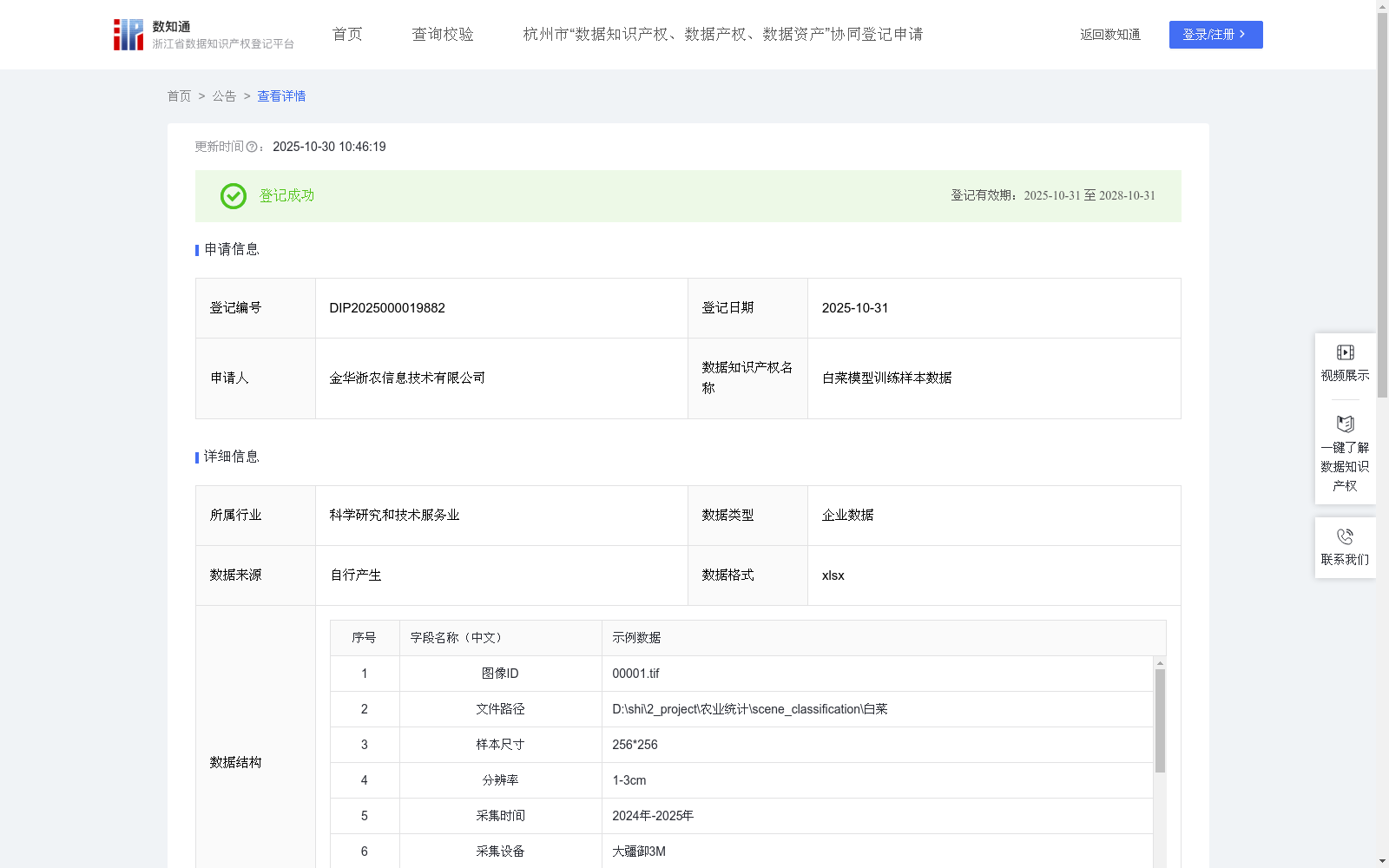
白菜模型训练样本数据
收藏浙江省数据知识产权登记平台2025-10-30 更新2025-10-31 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/6875673
下载链接
链接失效反馈官方服务:
资源简介:
1. 精准农业与管理:通过对作物冠层形态、颜色的精细标注,训练的模型可用于监测作物长势、精准估算产量、早期发现病虫害及杂草分布,从而指导变量施肥、施药,大幅提升农业生产效率和资源利用率。
2. 生态环境监测与保护:利用标注好的样本数据,模型可学会识别不同树种、草地乃至入侵物种。其应用包括森林资源调查、生物多样性评估、生态环境破坏(如非法砍伐)监测以及湿地、自然保护区生态变化的动态跟踪与保护。
3. 林业调查与碳汇核算:模型能够对林木种类、健康状态、郁闭度甚至单木进行识别和统计,应用于森林蓄积量估算、林业病虫害预警、火灾后受损评估等,为林业碳汇的精准计量提供重要数据支撑。
4. 灾害应急与评估:在洪涝、山体滑坡、森林火灾等自然灾害发生后,通过训练模型快速识别受灾区域的植被损毁情况,为灾情评估、救援部署及灾后生态恢复规划提供及时、准确的决策依据。
高质量的训练样本数据是植被识别模型在实际场景中发挥效用的基石,使得低空遥感技术能够从“看得见”升级为“看得懂”,赋能多个行业的数字化、智能化管理。1、数据采集:利用大疆御3M无人机,利用自动拼图得到1cm-3cm分辨率的无人机正射影像数据,并设置CGCS2000 / 3°投影坐标系,影像分辨率以及影像坐标系等参数同步加入至影像数据中。 2、数据预处理以及数据标注:首先,选择适用于样本的影像,明确裁切区域并绘制范围矢量;利用矢量数据裁切影像,采用在线标记点位并添加作物属性的方式,以点位为中心点进行裁剪,生成指定尺寸(如256*256)的影像切片。 3、数据集设置以及模型选择:按照7:2:1的比例设置训练集、验证集和测试集。使用自行搭建的TransCNN-Vision模型进行训练。 5、训练设置:模型选择与初始化以vision_transformer的large模型为权重文件,初始化常规模型参数后,读取数据集文件夹个数确定模型分类数,最优学习率为0.001,同时冻结出head和pre_logits外的所有权重参数,batchsize,根据当前设备现存余量自动调整,默认值为16,根据样本分辨率动态调整patch_size用于提高不同分辨率下的特征捕获能力。最后利用自适应高精度模型保存策略,自动保存训练精度mDice(Mean Dice Coefficient)指标最高模型的模型作为最佳模型。mDice计算公式如下: mDice=2*|X∩Y|/(|X|+|Y|)。 