salmanhermana/Food_dataset_test
收藏Hugging Face2024-06-28 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/salmanhermana/Food_dataset_test
下载链接
链接失效反馈官方服务:
资源简介:
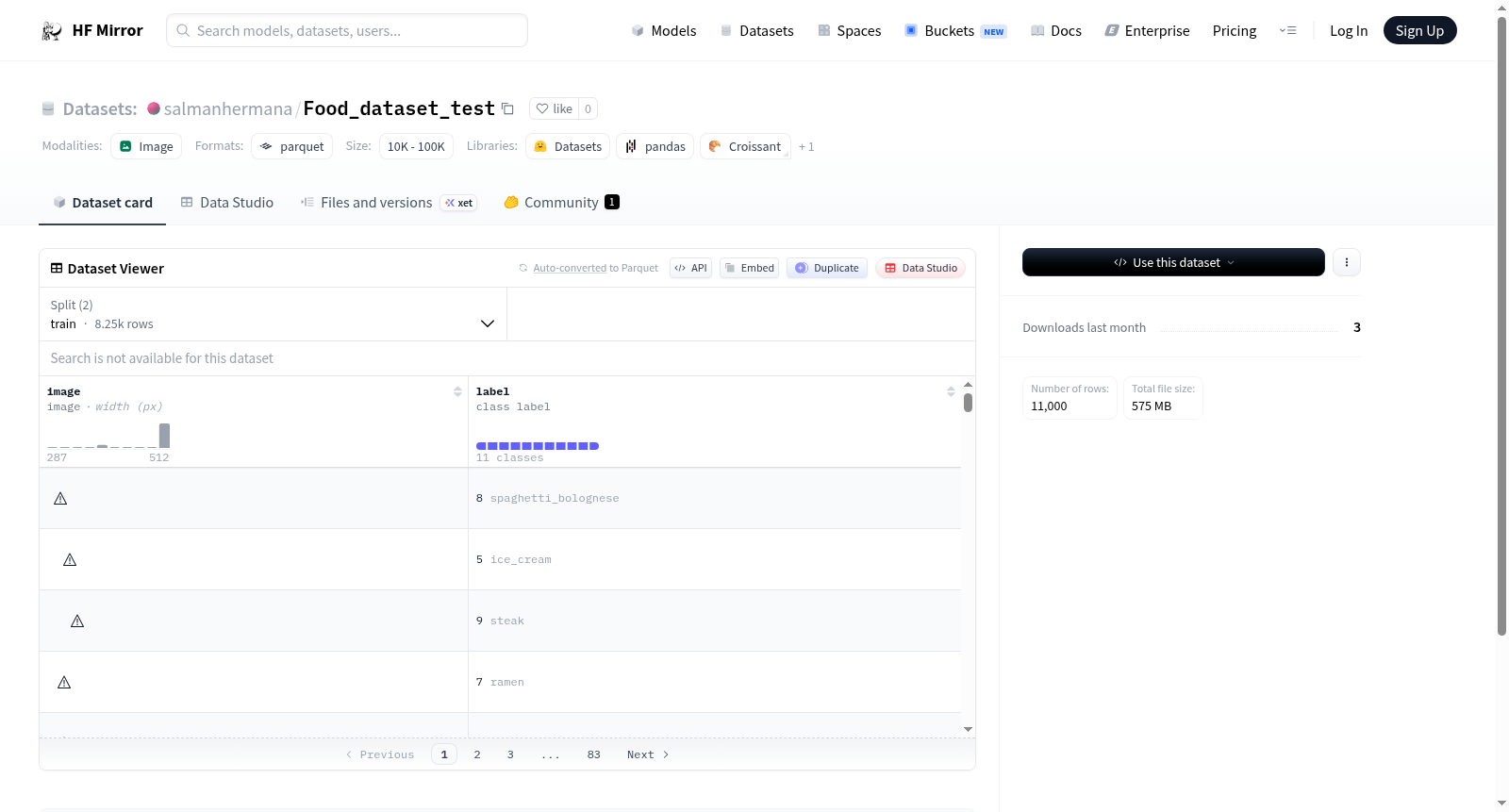
该数据集包含图像和标签两个特征。图像特征的数据类型为图像,标签特征的数据类型为分类标签,具体包括11种不同的食物类别,如凯撒沙拉、咖喱鸡、炸薯条、炒饭、汉堡、冰淇淋、披萨、拉面、意大利肉酱面、牛排和寿司。数据集分为训练集和测试集,训练集包含8250个样本,测试集包含2750个样本。数据集的下载大小为574654089字节,总大小为580166675.25字节。
该数据集包含图像和标签两个特征。图像特征的数据类型为图像,标签特征的数据类型为分类标签,具体包括11种不同的食物类别,如凯撒沙拉、咖喱鸡、炸薯条、炒饭、汉堡、冰淇淋、披萨、拉面、意大利肉酱面、牛排和寿司。数据集分为训练集和测试集,训练集包含8250个样本,测试集包含2750个样本。数据集的下载大小为574654089字节,总大小为580166675.25字节。
提供机构:
salmanhermana
原始信息汇总
数据集概述
特征
- image: 图像数据
- label: 分类标签
- 类别名称:
- 0: caesar_salad
- 1: chicken_curry
- 2: french_fries
- 3: fried_rice
- 4: hamburger
- 5: ice_cream
- 6: pizza
- 7: ramen
- 8: spaghetti_bolognese
- 9: steak
- 10: sushi
- 类别名称:
数据集划分
- train:
- 样本数量: 8250
- 数据大小: 434764285.5 字节
- test:
- 样本数量: 2750
- 数据大小: 145402389.75 字节
数据集大小
- 下载大小: 574654089 字节
- 总数据大小: 580166675.25 字节
配置
- default:
- 训练数据路径: data/train-*
- 测试数据路径: data/test-*
搜集汇总
数据集介绍
构建方式
在食品图像识别领域,数据集的构建需兼顾多样性与代表性。该数据集通过系统采集与标注流程,收录了涵盖11类常见食品的图像样本,包括凯撒沙拉、咖喱鸡、薯条等。构建过程中,图像数据被划分为训练集与测试集,分别包含8250与2750个样本,确保了模型训练与评估的完整性。数据以标准图像格式存储,并附带类别标签,为机器学习任务提供了结构化基础。
