iejMac/CLIP-Kinetics700
收藏Hugging Face2022-07-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/iejMac/CLIP-Kinetics700
下载链接
链接失效反馈官方服务:
资源简介:
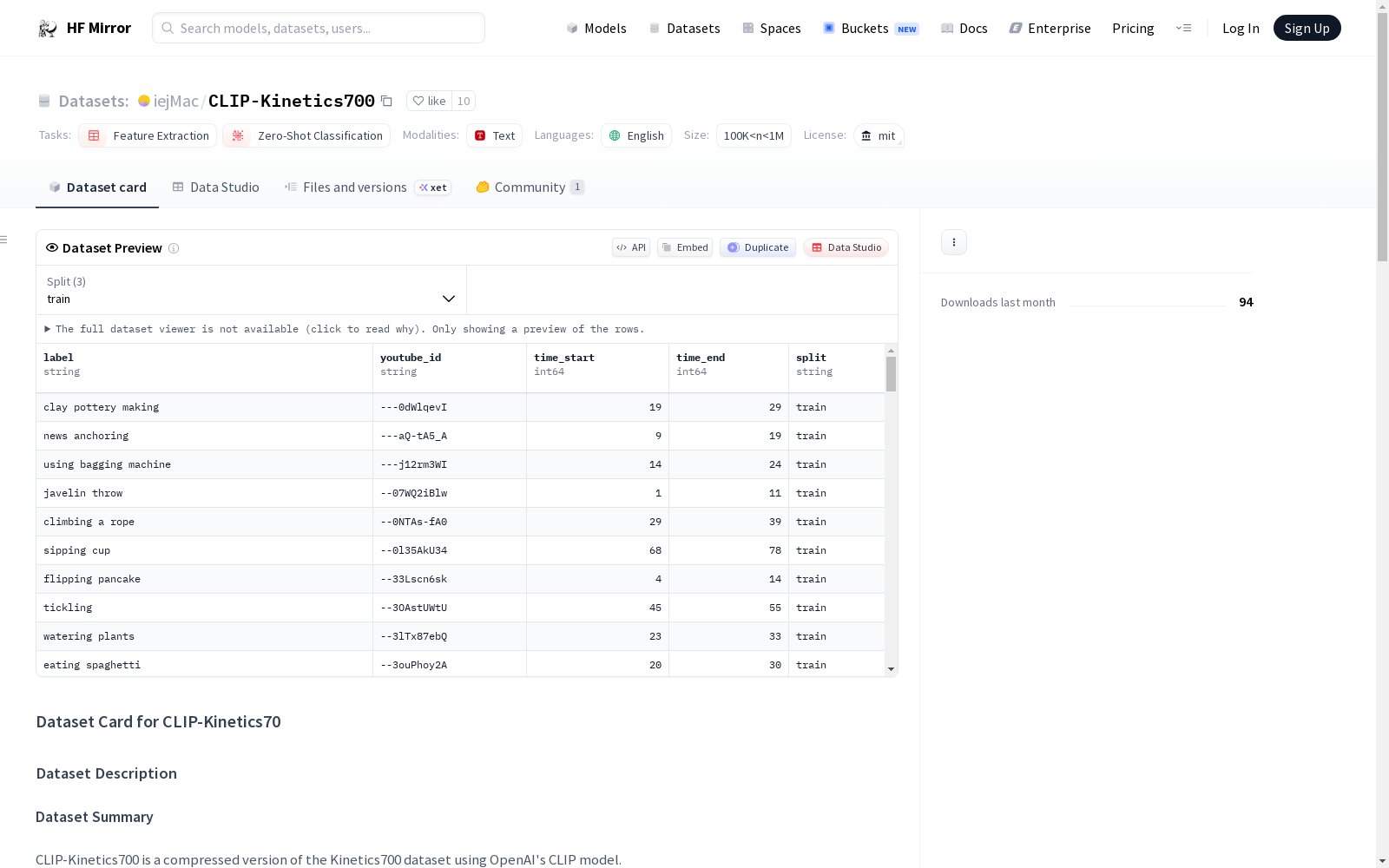
CLIP-Kinetics700是使用OpenAI的CLIP模型对Kinetics700数据集进行压缩的版本。原始数据集约为700 GB,难以在单台机器上使用和存储。通过将每个视频降采样到1 FPS并使用CLIP编码帧,数据集被压缩到约8 GB,使其非常内存友好且易于使用。数据集被格式化为WebDataset,以提高数据加载性能。每个分割包含一系列tar文件,每个文件包含10000个数据样本。数据字段包括每帧的嵌入(vid.npy)、视频的“标题”(vid.cap)以及额外的元数据(vid.json)。数据集分为训练集、验证集和测试集,分别包含536489、33966和64532个样本。
CLIP-Kinetics700 is a compressed version of the Kinetics700 dataset constructed using OpenAI's CLIP model. The original Kinetics700 dataset has an approximate size of 700 GB, which was too large to be utilized and stored on a single machine. By downsampling each video to 1 FPS and encoding its frames with CLIP, the dataset is compressed to roughly 8 GB, making it highly memory-efficient and easy to work with. The dataset is formatted as WebDataset to improve data loading performance. Each data split consists of a series of tar files, with each file containing 10,000 data samples. The data fields include per-frame embeddings (vid.npy), video captions (vid.cap), and additional metadata (vid.json). The dataset is divided into training, validation, and test sets, which contain 536,489, 33,966, and 64,532 samples respectively.
