sdcsdccdsd/CSEMOTIONS
收藏Hugging Face2025-12-16 更新2025-12-20 收录
下载链接:
https://hf-mirror.com/datasets/sdcsdccdsd/CSEMOTIONS
下载链接
链接失效反馈官方服务:
资源简介:
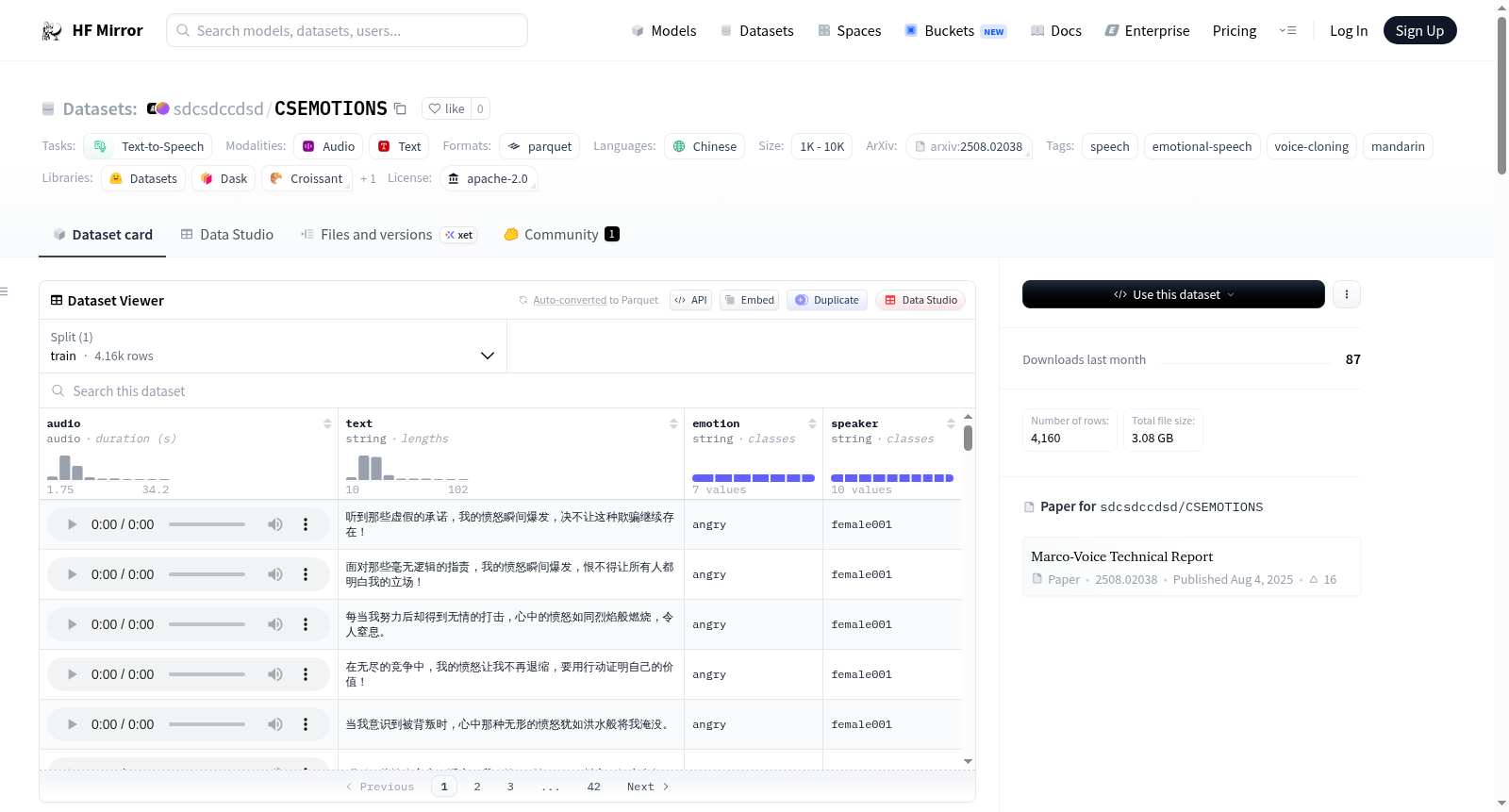
CSEMOTIONS是一个高质量的普通话情感语音数据集,专为表达性语音合成、情感识别和语音克隆研究设计。数据集包含来自6位专业配音演员的录音,涵盖了7种情感类别(中性、快乐、愤怒、悲伤、惊讶、调皮、恐惧)。录音在专业录音室环境下进行,采样率为48kHz,24位PCM格式。数据集总时长约为10小时,共4160个样本。每个样本包括音频波形、转录文本、情感标签和说话者ID。数据集支持可控和自然语言语音生成的研究,适用于文本到语音(TTS)、语音情感识别(SER)和跨语言情感合成实验。
CSEMOTIONS is a high-quality Mandarin emotional speech dataset designed for expressive speech synthesis, emotion recognition, and voice cloning research. The dataset contains studio-quality recordings from six professional voice actors across seven carefully curated emotional categories (Neutral, Happy, Angry, Sad, Surprise, Playfulness, Fearful). The recordings were made in a professional studio environment with a sampling rate of 48kHz and 24-bit PCM format. The total duration of the dataset is approximately 10 hours, comprising 4160 samples. Each sample includes the speech waveform, transcribed text, emotion label, and speaker ID. The dataset supports research in controllable and natural language speech generation and is suitable for text-to-speech (TTS), speech emotion recognition (SER), and cross-lingual emotional synthesis experiments.
