q-future/Q-Instruct-DB
收藏Hugging Face2024-01-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/q-future/Q-Instruct-DB
下载链接
链接失效反馈官方服务:
资源简介:
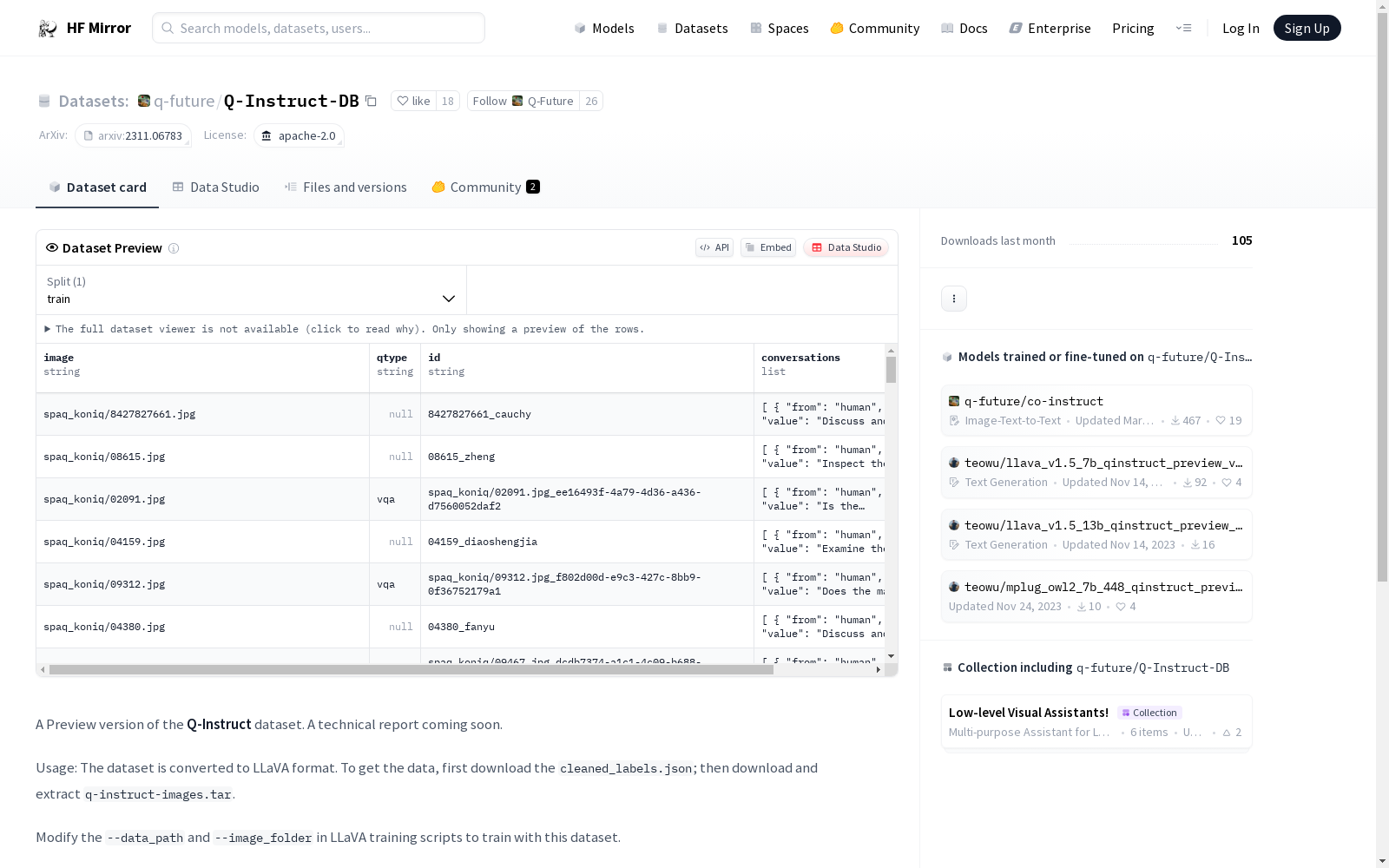
Q-Instruct数据集的预览版本,旨在提升多模态基础模型的低层次视觉能力。数据集已转换为LLaVA格式,使用前需下载`cleaned_labels.json`文件和解压`q-instruct-images.tar`文件。在LLaVA训练脚本中修改`--data_path`和`--image_folder`参数即可使用该数据集进行训练。
A preview version of the Q-Instruct dataset, intended to enhance the low-level visual capabilities of multimodal foundation models. The dataset has been converted to the LLaVA format. Prior to usage, the `cleaned_labels.json` file needs to be downloaded and the `q-instruct-images.tar` archive must be extracted. The dataset can be used for training by modifying the `--data_path` and `--image_folder` parameters in the LLaVA training script.
