REPA (Russian Error Types Annotation)
收藏arXiv2025-03-17 更新2025-03-19 收录
下载链接:
https://huggingface.co/datasets/RussianNLP/repa
下载链接
链接失效反馈官方服务:
资源简介:
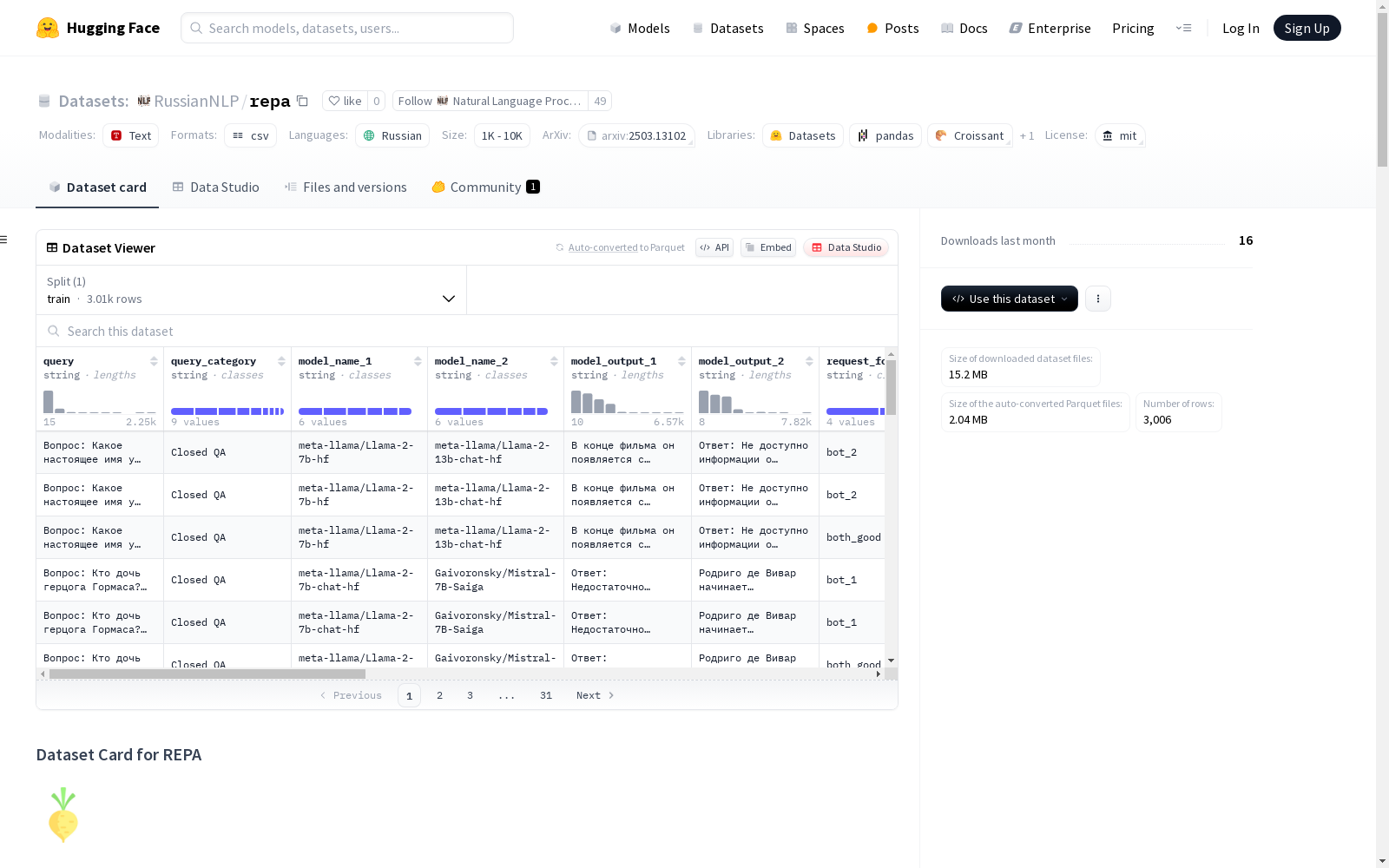
REPA数据集是由俄罗斯高等经济学院、SaluteDevices、奥斯陆大学和Toloka AI共同创建的,包含1003个用户查询和2000个LLM生成响应的数据集。该数据集通过人类标注,对十个特定错误类型进行了标注,并选择了一个总体的偏好。REPA旨在评估文本生成基于细粒度标准的问题,并解决非英语语言中LLM评估的可靠性问题。
The REPA dataset was jointly created by the National Research University Higher School of Economics (Russia), SaluteDevices, University of Oslo, and Toloka AI. It includes 1003 user queries and 2000 responses generated by Large Language Models (LLMs). This dataset has undergone human annotation, with labels for ten specific error types and an overall preference annotation. The REPA dataset aims to evaluate text generation tasks against fine-grained criteria, and address the reliability challenges of LLM evaluation in non-English languages.
