USC Long Single-Speaker (LSS)数据集
收藏arXiv2025-09-18 更新2025-11-21 收录
下载链接:
https://sail.usc.edu/span/single_spk/
下载链接
链接失效反馈官方服务:
资源简介:
USC LSS数据集包含了一个美式英语母语者的实时MRI视频和同步音频,时间约为1小时,是公开可用的最长单说话人实时MRI语音数据集之一。该数据集不仅包括原始的音频和视频数据,还提供了多种衍生表示,如剪裁后的声带区域视频、句级分割数据、恢复和降噪音频以及感兴趣区域时间序列等。数据集已被用于语音合成和音素识别等语音处理任务,并为这些任务提供了基准性能。
The USC LSS Dataset contains real-time MRI videos and synchronized audio from a native American English speaker, with a duration of approximately 1 hour. It is one of the longest publicly available single-speaker real-time MRI speech datasets. In addition to raw audio and video data, this dataset also provides multiple derivative representations, including cropped vocal tract region videos, sentence-level segmentation data, restored and denoised audio, region-of-interest time series, and more. This dataset has been applied to speech processing tasks such as speech synthesis and phoneme recognition, and provides benchmark performance for these tasks.
提供机构:
南加州大学信号分析与解释实验室、南加州大学语言学系
创建时间:
2025-09-18
搜集汇总
数据集介绍
构建方式
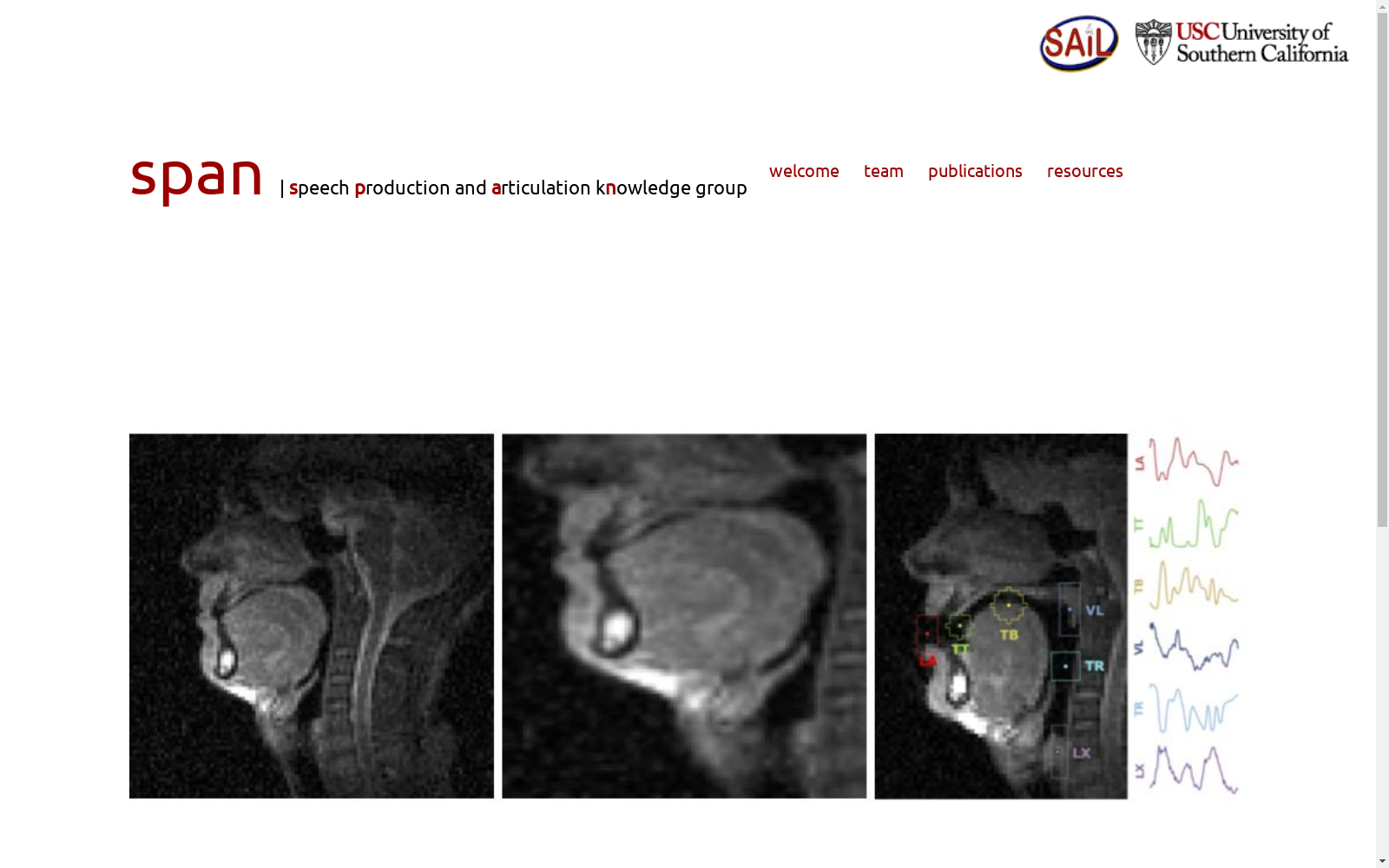
在语音产生研究领域,实时磁共振成像技术因其能无创捕捉声道动态而备受关注。USC LSS数据集通过0.55T磁共振扫描仪以99帧/秒的速率采集单名美式英语母语者的声道 midsagittal 视图,同步录制16kHz音频数据。采集内容涵盖朗读语料(包括USC TIMIT语料库的460个句子及经典段落)与即兴描述任务,总时长约54分钟。原始数据经过声道区域裁剪、音频去噪与修复、句子级切分等处理流程,并辅以蒙特利尔强制对齐器生成的音素边界标注,构建出兼具原始数据与多维度衍生表征的完整资源。
