zetavg/tw-sinica-corpus-word-frequency
收藏官方服务:
资源简介:
现代汉语词频统计数据集基于中央研究院现代汉语平衡语料库,包含500万词、20多万句、约14万笔词条的词频统计,并提供了各词汇的词性标记。数据集按照词频排序,并详细说明了每个字段的含义,包括序列编号、词频排序、词汇、词性、词频、词频百分比和累进词频百分比。此外,还列出了所有可能的词性标记及其对应的解释。
现代汉语词频统计数据集基于中央研究院现代汉语平衡语料库,包含500万词、20多万句、约14万笔词条的词频统计,并提供了各词汇的词性标记。数据集按照词频排序,并详细说明了每个字段的含义,包括序列编号、词频排序、词汇、词性、词频、词频百分比和累进词频百分比。此外,还列出了所有可能的词性标记及其对应的解释。
提供机构:
zetavg原始信息汇总
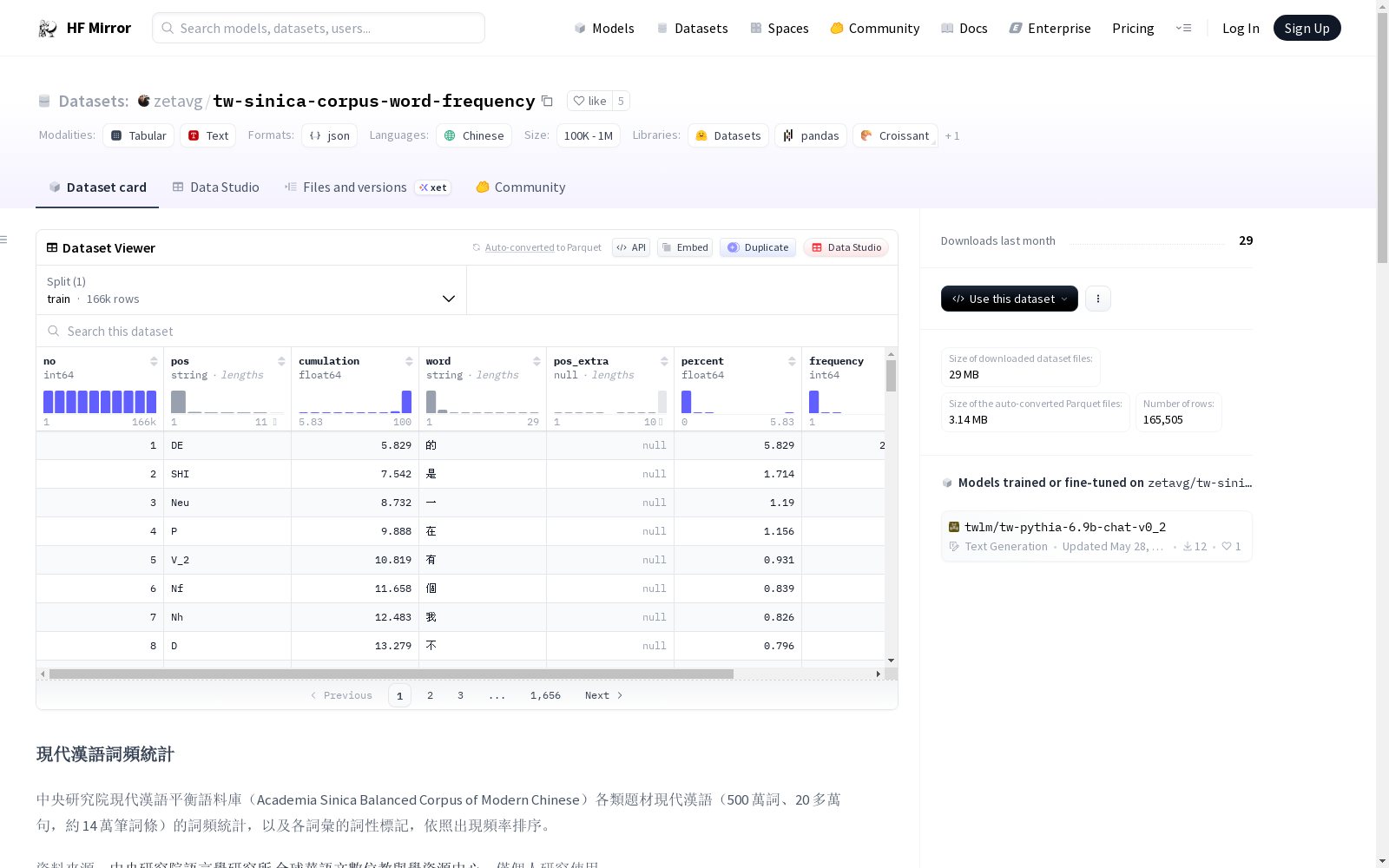
現代漢語詞頻統計
數據集概述
本數據集來自中央研究院現代漢語平衡語料庫,包含500萬詞、20多萬句,約14萬筆詞條的詞頻統計,以及各詞彙的詞性標記,依照出現頻率排序。
欄位說明
no— 序列編號rank— 詞頻統計排序word— 詞彙pos— 詞性,詳見下表frequency— 詞頻(出現次數)percent— 詞頻百分比cumulation— 累進詞頻百分比
詞性標記
A— 非謂形容詞D— 副詞Da— 數量副詞Dfa— 動詞前程度副詞Dfb— 動詞後程度副詞Dk— 句副詞Di— 時態標記Caa— 對等連接詞,如:和、跟Cbb— 關聯連接詞Nep— 指代定詞Neqa— 數量定詞Nes— 特指定詞Neu— 數詞定詞FW— 外文標記Nf— 量詞Na— 普通名詞Nb— 專有名稱Nc— 地方詞Ncd— 位置詞Nd— 時間詞Nh— 代名詞P— 介詞Cab— 連接詞,如:等等Cba— 連接詞,如:的話Neqb— 後置數量定詞Ng— 後置詞DE— 的, 之, 得, 地I— 感嘆詞T— 語助詞VA— 動作不及物動詞VB— 動作類及物動詞VH— 狀態不及物動詞VI— 狀態類及物動詞SHI— 是VAC— 動作使動動詞VC— 動作及物動詞VCL— 動作接地方賓語動詞VD— 雙賓動詞VE— 動作句賓動詞VF— 動作謂賓動詞VG— 分類動詞VHC— 狀態使動動詞VJ— 狀態及物動詞VK— 狀態句賓動詞VL— 狀態謂賓動詞V_2— 有Nv— 動詞名物化
搜集汇总
数据集介绍
构建方式
在语言资源构建领域,中央研究院现代汉语平衡语料库作为权威基础,本数据集以其为源,通过系统化处理流程生成。具体而言,研究团队对语料库中涵盖各类题材的500万词、20余万句现代汉语文本进行自动分词与词性标注,随后统计每个词汇的出现频率,并依据频率高低进行排序。这一过程不仅提取了原始语料中的词汇与词性信息,还计算了词频百分比及累进词频百分比,最终形成结构化的词频统计列表,确保了数据的准确性与代表性。
特点
本数据集的核心特点在于其全面性与精细化的标注体系。数据涵盖了约14万笔词条,每一条目均包含词汇、词性、频率及百分比等多维信息,并按照词频排序,便于用户快速定位高频词汇。尤为突出的是其详尽的词性标记系统,区分了数十种词性类别,如非谓形容词、各类动词及连接词等,为汉语词汇学研究提供了精细的语法视角。此外,数据源自学术机构的平衡语料库,保证了语言样本在题材与风格上的多样性,从而真实反映了现代汉语的实际使用状况。
