GeoEDdA-TopoRel
收藏Hugging Face2025-09-02 更新2025-09-03 收录
下载链接:
https://huggingface.co/datasets/GEODE/GeoEDdA-TopoRel
下载链接
链接失效反馈官方服务:
资源简介:
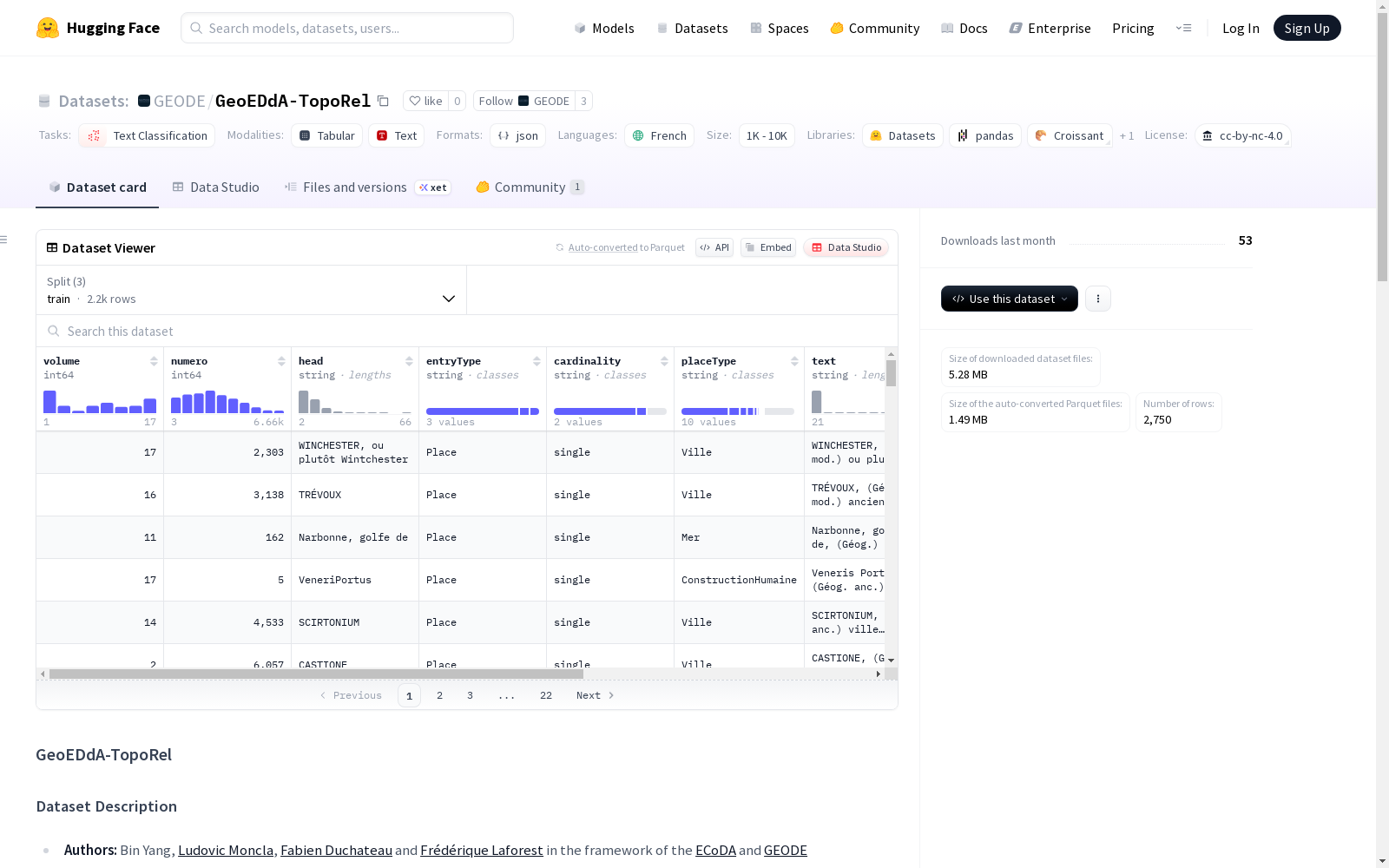
GeoEDdA-TopoRel数据集包含了2,750个来自狄德罗和达朗贝尔的《百科全书》的标注地理学条目,这些条目被用于知识图谱构建过程中的不同阶段。每个条目详细记录了包括卷号、编号、地点名称、空间关系等十个字段的信息。
创建时间:
2025-08-28
原始信息汇总
GeoEDdA-TopoRel 数据集概述
数据集基本信息
- 名称:GeoEDdA-TopoRel
- 语言:法语(French)
- 许可证:cc-by-nc-4.0
- 任务类别:文本分类(text-classification)
数据来源与作者
- 作者:Bin Yang, Ludovic Moncla, Fabien Duchateau, Frédérique Laforest
- 项目框架:ECoDA 和 GEODE 项目
- 数据来源:芝加哥大学 ARTFL Encyclopédie Project
数据集内容
- 数据量:2,750 条标注条目
- 内容来源:狄德罗和达朗贝尔的百科全书(Encyclopédie of Diderot and d’Alembert)中地理学分类条目
- 用途:为知识图谱构建流程提供特征集
数据结构
数据集以 JSON 文件格式提供,每个条目包含以下字段:
volume:条目所在卷号numero:条目编号(卷内)head:条目名称text:条目纯文本内容entryType:地理条目类型(Place、Person、Autre)cardinality:条目描述地点数量(single 或 multiple)placeType:地点类型placeNames:地名列表(包含起始位置、文本和标签)spatialRelations:空间关系列表(包含起始位置、文本和标签)segmentedDescriptions:分段描述列表(当 cardinality 为 multiple 时使用)
致谢
感谢法国国家科学研究中心(CNRS)里昂计算机科学联合会(FIL)对 ECoDA 研究项目的财政支持。
搜集汇总
数据集介绍
构建方式
GeoEDdA-TopoRel数据集源自18世纪狄德罗与达朗贝尔编纂的《百科全书》地理类条目,采用系统化知识抽取流程构建。研究团队从芝加哥大学ARTFL项目获取原始法文文本,通过人工标注与自动化处理相结合的方式,对2750个地理条目进行结构化处理。每个条目均标注了地理位置实体、空间关系及条目类型,形成了包含十类字段的标准化JSON格式数据,为地理知识图谱构建提供了高质量标注语料。
