histopathology
收藏Hugging Face2025-02-11 更新2025-02-12 收录
下载链接:
https://huggingface.co/datasets/Cilem/histopathology
下载链接
链接失效反馈官方服务:
资源简介:
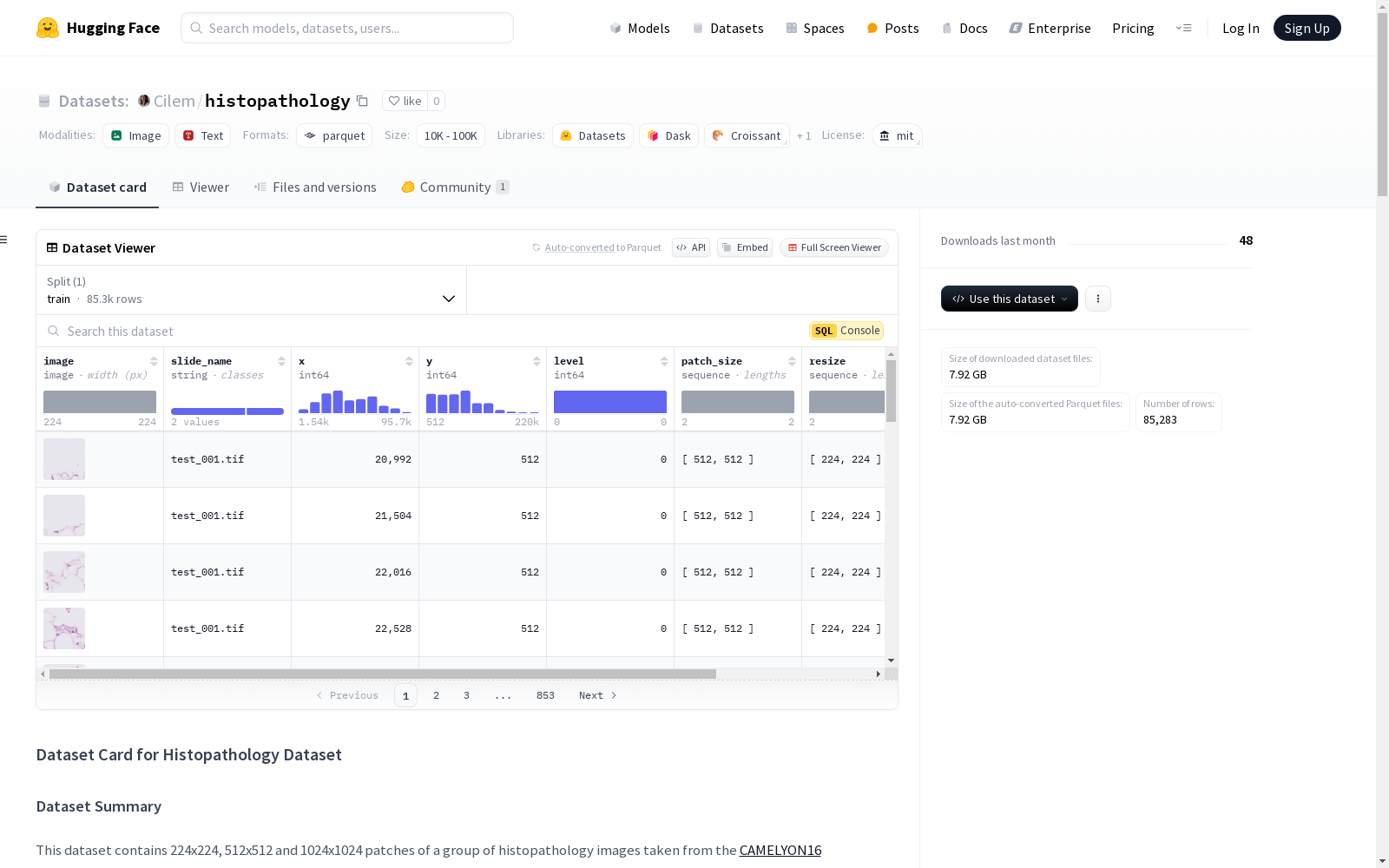
该数据集包含了从CAMELYON16数据集中获取的224x224、512x512和1024x1024的病理图像片段,以及使用Google Path Foundation模型从这些片段中提取的embedding vectors。这些图像片段和向量可以用于机器学习应用,如分类、分割和图像生成。
This dataset contains 224×224, 512×512, and 1024×1024 pathological image patches extracted from the CAMELYON16 dataset, alongside embedding vectors extracted from these patches using the Google Path Foundation model. These image patches and vectors can be utilized for machine learning applications such as classification, segmentation, and image generation.
创建时间:
2025-02-08
搜集汇总
数据集介绍
构建方式
本数据集的构建基于CAMELYON16数据集中的组织病理学图像,从中裁剪出224x224、512x512和1024x1024像素的图像块,并利用Google Path Foundation模型提取了这些图像块的嵌入向量。数据集包含图像块、主幻灯片名称、坐标、幻灯片级别、图像块大小、调整后的图像大小以及通过Path Foundation模型提取的嵌入向量。
特点
该数据集的特点在于其包含了不同分辨率的图像块,以及对应的嵌入向量,这使得数据集不仅适用于图像分类、分割等任务,还能够支持图像生成等机器学习应用。数据集的构建遵循MIT许可,保证了使用的便捷性和灵活性。
使用方法
使用该数据集时,用户可以通过HuggingFace的datasets库轻松加载。加载后,用户可以访问图像块、嵌入向量等信息,以支持机器学习模型的训练和评估。数据集的加载和访问过程简洁明了,有助于提高研究效率。
背景与挑战
背景概述
在医学图像分析领域,histopathology数据集的构建旨在推动病理学图像的自动化识别与分析。该数据集源自CAMELYON16挑战,由一组224x224、512x512及1024x1024像素的病理学图像切片组成,并包含了利用Google Path Foundation模型提取的嵌入向量。histopathology数据集的创建,可追溯至2016年,由多个研究机构和学者共同参与,其核心研究问题聚焦于通过机器学习技术实现病理图像的精准分类和分割,对癌症诊断与治疗等领域产生了显著影响。
当前挑战
在数据集构建和应用过程中,研究者们面临了诸多挑战。首先,确保图像数据的质量和一致性是关键,这要求在图像采集、处理和标注过程中采用严格的标准。其次,数据集在分类和分割任务中存在标签不平衡问题,这可能导致模型偏向于多数类别的预测。此外,利用Google Path Foundation模型提取嵌入向量时,计算资源和时间的消耗也是一个不容忽视的问题。在使用该数据集时,还需考虑模型的泛化能力,以及可能存在的社会影响和偏见问题。
常用场景
经典使用场景
在医学图像分析领域,histopathology数据集因其包含了从CAMELYON16数据集中提取的病理图像片段及其对应的嵌入向量,而被广泛应用于图像分类、分割和生成等任务。该数据集提供了不同分辨率的图像片段,使得研究者能够针对不同的研究需求选择合适的图像尺寸进行分析。
实际应用
在实际应用中,histopathology数据集可被用于构建辅助诊断系统,通过机器学习模型分析病理图像,帮助医生更准确地进行疾病诊断和预后评估,提高医疗诊断的效率和精确度。
衍生相关工作
基于histopathology数据集,研究者们开展了一系列相关工作,如开发新的图像分割算法、特征提取方法和疾病预测模型,这些研究进一步扩展了数据集的应用范围,并推动了医学图像分析技术的发展。
以上内容由遇见数据集搜集并总结生成


