ai4privacy/pli-masking-100k
收藏Hugging Face2026-04-04 更新2025-07-05 收录
下载链接:
https://hf-mirror.com/datasets/ai4privacy/pli-masking-100k
下载链接
链接失效反馈官方服务:
资源简介:
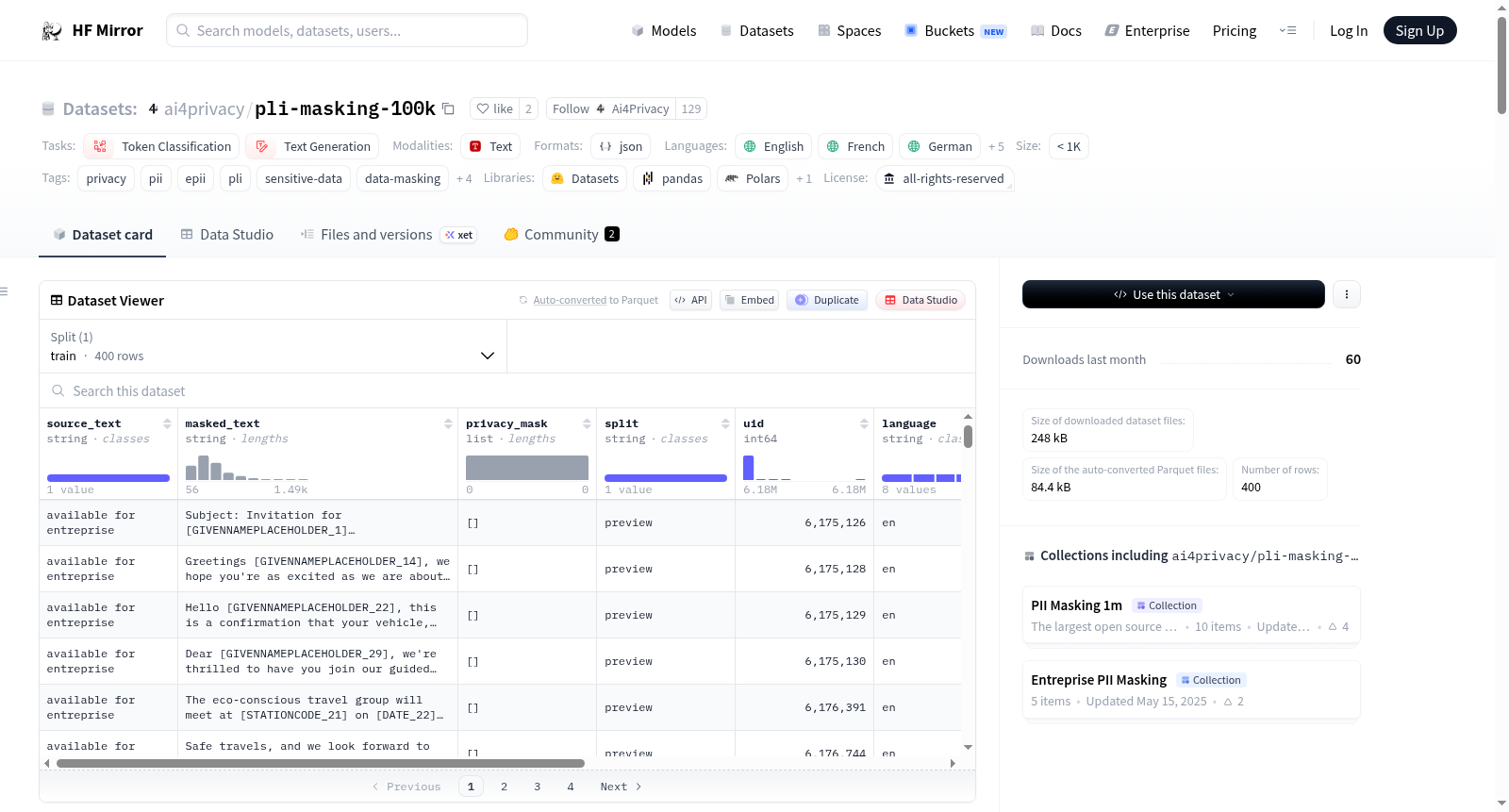
EPII个人位置信息(PLI)遮蔽数据集,专为识别和遮蔽文本数据中的敏感个人位置信息而设计,支持包括英语在内的八种语言,适用于企业级应用,满足如GDPR、CCPA、HIPAA等数据保护法规的要求。提供400条样本的预览版,以及超过10万条记录的商业完整版。
The EPII Personal Location Information (PLI) Masking Dataset is designed for identifying and masking sensitive personal location information within text data, supporting eight languages including English, tailored for enterprise applications to meet data protection regulations such as GDPR, CCPA, HIPAA, etc. It offers a preview version with 400 samples and a commercial full version with over 100,000 entries.