特点
本数据集的特点体现在其精细的类别划分与均衡的数据分布上。11类食品图像覆盖了从西餐到亚洲料理的广泛范围,每类样本均经过统一预处理,保证了图像质量的一致性。数据集总容量约为580MB,训练集与测试集的比例约为3:1,这种划分有助于模型泛化能力的评估。特征结构简洁明了,仅包含图像与标签两个字段,便于直接应用于分类任务,同时支持快速加载与处理。
使用方法
使用本数据集时,研究者可通过HuggingFace平台直接加载,利用其预定义的训练与测试分割进行模型开发。图像数据可直接输入卷积神经网络进行特征提取,而类别标签则适用于监督学习框架。建议先进行数据增强操作以提升模型鲁棒性,如随机裁剪或色彩调整。评估阶段可使用测试集验证分类准确率,数据集的标准格式确保了与主流深度学习库的兼容性,加速实验迭代过程。
背景与挑战
背景概述
在计算机视觉与人工智能领域,食品图像识别作为一项重要的应用方向,旨在通过算法自动识别并分类不同种类的食物。该数据集由salmanhermana创建,专注于构建一个涵盖多种常见西式与亚洲菜品的图像集合,其核心研究问题在于提升模型对多样化食品的视觉特征提取与分类精度。此类数据集的建立,不仅推动了餐饮健康分析、智能点餐系统等应用的发展,也为跨文化食品识别研究提供了宝贵的资源。
当前挑战
食品图像识别领域面临的主要挑战在于类内差异性与类间相似性,例如同一种菜品在不同光照、角度或配料变化下呈现显著差异,而不同菜品可能具有相似的外观特征。在数据集构建过程中,挑战包括确保图像质量与标注一致性,需克服背景干扰、拍摄条件不统一以及文化差异导致的菜品定义模糊等问题,这些因素均对模型的泛化能力构成考验。
常用场景
经典使用场景
在计算机视觉与食品科技交叉领域,该数据集为图像分类任务提供了标准化的基准。其精心标注的11类常见食品图像,如汉堡、披萨、寿司等,常被用于训练和评估卷积神经网络等深度学习模型。研究者通过该数据集验证模型在复杂食品纹理、颜色和形状上的识别能力,推动食品图像自动识别技术的进步。
解决学术问题
该数据集有效解决了食品图像细粒度分类中的标注一致性与类别平衡问题。学术界借助其标准化标注体系,能够系统探究跨文化食品的视觉特征差异,并为数据增强、迁移学习等算法提供验证平台。其意义在于降低了食品识别领域的研究门槛,促进了轻量级模型在边缘设备上的部署研究。
衍生相关工作
围绕该数据集衍生出多项经典研究工作,包括基于注意力机制的食品图像分类网络、跨域食品识别迁移学习框架等。部分研究进一步扩展了数据集的语义边界,构建了融合食材成分与烹饪方法的层次化标签体系。这些工作共同推动了食品计算领域的理论创新与技术标准化进程。
以上内容由遇见数据集搜集并总结生成