特点
作为目前公开时长最长的单说话者实时磁共振语音数据集,USC LSS的独特性体现在三方面:其单说话者设计为研究个体发音变异提供了充足样本量;99帧/秒的高帧率视频完整记录了唇舌腭等发音器官的动力学特征;除原始音视频外,还提供声道区域裁剪视频、去噪/修复双版本音频、六类发音关键区域的时序信号等衍生数据。这些经过人工校验的发音生理标记(如舌体位置、喉部运动等)为探究语音产生机制提供了精准的观测维度。
使用方法
该数据集支持多模态语音处理任务的基准研究,用户可通过官方发布的句子级训练/验证/测试集划分(比例0.85/0.05/0.1)开展实验。在发音合成任务中,研究者可利用声道视频帧驱动HiFi-GAN声码器生成语音波形;音素识别任务则支持基于Conformer架构的单模态(音频或视频)与多模态融合建模。数据集配套的ROI时序数据可直接作为低维发音特征输入,而经过Miipher模型修复的音频适用于对音质要求较高的场景,但需注意其与发音运动学的对应关系可能存在细微偏差。
背景与挑战
背景概述
在语音产生研究领域,实时磁共振成像技术因其能够无创获取声道动态完整视图而备受关注。南加州大学信号分析与解释实验室联合语言学系于2025年发布的USC长单说话者数据集,通过0.55T磁共振扫描仪以99帧/秒的采样率采集了美式英语母语者约一小时的语音数据,包含朗读与自发两种语音模式。该数据集突破了以往多说话者样本的局限,专注于单说话者深度建模,为发音合成与语音反转等任务提供了迄今最丰富的单说话者声道动态观测数据。
当前挑战
该数据集致力于解决发音合成与语音识别中跨说话者泛化能力不足的核心难题。构建过程中面临三重挑战:实时磁共振数据采集需平衡高时空分辨率与设备噪声干扰,原始音频中存在扫描仪噪声污染需通过Miipher等模型进行修复;声道运动特征提取需人工标注六个关键发音区域的时间序列;多模态数据对齐要求精确匹配99帧/秒视频与16kHz音频,并采用蒙特利尔强制对齐器进行音素级标注校正。
常用场景
实际应用
在实际应用层面,该数据集为医疗康复与语音技术领域提供了重要支持。在脑机接口系统中,其发音数据可用于构建神经假体语音解码模型,帮助言语障碍患者恢复沟通能力。在发音评估领域,数据集支撑的自动化发音评估系统能够为语言学习者提供精准的发音反馈。此外,该数据集在辅助发音治疗方案制定、个性化语音合成系统开发等方面也展现出广阔的应用前景,为临床语音病理学研究提供了可靠的数据资源。
衍生相关工作
基于该数据集衍生的经典研究工作主要集中在多模态学习与表征学习方向。在发音合成方面,研究者采用HiFi-GAN神经声码器架构,实现了从发音特征到波形的直接合成,显著提升了合成语音的自然度。在音素识别任务中,Conformer架构与跨模态注意力机制的结合探索了音频与发音视频的特征融合策略。此外,自监督表征学习方法通过联合因子分析与神经矩阵分解,构建了鲁棒的发音表征模型,这些工作为后续的发音控制语音合成、多模态语音识别等研究奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


