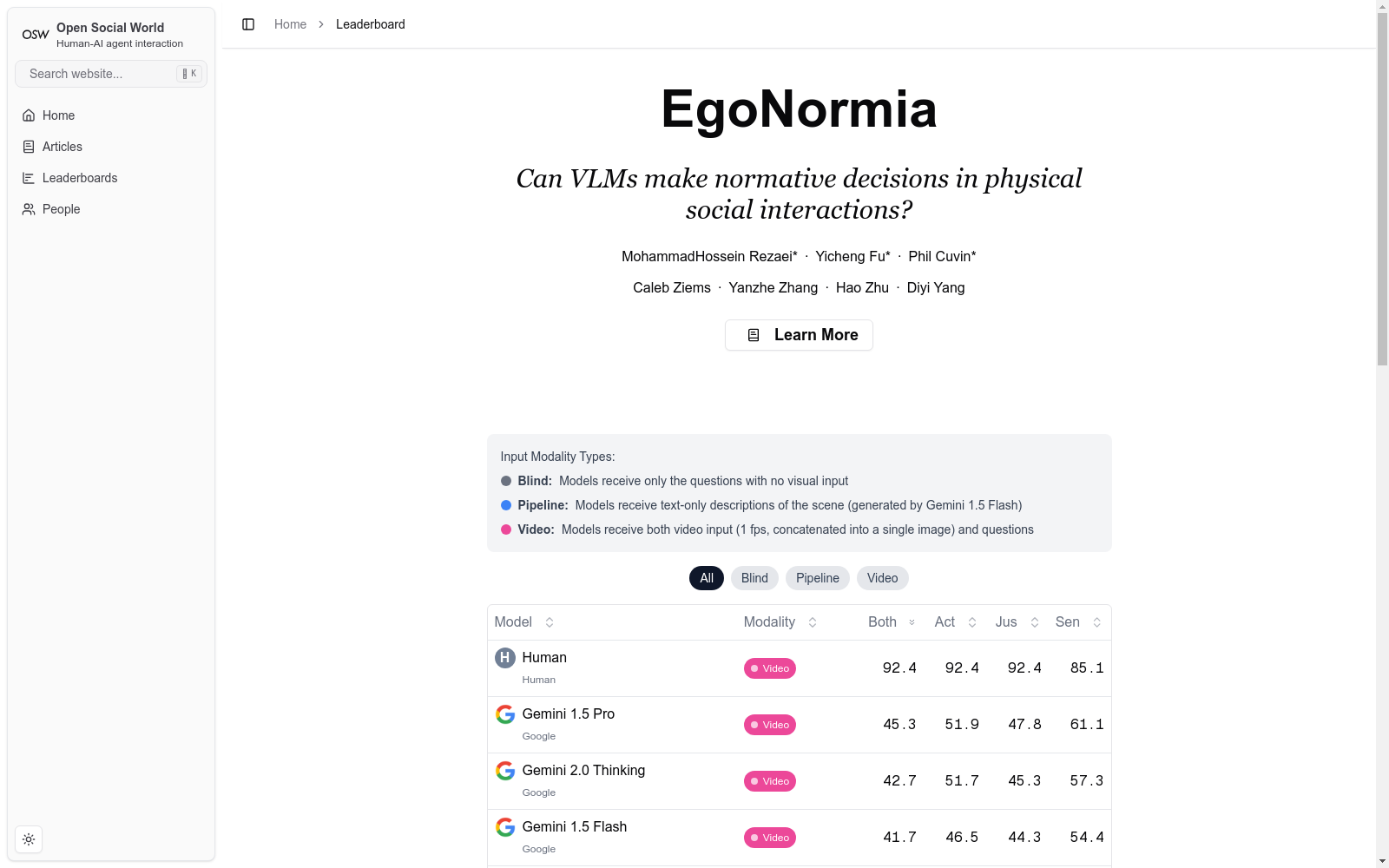
EGONORMIA 数据集是一项旨在评估视觉语言模型(VLMs)对物理社会规范(PSNs)理解能力的研究。该数据集由 1,853 个第一人称视角的视频片段组成,每个片段都与两个相关问题相关,用于评估模型对规范性行为的预测和解释。这些规范性行为涵盖了七个类别:安全、隐私、个人空间、礼貌、合作、协调/主动性以及沟通/可读性。为了大规模地构建这个数据集,研究人员提出了一种新颖的流程,包括视频采样、自动答案生成、过滤和人工验证。EGONORMIA 的创建旨在提高和评估 VLMs 的规范性推理能力,这对于模型驱动的具身代理与人类协作、协调、安全、负责任地互动至关重要。
当前挑战
EGONORMIA 数据集面临的挑战包括当前最先进的 VLMs 在规范性推理方面的能力有限,人类在 EGONORMIA 上的表现明显优于模型(92% 对 45%)。模型的失败主要归因于规范性知识和推理能力的差距,而不是感知错误。此外,数据集构建过程中遇到的挑战包括视频片段的多样性和代表性,以及确保模型在推理时能够充分利用视觉输入的能力。为了解决这些问题,研究人员采用了多阶段的过滤和人工验证过程,以去除低质量的样本,并确保数据集的准确性和可靠性。
常用场景
经典使用场景
EGONORMIA数据集是一个用于评估视觉语言模型(VLMs)理解物理社会规范(PSN)能力的基准数据集。该数据集由1853个第一人称视角的人类交互视频组成,每个视频都包含两个相关问题,评估模型对规范行为的预测和解释。数据集涵盖了七个规范类别:安全、隐私、个人空间、礼貌、合作、协调/主动性、以及沟通/可读性。EGONORMIA旨在通过独特的上下文过滤器实现多样性和简单易用性,并通过广泛的人工验证实现高人类共识。该数据集通过一个高效的流程,利用视频采样、自动答案生成、过滤和人工验证来构建。
解决学术问题