提供机构:
sdcsdccdsd
搜集汇总
数据集介绍
构建方式
在情感语音合成领域,高质量数据集的构建是推动技术发展的基石。CSEMOTIONS数据集的构建过程体现了严谨的学术规范,其采集工作于专业录音棚环境中完成,由六位经过严格筛选的专业配音演员参与录制。录制内容覆盖了中性、快乐、愤怒、悲伤、惊喜、俏皮和恐惧七种精心定义的情感类别,每种情感均包含均衡的语句样本。音频数据以48kHz采样率和24位PCM格式保存,确保了信号的保真度与完整性,同时所有文本转录均经过人工校对,形成了共计4160条、总时长约10小时的标准化语音-文本-情感标注三元组。
特点
作为面向普通话的高质量情感语音数据集,CSEMOTIONS展现出多维度特征。其核心在于提供了覆盖七种离散情感的精细标注,每种情感均配有足量的高质量录音,为模型学习情感声学特征提供了丰富素材。数据集由多位专业演员演绎,保证了发音的准确性与情感表达的真实性,同时匿名化的说话人标识与性别信息为研究个体声纹差异与情感表达的交互关系提供了可能。高采样率与无损格式的音频文件,进一步保障了声学特征的完整保留,为语音合成与识别任务奠定了坚实的数据基础。
使用方法
该数据集主要服务于语音技术的前沿研究,用户可通过Hugging Face Datasets库便捷加载。典型应用场景包括训练与评估富有表现力的文本到语音合成系统,研究者可利用其情感标签训练可控的情感语音生成模型。在语音情感识别方向,该数据集可作为基准测试集,用于验证模型对多种普通话情感的分类性能。此外,其高质量、多说话人的特性也使其适用于语音克隆、跨情感语音转换以及声学特征解耦等探索性研究,为相关领域的算法创新提供了关键的数据支撑。
背景与挑战
背景概述
在语音合成与情感计算领域,高质量、多情感的中文语音数据长期稀缺,制约着相关模型的性能与泛化能力。CSEMOTIONS数据集于2025年由研究团队发布,旨在为普通话情感语音合成、语音情感识别及语音克隆提供专业级资源。该数据集收录了六位专业配音演员在七种精细定义情感类别下的录音,总时长约10小时,采样率为48kHz/24位,全部在专业录音棚环境中采集。其核心研究问题聚焦于如何实现跨情感、跨说话人的可控自然语音生成,为推进个性化、富有表现力的语音交互系统奠定了重要数据基础。
当前挑战
该数据集致力于解决情感语音合成与识别中情感标注一致性、跨说话人泛化以及高质量数据稀缺等核心挑战。在构建过程中,研究团队面临多重困难:情感类别的精细界定与标注需要语言学与心理学交叉知识,确保七种情感在语音特征上具有高区分度;专业录音棚环境虽保障了音频质量,但数据采集成本高昂,且需协调多位专业配音演员以覆盖多样化的性别与情感表达;此外,在数据合规性方面,需采用算法进行内容审查,以最大限度避免版权与不当内容风险,这增加了数据清洗与校验的复杂度。
常用场景
经典使用场景
在语音合成与情感计算领域,CSEMOTIONS数据集为可控情感语音生成提供了关键支撑。该数据集以其专业录制的多情感类别普通话语音,常被用于训练和评估端到端的文本转语音模型,特别是那些需要精确调控输出语音情感色彩的生成系统。研究者通过该数据集能够探索语音波形与离散情感标签之间的映射关系,从而推动更具表现力和自然度的合成语音技术发展。
解决学术问题
CSEMOTIONS有效应对了情感语音合成中高质量标注数据稀缺的挑战,为语音情感识别与跨情感合成研究提供了标准化基准。该数据集通过精细标注的七种情感状态,助力解决情感特征解耦、跨说话人情感迁移以及多模态情感建模等核心学术问题。其高保真录音与平衡的情感分布,显著提升了模型在复杂情感场景下的泛化能力与鲁棒性。
衍生相关工作
围绕CSEMOTIONS数据集,已衍生出一系列聚焦于情感语音合成与识别的经典研究工作。例如,基于该数据集的生成对抗网络与变分自编码器模型,实现了高质量的情感语音转换与跨语言合成;同时,结合自监督学习的预训练方法,进一步挖掘了语音信号中的细粒度情感表征。这些工作不仅推动了语音技术的前沿探索,也为多模态情感分析提供了可借鉴的范式。
以上内容由遇见数据集搜集并总结生成