提供机构:
ai4privacy
搜集汇总
数据集介绍
构建方式
在数据隐私保护领域,构建高质量标注数据集是推动合规自动化技术发展的基石。EPII PLI掩码预览数据集遵循p5y隐私框架,采用系统化的三阶段流程进行构建:首先通过扫描与标记在非结构化文本中识别个人位置信息实体,生成包含实体类型、分布与风险评估的结构化隐私掩码;随后依据具体应用场景与法规要求,对识别出的敏感数据实施掩码、假名化或k-匿名化等保护措施;最终通过专家标注与自动化评估相结合的方式,量化匿名化后残留的隐私风险,确保数据转换后的质量与安全性。该流程旨在为模型训练提供标准化、可复现的隐私数据转换范例。
特点
该数据集专注于个人位置信息这一特定隐私范畴,其核心特征体现在细粒度的标注体系与多语言支持上。数据集定义了16种专属的PLI标签类型,如机场代码、地理坐标、IP地址、车辆识别码等,实现了对位置相关敏感信息的精准覆盖与分类。预览版本支持包括英语、法语、德语在内的六种语言,并初步探索了印地语与泰卢固语,展现了其服务于全球化企业合规需求的潜力。数据集以JSON Lines格式组织,每条记录均包含掩码后的文本、语言及区域编码等元数据,结构清晰且便于机器学习管道集成。
使用方法
该预览数据集主要用于评估数据结构和标签体系,为潜在用户提供技术洞察。研究人员或开发者可通过加载提供的JSONL文件,直接解析其中已掩码的文本示例,以理解数据格式与PLI实体的处理方式。鉴于预览集未包含原始文本、详细标注跨度及分词标签,其核心用途在于方案验证与原型设计,而非直接用于模型训练。对于需要投入生产环境的任务,如训练高精度PII检测与掩码模型,用户需联系数据集提供方获取完整的商用授权数据集,后者包含完整的源文本、隐私掩码细节及多语言分词标注,可支持端到端的模型开发与合规性自动化系统的构建。
背景与挑战
背景概述
随着全球数据隐私法规如GDPR、CCPA的日益严格,企业处理文本数据时对个人位置信息的识别与脱敏需求愈发迫切。在此背景下,Ai4Privacy机构于2025年发布了EPII个人位置信息掩码预览数据集,旨在为隐私保护人工智能提供专项训练资源。该数据集聚焦于个人位置信息这一敏感类别,涵盖机场代码、地理坐标、IP地址等16类实体标签,支持包括英语、法语、德语在内的多种语言,并特别纳入印地语与泰卢固语的实验性支持。其核心研究在于通过结构化标注,助力开发能够自动检测并掩码文本中位置信息的模型,从而推动企业在合规自动化、安全数据分析等领域的应用,为隐私计算领域提供了重要的数据基础设施。
当前挑战
该数据集致力于解决个人位置信息识别与掩码这一特定隐私保护任务的挑战,其核心在于精准区分并处理多样化的位置相关实体,例如地理坐标、交通工具识别码等,这些实体在文本中常以异构格式出现,且需跨多种语言与文化语境保持识别一致性。在构建过程中,挑战主要体现于多语言标注的复杂性,尤其是对印地语、泰卢固语等资源较少语言的处理尚处于实验阶段;同时,为确保数据质量与标注准确性,需在掩码过程中平衡信息保留与隐私保护,并严格遵循p5y框架进行隐私风险评估与质量控制,这要求高度的领域专业知识与精细的标注流程设计。
常用场景
经典使用场景
在隐私计算与数据合规领域,EPII PLI Masking数据集为个人位置信息识别与脱敏任务提供了标准化基准。该数据集通过涵盖机场代码、地理坐标、IP地址等16类细粒度标签,支持多语言文本中敏感实体的精准检测与掩码,常被用于训练和评估命名实体识别模型,以自动化处理包含位置信息的非结构化文本,满足企业级数据治理需求。
解决学术问题
该数据集有效应对了隐私保护研究中跨语言敏感信息统一标注的挑战,通过构建大规模、多语种的PLI标注体系,为学术社区提供了研究数据脱敏算法泛化能力的可靠资源。其意义在于推动了隐私计算领域从通用PII识别向细分场景(如位置信息)的纵深探索,并为GDPR、CCPA等合规框架下的自动化脱敏技术提供了实证基础。
衍生相关工作
围绕该数据集衍生的经典工作多集中于隐私增强的自然语言处理技术。例如,基于其标注体系开发的端到端脱敏管道已被集成于AI4Privacy的p5y框架;同时,该数据集也催生了针对低资源语言(如印地语、泰卢固语)的跨语言实体识别模型研究,为全球化企业的多语种合规解决方案提供了技术参照。
以上内容由遇见数据集搜集并总结生成