提供机构:
俄罗斯高等经济学院,SaluteDevices,奥斯陆大学,Toloka AI
创建时间:
2025-03-17
搜集汇总
数据集介绍
构建方式
REPA数据集的构建过程分为三个主要步骤:首先,从公开数据集中收集俄语用户查询,涵盖多种对话场景和任务类型;其次,使用六种开源指令微调的大语言模型生成对这些查询的响应;最后,通过人工标注对每对响应进行细粒度的错误类型标注,涵盖请求遵循、事实准确性、重复等十类错误。标注过程由三名母语为俄语的标注员完成,采用多数投票机制确保标注的一致性。
使用方法
REPA数据集的主要用途是评估大语言模型在俄语生成任务中的表现。研究人员可以使用该数据集进行模型间的对比分析,评估模型在不同错误类型上的表现,并探索模型作为“评委”时的能力。此外,REPA还可用于研究模型在零样本和少样本设置下的表现,以及分析模型在位置和长度偏差上的倾向性。通过结合人类标注和模型生成的偏好数据,REPA为俄语生成模型的评估提供了一个可靠的基准。
背景与挑战
背景概述
REPA(Russian Error Types Annotation)数据集由Alexander Pugachev、Alena Fenogenova等研究人员于2025年提出,旨在评估俄语文本生成模型的能力。该数据集包含1000个用户查询和2000个由六个不同大语言模型生成的响应,涵盖了生成、开放问答、头脑风暴等多种任务类型。REPA的核心研究问题是通过细粒度的错误类型标注,评估俄语生成模型的表现,并探讨大语言模型作为评判者的潜力。该数据集的创建填补了非英语语言生成评估领域的空白,尤其是在俄语环境下,为研究大语言模型在非英语语言中的表现提供了重要基准。
当前挑战
REPA数据集面临的挑战主要集中在两个方面。首先,在领域问题方面,俄语生成模型的评估相较于英语存在显著差距,尤其是在细粒度错误类型(如逻辑矛盾、流畅性等)的识别上,模型表现较差。其次,在数据集构建过程中,研究人员面临了标注一致性和模型偏见问题。尽管通过多数投票机制确保了标注的一致性,但模型在评估时仍表现出位置偏见和长度偏见,即模型倾向于选择位置靠前或更长的响应,而非基于内容质量进行判断。这些挑战表明,尽管大语言模型在俄语生成评估中具备一定潜力,但仍需进一步优化以提高其与人类评判的一致性。
常用场景
经典使用场景
REPA数据集主要用于评估俄语大语言模型(LLMs)在文本生成任务中的表现。通过提供1,000个用户查询和2,000个由不同LLM生成的响应,REPA数据集允许研究人员对模型生成的文本进行细粒度的错误类型标注。这些错误类型包括请求遵循、事实性、重复、代码切换等,涵盖了文本生成中的常见问题。数据集的设计使得研究人员能够通过人类标注和LLM作为评判者的方式,对模型生成的文本进行多角度的评估。
解决学术问题
REPA数据集解决了在非英语语言环境下,尤其是俄语环境中,LLM生成文本的评估难题。通过引入细粒度的错误类型标注,REPA为研究人员提供了一个标准化的评估框架,能够更准确地衡量模型在生成文本时的表现。此外,该数据集还揭示了LLM作为评判者在俄语环境中的表现与英语环境之间的显著差距,为未来的模型改进提供了方向。
实际应用
REPA数据集的实际应用场景广泛,尤其是在俄语自然语言处理领域。它可以用于评估和改进俄语LLM的文本生成能力,帮助开发者在实际应用中优化模型的输出质量。此外,REPA还可以用于教育领域,帮助语言学习者识别和纠正文本生成中的常见错误。在商业应用中,REPA可以用于评估聊天机器人和虚拟助手的表现,确保其生成的文本符合用户需求和语言规范。
数据集最近研究
最新研究方向
近年来,随着大语言模型(LLMs)在文本生成任务中的广泛应用,如何有效评估这些模型的输出质量成为了研究热点。REPA(Russian Error Types Annotation)数据集作为首个针对俄语文本生成任务的人工标注基准,为俄语环境下的LLM评估提供了重要支持。该数据集通过引入十种细粒度的错误类型,如请求遵循、事实性、重复等,结合人类偏好标注,深入探讨了LLM作为评估者(LLM-as-a-judge)在俄语环境中的表现。研究发现,尽管LLM评估者在俄语中的表现与英语相比存在显著差距,但其评估结果与人类偏好部分一致,表明LLM评估者在俄语文本生成任务中仍具备一定的潜力。此外,REPA数据集的发布为俄语LLM的细粒度评估提供了新的研究工具,推动了多语言环境下LLM评估方法的发展。
相关研究论文
- 1REPA: Russian Error Types Annotation for Evaluating Text Generation and Judgment Capabilities俄罗斯高等经济学院,SaluteDevices,奥斯陆大学,Toloka AI · 2025年
以上内容由遇见数据集搜集并总结生成