提供机构:
iejMac
原始信息汇总
CLIP-Kinetics700 数据集概述
数据集基本信息
- 名称: CLIP-Kinetics700
- 语言: 英语(en)
- 许可证: MIT
- 多语言性: 单语
- 大小: 100K<n<1M
- 任务类别: 特征提取、零样本分类
数据集描述
数据集总结
- 概述: CLIP-Kinetics700 是基于 OpenAI 的 CLIP 模型压缩的 Kinetics700 数据集版本。
- 原始数据集大小: 约 700 GB。
- 压缩后数据集大小: 约 8 GB。
- 压缩方法: 通过将视频下采样至 1 FPS 并使用 CLIP 编码帧。
数据集预处理
- 工具: 使用 clip-video-encode 生成嵌入。
数据集结构
数据格式
- 格式: WebDataset,每个分割包含多个 tar 文件,每个文件包含 10000 个数据样本。
数据字段
- vid.npy: 每帧嵌入的 numpy 数组,形状为 (n_frames, 512)。
- vid.cap: 视频标题,即 Kinetics700 标签。
- vid.json: 包含 YouTube 视频 ID、开始时间和结束时间的元数据。
数据分割
- 训练集: 536489 样本,54 tar 文件。
- 验证集: 33966 样本,4 tar 文件。
- 测试集: 64532 样本,7 tar 文件。
数据集创建
源数据
- 来源: DeepMind 的 Kinetics700 数据集。
- 下载工具: 使用 cvdfoundation/kinetics-dataset 仓库。
简单实验
零样本评估
- 评估方法: 使用 temporal-embedding-aggregation 进行评估。
- 评估结果:
- Top-1 准确率: 0.31
- Top-5 准确率: 0.56
- 平均准确率: 0.44
线性探针评估
- 评估方法: 使用 temporal-embedding-aggregation 进行评估。
- 评估结果:
- Top-1 准确率: 0.41
- Top-5 准确率: 0.65
- 平均准确率: 0.53
搜集汇总
数据集介绍
背景与挑战
背景概述
CLIP-Kinetics700是Kinetics700数据集的压缩版本,使用CLIP模型将原始数据从700GB压缩至8GB,便于存储和使用。数据集包含训练、验证和测试分割,适用于特征提取和零样本分类任务,采用WebDataset格式和MIT许可证。
以上内容由遇见数据集搜集并总结生成