训练mDice指数基于对测试集样本数据预测并计算获得,其中|X∩Y|为预测结果与真实标注的交集,| X |和| Y |分别为预测结果与真实标签的各自的数量之和。 5、模型精度评估:通过在真实影像中进行模型分类并人工校正,实现对模型在真实场景中的分类效果。利用分类错误率和分类遗漏率指标来评估被识别物模型的分类能力,分类错误率用于评估模型分类结果中不是合理的比例,分类遗漏率用于评估模型分类结果依然没有分类出被识别物的比例,分类遗漏率越接近4.2%,分类错误率越接近6.2%,表明当前分类结果准确率越高,能够降低的成本越高。分类错误率计算公式如下:(|X|-|X∩Y|)/|X|。 分类遗漏率计算公式如下:(|Y|-|X∩Y|)/|Y|。其中,|X∩Y|为正确识别为被识别物的数量,| X |和| Y |分别为预测和真实的被识别数量。考虑到真实场景的复杂性,分类错误率和分类遗漏率保持在10%以内即可视为结果具有较高的准确性。
1. Precision Agriculture and Management: By precisely annotating crop canopy morphology and color, the trained model can be used to monitor crop growth, accurately estimate yield, detect pests, diseases and weed distribution at an early stage, thereby guiding variable-rate fertilization and pesticide application, and greatly improving agricultural production efficiency and resource utilization efficiency.
2. Ecological Environment Monitoring and Protection: Using the annotated sample data, the model can learn to identify different tree species, grasslands and even invasive species. Its applications include forest resource surveys, biodiversity assessments, monitoring of ecological environment damage (such as illegal logging), and dynamic tracking and protection of ecological changes in wetlands and nature reserves.
