tiny_qa_benchmark_pp
收藏Hugging Face2025-05-17 更新2025-05-18 收录
下载链接:
https://huggingface.co/datasets/vincentkoc/tiny_qa_benchmark_pp
下载链接
链接失效反馈官方服务:
资源简介:
Tiny QA Benchmark++ (TQB++)是一个超轻量级的评估套件,旨在几秒钟内揭示大型语言模型(LLM)系统中的关键错误。它相当于软件单元测试的大型语言模型模拟,适合用于现代LLMOps中的快速CI/CD检查、提示工程和持续质量保证。该数据集包含一个经过人工校对的核心英语问答数据集以及各种合成的多语言和专题数据包。
创建时间:
2025-05-16
原始信息汇总
Tiny QA Benchmark++ (TQB++) 数据集概述
基本信息
- 许可证:
- 核心数据集: Apache-2.0
- 预生成合成数据集包: Eval-Only, Non-Commercial, No-Derivatives
- 数据集卡片和元数据: CC0-1.0
- 任务类别: 问答系统
- 任务ID: 抽取式问答、闭卷问答
- 语言: 英语(en)、德语(de)、阿拉伯语(ar)、韩语(ko)、法语(fr)、葡萄牙语(pt)、中文(zh)、日语(ja)、西班牙语(es)、土耳其语(tr)、俄语(ru)
- 标签: 合成数据、问答、评估、基准测试、LLMOps、冒烟测试
- 数据规模: 小于1K样本
数据集组成
-
核心英语数据集 (
core_en)- 52个手工制作的英语问答对
- 涵盖地理、历史、科学、数学、文学等通用知识
- 用于确定性回归测试的不可变黄金标准
-
合成生成的数据包 (
packs)- 多语言和主题微基准测试(如
pack_fr_40、pack_en_science_10) - 使用TQB++生成工具包创建
- 包含
id、lang(语言代码)和sha256(来源验证)字段
- 多语言和主题微基准测试(如
数据格式
- JSON Lines (
.jsonl)格式 - 每个JSON对象包含字段:
text: 问题提示label: 正确答案metadata.context: 支持答案的事实陈述tags.category: 问题所属的广泛类别tags.difficulty: 难度级别(easy、medium、hard)
主要用途
- 快速CI/CD检查
- 提示工程
- 跨语言漂移检测
- 针对性评估
- 评估工具集成
引用信息
bibtex @misc{koctinyqabenchmarkpp, author = {Vincent Koc}, title = {Tiny QA Benchmark++ (TQB++) Datasets and Toolkit}, year = {2025}, publisher = {Hugging Face & GitHub}, doi = {10.57967/hf/5531}, howpublished = {https://huggingface.co/datasets/vincentkoc/tiny_qa_benchmark_pp}, note = {See also: https://github.com/vincentkoc/tiny_qa_benchmark_pp} }
@misc{koctinyqabenchmark_original, author = {Vincent Koc}, title = {tiny_qa_benchmark}, year = {2025}, publisher = {Hugging Face}, journal = {Hugging Face Hub}, doi = {10.57967/hf/5417}, url = {https://huggingface.co/datasets/vincentkoc/tiny_qa_benchmark} }