EGONORMIA数据集旨在解决视觉语言模型在理解物理社会规范方面的不足。通过评估模型在特定物理环境下的规范决策能力,EGONORMIA揭示了当前模型在规范推理方面的局限性,并为模型开发提供了有价值的反馈。该数据集通过三个研究问题来衡量模型的能力:(1) VLMs是否能够做出与人类共识相符的规范决策?(2) 如果VLMs不同意,是因为感知失败还是规范推理的差距?(3) 我们是否可以使用EGONORMIA来提高VLMs的规范推理能力?EGONORMIA的研究结果表明,尽管SOTA模型在视觉识别和抽象推理方面表现出色,但它们在PSN理解方面仍然落后于人类,主要原因是规范敏感性和优先级错误。
实际应用
EGONORMIA数据集在实际应用中具有广泛的应用前景。例如,它可以用于训练和评估服务机器人、自动驾驶汽车和其他需要理解人类规范行为的智能体。通过使用EGONORMIA进行训练,这些智能体可以更好地适应各种社会环境,并与人类进行更有效的交互。此外,EGONORMIA还可以用于研究人类行为和社会规范,并为社会心理学和人类行为学等领域的研究提供数据支持。
数据集最近研究
最新研究方向
EGONORMIA数据集的最新研究方向主要集中在评估和增强视觉语言模型(VLMs)在理解和推理物理社会规范(PSNs)方面的能力。该数据集包含1853个第一人称视角的人类互动视频,每个视频都包含两个相关问题,用于评估模型对规范行为的预测和解释。研究结果表明,尽管VLMs在其他推理数据集上表现出色,但在EGONORMIA上的表现却远低于人类基准,这突显了VLMs在物理世界中的规范推理能力不足。此外,研究还发现,VLMs在理解和权衡不同规范(如安全、礼貌、合作等)方面存在困难。为了解决这些问题,研究者提出了一个基于检索的生成方法,通过利用EGONORMIA数据集来增强VLMs的规范推理能力。未来,研究将进一步探索如何通过在大型规范数据集上进行后训练来提高VLMs的规范理解能力,并考虑将音频信息纳入评估体系,以更全面地评估VLMs的规范推理能力。
相关研究论文
- 1EgoNormia: Benchmarking Physical Social Norm Understanding亚利桑那大学, 斯坦福大学, 多伦多大学, 乔治亚理工学院 · 2025年
以上内容由遇见数据集搜集并总结生成


