MIHBench
收藏arXiv2025-08-01 更新2025-08-05 收录
下载链接:
https://github.com/pgtrece/DAB/
下载链接
链接失效反馈官方服务:
资源简介:
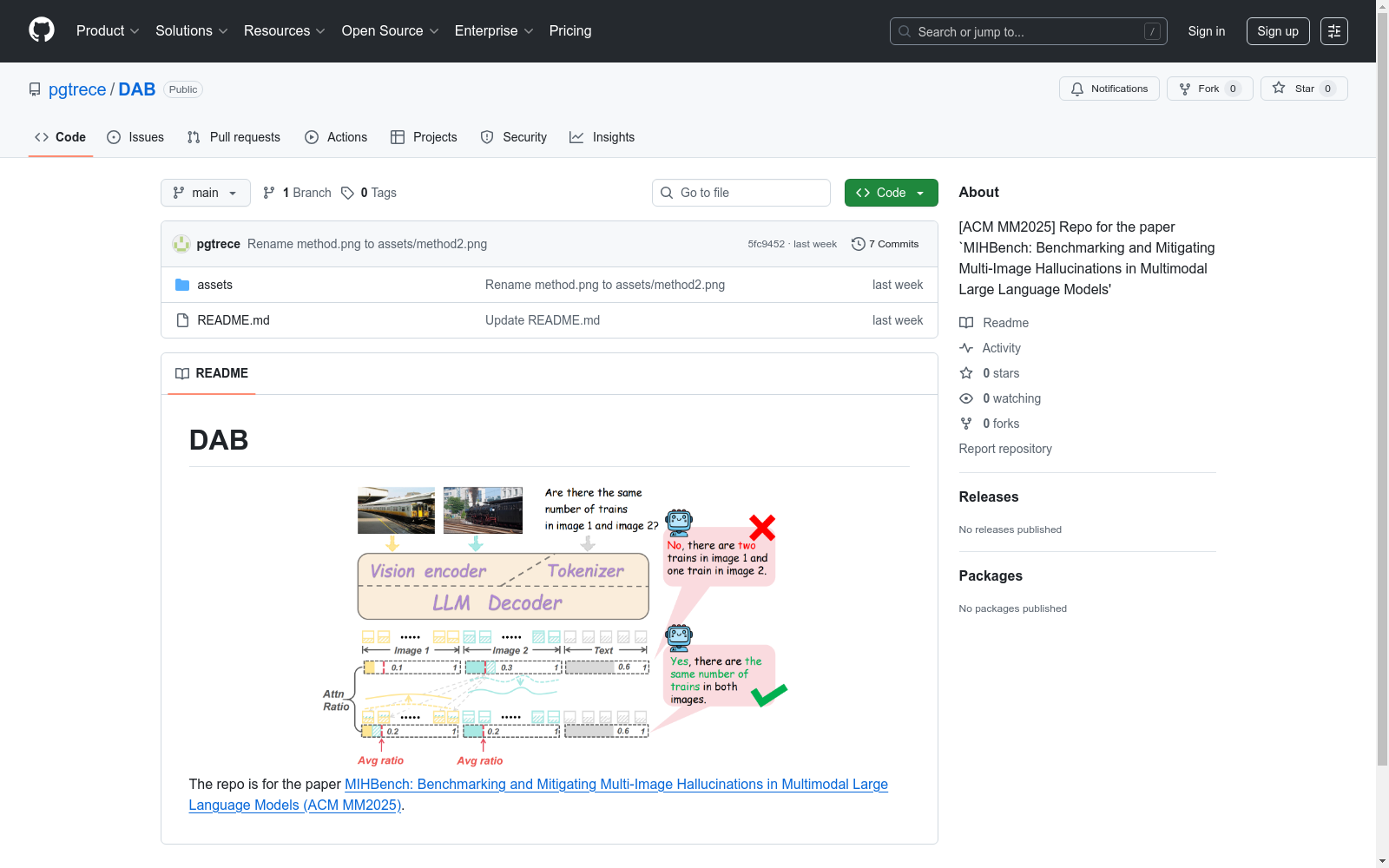
MIHBench是一个专门为评估多模态大型语言模型(MLLM)中多图像对象相关幻觉而设计的基准。该数据集包含3527张图像和4000个问题,涵盖了三个核心任务:多图像对象存在幻觉、多图像对象计数幻觉和对象身份一致性幻觉。MIHBench旨在解决多图像输入场景下MLLM的幻觉问题,通过系统地研究和评估,揭示了多图像输入对幻觉频率、传播和敏感度的影响。为应对这些挑战,论文提出了动态注意力平衡(DAB)机制,该机制在解码过程中调节图像之间的注意力分布,有效地减少了幻觉的发生,并增强了多图像场景下的语义整合和推理稳定性。
MIHBench is a benchmark specifically designed for evaluating multi-image object-related hallucinations in Multimodal Large Language Models (MLLMs). This dataset comprises 3527 images and 4000 questions, covering three core tasks: multi-image object existence hallucination, multi-image object counting hallucination, and object identity consistency hallucination. MIHBench aims to address the hallucination issue of MLLMs in multi-image input scenarios, and through systematic research and evaluation, reveals the impacts of multi-image inputs on the frequency, propagation, and sensitivity of hallucinations. To tackle these challenges, this paper proposes the Dynamic Attention Balancing (DAB) mechanism, which adjusts the attention distribution among images during the decoding process, effectively reducing the occurrence of hallucinations and enhancing semantic integration and reasoning stability in multi-image scenarios.