搜集汇总
数据集介绍
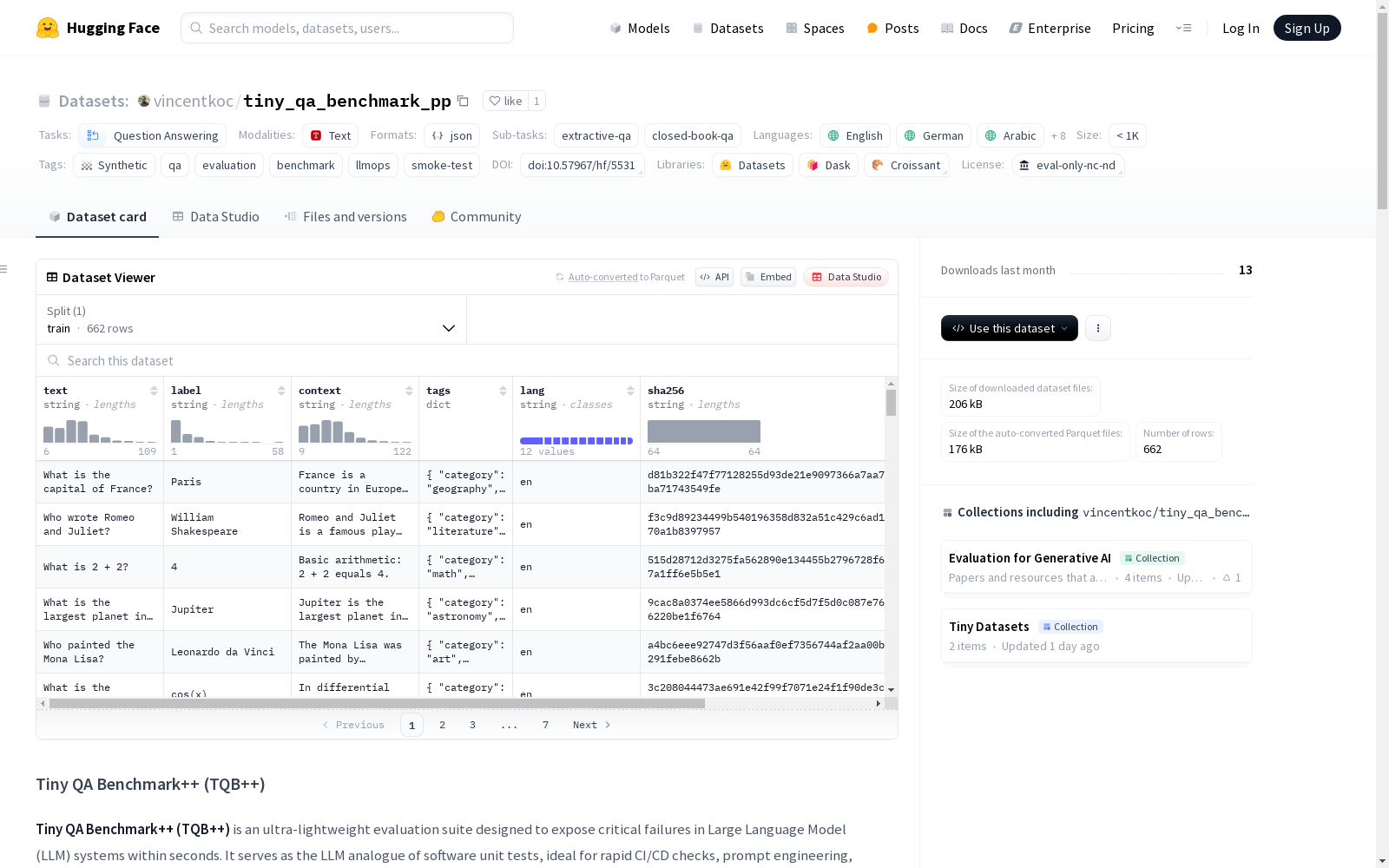
构建方式
Tiny QA Benchmark++ (TQB++) 数据集的构建采用了双轨制策略,核心部分由人工精心筛选的52项英语问答对组成,涵盖地理、历史、科学等多领域知识,作为不可变更的黄金标准。同时,通过Python脚本和LiteLLM技术生成了多语言及专题微基准测试包,支持按需定制不同语言、主题和难度的数据集,体现了模块化设计理念。
特点
该数据集以极简架构实现高效评估,核心英语数据集具有高度确定性,适用于回归测试。其特色在于支持11种语言的跨文化评估,并通过标签系统标注问题类别和难度层级。每个数据点均包含问题文本、标准答案及支持性语境,形成三位一体的验证结构,为大型语言模型提供多维度的性能检测框架。
使用方法
用户可通过Hugging Face的datasets库灵活加载不同配置,支持核心数据集或特定语言包的调用。数据集采用JSON Lines格式存储,便于流式处理。主要应用于持续集成环境的快速冒烟测试、提示工程优化及多语言性能漂移监测,其轻量级特性尤其适合高频次的模型迭代验证。集成工具包更提供与OpenAI Evals等评估框架的无缝对接,大幅降低部署门槛。
背景与挑战
背景概述
Tiny QA Benchmark++ (TQB++)是由Vincent Koc于2025年推出的超轻量级评估套件,旨在快速检测大型语言模型(LLM)系统中的关键故障。该数据集作为LLM领域的单元测试工具,为持续集成/持续交付(CI/CD)检查、提示工程和现代LLMOps中的质量保证提供了高效解决方案。其核心由52项人工精心策划的英语问答数据组成,涵盖地理、历史、科学、数学、文学等多个领域的通用知识,并辅以多种语言和主题的合成数据集包,为跨语言性能评估和特定领域测试提供了灵活支持。
当前挑战
TQB++面临的挑战主要体现在两个方面:在领域问题层面,该数据集需要解决多语言问答系统中存在的语义漂移和跨文化知识差异问题,同时确保对LLM系统关键故障的检测具有足够敏感性和特异性;在构建过程中,人工标注的核心数据集需要平衡覆盖范围与规模精简的矛盾,而合成数据包的生成则需克服语言多样性保持与数据质量控制的挑战,特别是在非英语语种中保持问题表述的自然性和答案的准确性。
常用场景
经典使用场景
在大型语言模型(LLM)系统的开发与评估中,Tiny QA Benchmark++(TQB++)作为一种轻量级评估套件,被广泛应用于快速检测模型的关键性错误。其核心英文数据集和多种合成数据集包为研究人员和工程师提供了高效的测试工具,特别适用于持续集成与持续部署(CI/CD)流程中的快速验证。通过覆盖地理、历史、科学、数学和文学等多个领域的知识,TQB++能够迅速揭示模型在问答任务中的潜在缺陷。
实际应用
在实际应用中,TQB++被广泛集成到LLM的开发流程中,用于支持快速迭代和优化。例如,在提示工程中,开发者可以通过TQB++快速验证不同提示模板的效果;在多语言模型开发中,TQB++的合成数据集包能够帮助检测模型在不同语言间的性能漂移。此外,TQB++还被用于教育领域,作为教学工具帮助学生理解问答系统的评估方法。
衍生相关工作
围绕TQB++数据集,研究者们开发了一系列相关工具和框架,例如与OpenAI Evals和Comet Opik等评估工具的集成支持。这些工作进一步扩展了TQB++的应用范围,使其能够无缝嵌入现有的模型评估流程中。同时,TQB++的生成工具包也为研究者提供了自定义数据集的能力,推动了更多针对特定领域或语言的研究。
以上内容由遇见数据集搜集并总结生成