特点
该数据集突出表现为兼具历史文献价值与计算语言学特征,所有文本均采用18世纪法文书写,包含丰富的地理实体标注与空间关系标识。数据集特别标注了条目类型(地点/人物/其他)、地理实体类型(城市/国家/河流等)以及空间关系类别(如邻接关系),并创新性地引入了条目多重性标识(single/multiple)。其多层次标注体系为研究历史地理文本的空间语义理解提供了独特视角。
使用方法
研究者可通过加载JSON格式数据文件,利用volume和numero字段定位原始文献出处,基于placeNames和spatialRelations字段进行地理实体识别与空间关系抽取研究。该数据集适用于法文自然语言处理、历史地理信息系统构建、知识图谱自动化生成等多个领域。对于多地点条目,segmentedDescriptions字段提供了分段描述信息,支持细粒度的地理信息分析任务。
背景与挑战
背景概述
GeoEDdA-TopoRel数据集由Bin Yang、Ludovic Moncla等学者在ECoDA与GEODE项目框架下联合构建,源自芝加哥大学ARTFL百科全书计划的法语地理文献。该数据集专注于十八世纪狄德罗与达朗贝尔编纂的《百科全书》地理条目,旨在通过自然语言处理技术解析历史文本中的空间关系与地理实体,为数字人文领域提供结构化知识图谱构建的基础资源。
当前挑战
该数据集需解决地理实体识别与空间关系抽取的双重挑战,包括历史法语文本的语义歧义消除、非结构化描述到结构化关系的映射,以及多尺度地理实体(如城市、河流、区域)的层次化标注。构建过程中面临原始文献数字化噪声、标注一致性问题,以及跨时代地理术语与现代地理概念的对应难题。
常用场景
经典使用场景
在历史地理信息抽取领域,GeoEDdA-TopoRel数据集被广泛用于训练和评估法语文本中地理实体识别与空间关系分类模型。该数据集源自18世纪《百科全书》的地理条目,其标注体系支持对城市、河流、区域等地理实体及其拓扑关系(如邻接、包含)的自动化识别,为历史地理文献的结构化处理提供了标准化的实验数据。
解决学术问题
该数据集显著推进了历史文献数字化中地理语义解析的研究,解决了传统方法难以从复杂历史文本中提取结构化空间知识的瓶颈问题。通过提供精确的实体边界标注和关系标签,它支持地理命名实体识别(GeoNER)、空间关系抽取及知识图谱构建等核心任务,为跨学科的历史地理学研究提供了可计算的数据基础。
衍生相关工作
基于GeoEDdA-TopoRel数据集,研究者开发了多阶段地理知识图谱构建管道(如EDdA2KG),并衍生出结合BERT架构的法语地理实体识别模型。这些工作进一步推动了历史文献与空间计算领域的融合,激发了诸如时空语义标注、跨时代地理实体链接等一系列创新研究方向。
以上内容由遇见数据集搜集并总结生成