3. Forestry Survey and Carbon Sink Accounting: The model can identify and count tree species, health status, canopy closure and even individual trees. It is applied to forest volume estimation, forestry pest and disease early warning, post-fire damage assessment, etc., providing important data support for accurate measurement of forest carbon sinks.
4. Disaster Emergency Response and Assessment: After natural disasters such as floods, landslides and forest fires, the trained model can quickly identify vegetation damage in affected areas, providing timely and accurate decision-making basis for disaster assessment, rescue deployment and post-disaster ecological restoration planning.
High-quality training sample data is the cornerstone for vegetation recognition models to exert their effectiveness in real-world scenarios, enabling low-altitude remote sensing technology to upgrade from "seeing" to "understanding", and empowering digital and intelligent management in multiple industries.
1. Data Collection: Use the DJI Mavic 3M drone to obtain 1cm-3cm resolution UAV orthophoto imagery data via automatic mosaicking, set the CGCS2000 / 3° projected coordinate system, and synchronize parameters such as image resolution and image coordinate system into the image data.
2. Data Preprocessing and Annotation: First, select suitable images, define the cropping area and draw range vectors; crop the images using the vector data, adopt the method of online marking points and adding crop attributes, take the marking points as the center to perform cropping, and generate image slices of specified dimensions (such as 256*256).
3. Dataset Setup and Model Selection: Divide the dataset into training set, validation set and test set at a ratio of 7:2:1. Use the self-built TransCNN-Vision model for training.
5. Training Settings: Initialize the model using the weight file of the vision_transformer large model as the pre-trained weights. After initializing the conventional model parameters, determine the number of model classification categories by reading the number of dataset folders. The optimal learning rate is 0.001. At the same time, freeze all weight parameters except the head and pre_logits layers. The batch size is automatically adjusted according to the remaining memory of the current device, with a default value of 16. Dynamically adjust the patch_size based on the sample resolution to improve feature capture capability under different resolutions. Finally, adopt an adaptive high-precision model saving strategy to automatically save the model with the highest training mDice (Mean Dice Coefficient) metric as the best model.
The calculation formula of mDice is as follows:
mDice = 2 * |X ∩ Y| / (|X| + |Y|)
The training mDice index is obtained by predicting and calculating the sample data of the test set, where |X ∩ Y| is the intersection of the prediction results and the ground truth annotations, and |X| and |Y| are the total number of predicted results and ground truth labels respectively.
5. Model Accuracy Evaluation: Evaluate the classification effect of the model in real scenarios by performing model classification on real images and conducting manual correction. Use the classification error rate and classification omission rate metrics to evaluate the classification capability of the model for identified objects. The classification error rate is used to evaluate the proportion of unreasonable results in the model's classification outputs, while the classification omission rate is used to evaluate the proportion of identified objects that are not classified in the model's outputs. The closer the classification omission rate is to 4.2% and the classification error rate is to 6.2%, the higher the accuracy of the current classification results and the greater the cost reduction that can be achieved.
The calculation formula of the classification error rate is as follows:
Classification Error Rate = (|X| - |X ∩ Y|) / |X|
The calculation formula of the classification omission rate is as follows:
Classification Omission Rate = (|Y| - |X ∩ Y|) / |Y|
Where |X ∩ Y| is the number of correctly identified objects, |X| is the number of predicted identified objects, and |Y| is the number of real identified objects. Considering the complexity of real scenarios, keeping the classification error rate and classification omission rate within 10% can be regarded as indicating that the results have high accuracy.
提供机构:
金华浙农信息技术有限公司
创建时间:
2025-09-09
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是金华浙农信息技术有限公司登记的白菜模型训练样本数据,包含1355条企业数据,以xlsx格式存储,通过无人机采集高分辨率图像,用于训练TransCNN-Vision模型,分类错误率和遗漏率低至6.2%和4.2%,适用于精准农业、环境监测等场景,支持行业数字化管理。
以上内容由遇见数据集搜集并总结生成


