zhangfaen/DocumentVQA
收藏Hugging Face2024-07-04 更新2024-07-06 收录
下载链接:
https://hf-mirror.com/datasets/zhangfaen/DocumentVQA
下载链接
链接失效反馈官方服务:
资源简介:
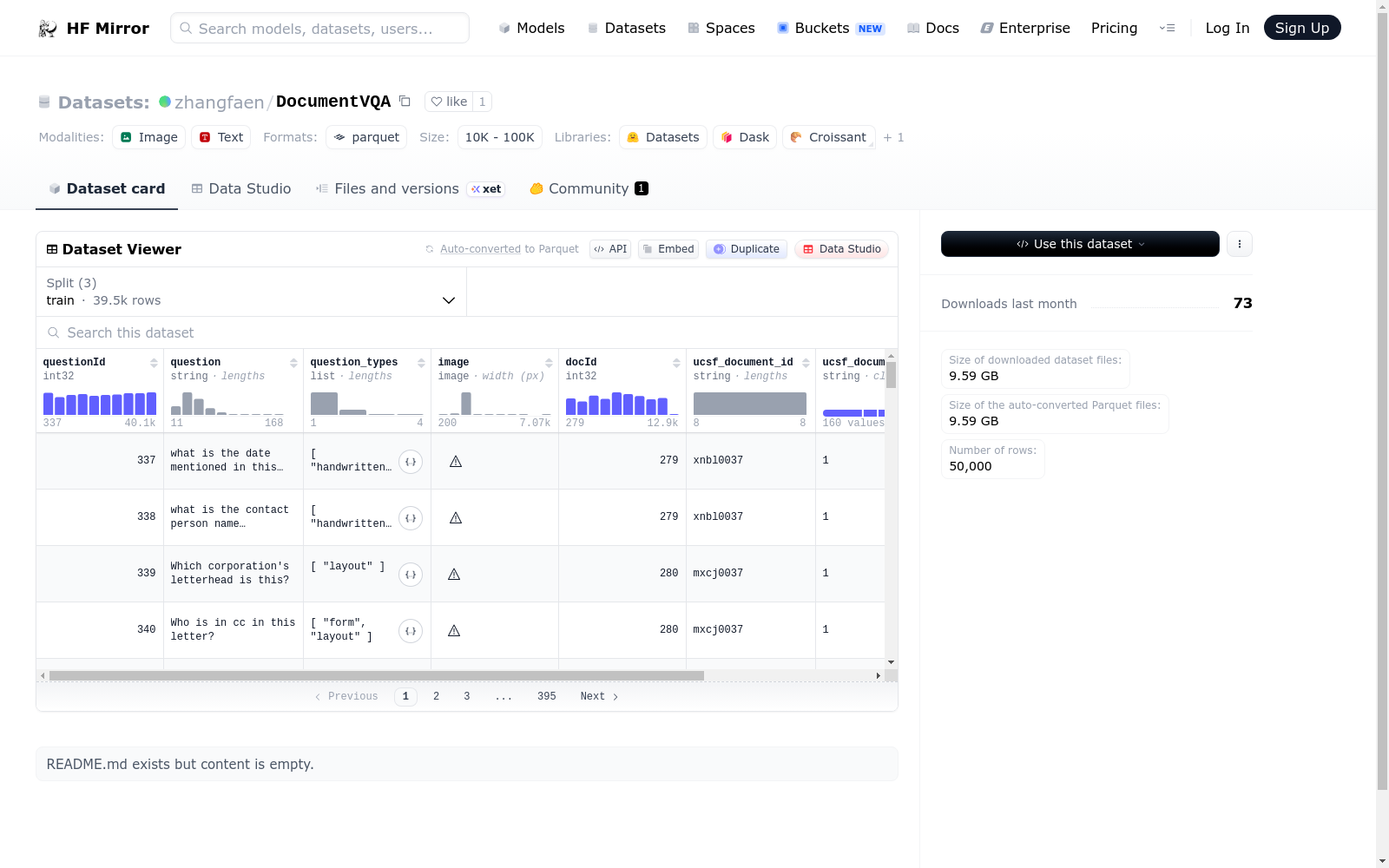
该数据集包含多个字段,主要涉及问题、问题类型、图像、文档ID、UCSF文档ID、UCSF文档页码以及答案等信息。数据集被分为训练集、验证集和测试集,分别包含39463、5349和5188个样本。数据集的下载大小为9591606021字节,总大小为10690986865.428999字节。
This dataset is primarily used for multimodal question answering tasks, featuring attributes such as question ID, question text, question types, images, document ID, and a list of answers. The dataset is divided into training, validation, and test sets, each with specified numbers of examples and byte sizes. The total download size and actual size of the dataset are also provided.
提供机构:
zhangfaen
原始信息汇总
数据集概述
数据集特征
- questionId: 整数类型
- question: 字符串类型
- question_types: 字符串列表
- image: 图像类型
- docId: 整数类型
- ucsf_document_id: 字符串类型
- ucsf_document_page_no: 字符串类型
- answers: 字符串列表
数据集划分
- train:
- 样本数量: 39463
- 数据大小: 5658303093.631 字节
- validation:
- 样本数量: 5349
- 数据大小: 2532362556.066 字节
- test:
- 样本数量: 5188
- 数据大小: 2500321215.732 字节
数据集大小
- 下载大小: 9591606021 字节
- 总数据大小: 10690986865.428999 字节
配置信息
- config_name: default
- data_files:
- train: data/train-*
- validation: data/validation-*
- test: data/test-*
- data_files:
搜集汇总
数据集介绍
背景与挑战
背景概述
DocumentVQA是一个文档视觉问答数据集,包含文档图像、相关文本问题及多个参考答案,适用于文档理解和信息提取任务。数据集规模中等,提供训练、验证和测试集划分,支持多种文档类型的问题回答。
以上内容由遇见数据集搜集并总结生成