提供机构:
q-future
原始信息汇总
Q-Instruct 数据集预览版
使用说明
- 下载
cleaned_labels.json。 - 下载并解压
q-instruct-images.tar。 - 在LLaVA训练脚本中修改
--data_path和--image_folder以使用此数据集进行训练。
引用
请在使用数据集时引用以下论文:
@misc{wu2023qinstruct, title={Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models}, author={Haoning Wu and Zicheng Zhang and Erli Zhang and Chaofeng Chen and Liang Liao and Annan Wang and Kaixin Xu and Chunyi Li and Jingwen Hou and Guangtao Zhai and Geng Xue and Wenxiu Sun and Qiong Yan and Weisi Lin}, year={2023}, eprint={2311.06783}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
q-future/Q-Instruct-DB数据集的构建,旨在提升多模态基础模型的低层次视觉能力。该数据集通过转换至LLaVA格式,将图像与指令相结合,构建出一个适用于视觉任务的数据集。其构建过程包括下载并处理`cleaned_labels.json`标签文件,以及下载并解压图像数据`q-instruct-images.tar`。在LLaVA训练脚本中调整`--data_path`和`--image_folder`参数,即可实现对该数据集的训练。
特点
该数据集的特点在于其专注于提升基础模型在视觉处理方面的能力。其图像与指令的结合方式,为模型提供了丰富的视觉理解场景,有助于促进模型在低层次视觉任务上的表现。此外,数据集遵循Apache-2.0许可,便于研究和商业应用。引用相关论文可进一步了解数据集的学术背景和应用价值。
使用方法
使用q-future/Q-Instruct-DB数据集时,用户需首先下载标签文件`cleaned_labels.json`和图像数据压缩包`q-instruct-images.tar`。解压图像数据后,通过修改LLaVA训练脚本中的`--data_path`和`--image_folder`参数,以指定数据集的正确路径。在训练过程中,确保遵循数据使用规范,并在成果发表时引用原始论文,以尊重数据集的版权和贡献者权益。
背景与挑战
背景概述
Q-Instruct-DB数据集,作为Q-Instruct项目的重要组成部分,旨在提升多模态基础模型在低级视觉任务上的能力。该数据集由Haoning Wu等研究人员于2023年提出,并在计算机视觉领域引起广泛关注。该数据集的核心研究问题是针对多模态基础模型在处理低级视觉任务时的性能局限,其研究成果对于推动视觉基础模型的进步具有重要意义。
当前挑战
数据集在构建过程中所面临的挑战主要包括两个方面:一是领域问题上的挑战,即如何精确地提升模型在低级视觉任务上的表现;二是数据集构建过程中的挑战,涉及数据清洗、格式转换以及与现有框架的兼容性问题。在数据集的实际应用中,研究人员需调整训练脚本中的参数以适应数据集的特殊格式,这对使用者的技术要求较高。
常用场景
经典使用场景
在当前人工智能领域,多模态基础模型的研究逐渐成为热点。Q-Instruct-DB数据集便是为了提升这些模型在低级视觉任务上的能力而构建。其经典使用场景在于,通过结合文本与图像信息,对模型进行训练,以实现对图像内容的高级理解和生成。
实际应用
在实用层面,Q-Instruct-DB数据集的应用场景广泛,可服务于图像搜索、图像内容生成、智能辅助设计等多个领域。其通过增强模型对图像的深层次理解,为实际生活中的视觉任务提供了智能化解决方案。
衍生相关工作
基于Q-Instruct-DB数据集的研究,已衍生出诸如图像-文本交互模型优化、视觉任务自适应学习等多个经典工作。这些研究进一步推动了多模态人工智能技术的发展,为视觉认知与生成领域带来了新的研究视角和方法论。
以上内容由遇见数据集搜集并总结生成