使用方法
在自然语言处理与语言学研究实践中,本数据集可作为重要的基准资源。用户可直接通过序列编号或词频排序字段检索特定词汇,分析其使用频率与分布规律;结合词性标记,可深入探究不同语法类别词汇的出现模式,服务于词法分析、语言模型训练或教学资源开发。例如,在构建中文分词器或统计机器翻译系统时,可利用词频数据优化词汇表;语言教育者则可依据频率排序设计词汇教学顺序。数据以表格形式呈现,支持编程读取与进一步统计分析,但需注意仅限个人研究用途。
背景与挑战
背景概述
在计算语言学和中文信息处理领域,大规模、高质量的词汇资源是支撑自然语言理解与应用研究的基石。中央研究院现代汉语平衡语料库(Academia Sinica Balanced Corpus of Modern Chinese)作为一项重要的语言学基础设施,由台湾中央研究院语言学研究所构建,旨在提供覆盖多类题材的现代汉语代表性文本样本。该语料库收录了约500万词、20余万句,并从中提取出约14万笔词条,形成了详尽的词频统计与词性标注数据。其核心研究问题聚焦于精确刻画现代汉语的词汇使用分布与语法特征,为语言教学、词典编纂、信息检索及自然语言处理模型的训练与评估提供了不可或缺的实证依据,深刻影响了华语地区的语言学研究与人工智能应用发展。
当前挑战
该数据集所针对的核心领域问题是现代汉语词汇计量分析与语言资源建设,其首要挑战在于如何精准、全面地反映现代汉语的动态词汇体系与复杂语法结构,尤其是在处理多义词、兼类词以及新兴网络词汇时保持标注的一致性与准确性。在构建过程中,研究团队面临了语料平衡性设计的难题,需确保所选文本在题材、体裁、年代上的代表性,以规避样本偏差。同时,对海量原始语料进行自动分词与词性标注后,仍需投入大量人力进行人工校对与验证,以提升语言学标注的信度与效度,这一过程成本高昂且极具挑战性。
常用场景
经典使用场景
在自然语言处理领域,词频统计是语言建模与文本分析的基础环节。该数据集以其源自中央研究院现代汉语平衡语料库的权威性,为研究者提供了精确的现代汉语词汇分布图谱。其经典使用场景在于支撑统计语言模型的构建,例如在n-gram模型或隐马尔可夫模型中,作为核心参数估计的来源,用以预测词序列概率或进行词性标注的初始训练。
衍生相关工作
基于该数据集所奠定的词频基准,衍生出了一系列经典研究工作。例如,在词汇相似度计算与分布语义学研究中,常以此为基础构建共现矩阵。同时,它也为后续更细粒度的语料库建设(如领域语料库、历时语料库)提供了对比与参照的标尺,启发了针对社交媒体、学术文本等特定语体的词频统计分析,持续拓展着汉语计量研究的边界。
数据集最近研究
最新研究方向
在自然语言处理领域,基于中央研究院现代汉语平衡语料库的词频统计数据集,为语言模型训练与优化提供了关键资源。当前研究聚焦于利用该数据集的细粒度词性标注信息,探索汉语词汇的语义分布与句法功能关联,以提升预训练模型在中文语境下的理解能力。结合大规模语言模型的发展趋势,该数据集在词汇消歧、领域适应及语言生成任务中,为模型提供精准的频率先验知识,助力解决汉语特有的语言现象,如虚词用法和动词分类复杂性,从而推动中文信息处理技术的创新与应用。
以上内容由遇见数据集搜集并总结生成