提供机构:
厦门大学多媒体可信感知与高效计算教育部重点实验室
创建时间:
2025-08-01
搜集汇总
数据集介绍
构建方式
MIHBench数据集的构建基于多模态大语言模型(MLLMs)在多图像场景中的幻觉现象研究。该数据集通过三个核心任务(多图像对象存在幻觉、多图像对象计数幻觉和对象身份一致性幻觉)来系统评估模型在多图像输入下的表现。构建过程中,研究者首先利用Grounding SAM模型对MSCOCO2014验证集进行标注,确保对象存在和计数的准确性。对于对象身份一致性任务,则采用CO3D数据集的多视角对象图像,通过正负样本的对比构建评估样本。每个任务都设计了严格的评估框架,确保数据集的多样性和挑战性。
特点
MIHBench数据集的特点在于其专注于多图像输入下的幻觉现象,填补了现有研究在单图像和多图像场景之间的空白。数据集包含三个互补的任务,分别针对对象存在、数量推理和跨视角身份一致性进行评测。通过精心设计的正负样本比例和位置分布,数据集能够有效揭示模型在多图像理解中的局限性。此外,数据集的构建还考虑了不同难度级别的样本,如对抗性样本和流行样本,以全面评估模型的鲁棒性。
使用方法
MIHBench数据集的使用方法主要包括三个步骤:首先,研究者可以利用该数据集评估多模态大语言模型在多图像任务中的幻觉现象,通过三个核心任务的具体表现来分析模型的弱点。其次,数据集可用于开发和验证新的幻觉缓解方法,如论文中提出的动态注意力平衡(DAB)机制。最后,研究者可以通过分析数据集中的样本分布和模型错误模式,进一步探索多图像幻觉的成因和解决方案。数据集的使用不仅限于评测,还可用于模型训练和优化,以提升多图像场景下的语义理解和推理能力。
背景与挑战
背景概述
MIHBench是由厦门大学可信多媒体感知与高效计算教育部重点实验室的研究团队于2025年提出的首个专注于多图像多模态大语言模型(MLLMs)幻觉现象的系统性评测基准。该数据集针对多图像场景下的对象级视觉幻觉问题,设计了三大核心任务:多图像对象存在性幻觉、多图像对象计数幻觉和对象身份一致性幻觉。研究团队通过构建包含3,527张图像和4,000个问题的标准化测试集,填补了现有研究主要关注单图像场景的空白。该工作发表在ACM Multimedia 2025会议上,为评估MLLMs在多图像语义整合与跨视图推理能力方面建立了重要范式。
当前挑战
MIHBench针对三大核心挑战展开研究:在领域问题层面,多图像输入导致语义整合困难,表现为对象存在误判率随图像数量增加而显著上升(准确率下降达12.8%);构建过程中面临跨数据集标注一致性难题,需协调MSCOCO和CO3D数据集的不同标注标准;在模型行为层面发现注意力分配失衡现象,实验显示首末帧图像注意力差异可达47.3%,导致关键视觉线索被忽略。此外,负样本位置敏感性测试表明,末端插入的干扰图像被忽略概率比首部高31.5%,凸显多图像序列处理的固有复杂性。
常用场景
经典使用场景
MIHBench数据集在多模态大语言模型(MLLMs)研究中扮演着关键角色,特别是在评估多图像输入场景下的幻觉现象。其经典使用场景包括对模型在对象存在性、数量推理和跨视图一致性三个核心任务中的表现进行系统评估。通过精心设计的实验设置,研究人员能够量化模型在处理多图像输入时的幻觉倾向,为模型优化提供明确的方向。
衍生相关工作
基于MIHBench的发现,衍生出了多项重要研究工作。其中包括对注意力机制的改进研究、多模态幻觉传播路径分析,以及跨模态一致性增强方法。特别值得注意的是,该数据集启发了后续MMIU、MuirBench等多图像理解基准的构建,推动了多模态大模型在复杂场景下的可靠性研究进程。
数据集最近研究
最新研究方向
随着多模态大语言模型(MLLMs)在复杂视觉语言任务中的广泛应用,多图像输入场景下的幻觉问题逐渐成为研究焦点。MIHBench作为首个针对多图像幻觉的系统性评测基准,通过对象存在性、数量一致性和跨视角身份一致性三大任务,揭示了输入图像数量与幻觉概率的渐进关系、单图像幻觉的传播效应以及负样本空间分布对模型判断的显著影响。该研究提出的动态注意力平衡机制(DAB)通过自适应调整图像间注意力分布,在保持总体视觉注意力比例的同时,显著提升了Qwen-VL、InternVL等主流模型在多图像场景下的语义整合与推理稳定性。这项工作不仅填补了多模态幻觉研究在跨图像分析领域的空白,更为构建鲁棒的多图像理解系统提供了方法论支撑和实证基础。
相关研究论文
- 1MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models厦门大学多媒体可信感知与高效计算教育部重点实验室 · 2025年
以上内容由遇见数据集搜集并总结生成


